
Multimodal Learning 소개
( 참고 : http://dmqm.korea.ac.kr/activity/seminar/272 )
Multimodal (Deep) Learning에 대해 간단히 소개하는 글
1. Introduction
(1) Multimodal Learning이란?
- 인간의 “5가지 감각기관”으로 부터 수집되는 다양한 형태(modality)의 데이터를 사용하여 모델을 학습하는 것
- 5가지 Modality :
- Vision / Text / Speech / Touch / Smell / (+ Meta data)
-
'’변수가 많다” \(\neq\) Multimodal
( 변수들의 차원이 달라야한다! )
-
expression :
- single-modal : \(y=f(X_n^p)\)
- multi-modal : \(y=f(X_{term}^{doc},X_{x,y}^{color}, X_{time}^{voice}, X_{time}^{sensor} )\)
-
Key Point :
어떻게 특징 차원이 다른 데이터를 “동시”에 잘 학습할 수 있을까?
\(\rightarrow\) 각각의 데이터의 특성을 “잘 통합하는 것”에 있다!
2. Multimodal Learning의 구분
Multimodal Learning은 “여러 source의 데이터를 통합하는 방식”에 따라 구분할 수 있다.
(1) 데이터 차원의 통합
-
다른 특성의 데이터를 embedding하여 특성이 같은 데이터로 추출
-
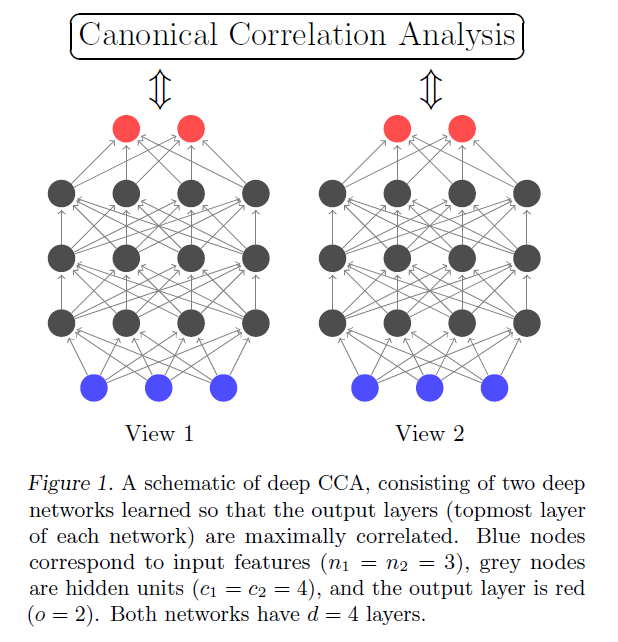
ex) Deep CCA (Deep Canonical Correlation Analysis)
( Andrew, Galen, et al. “Deep canonical correlation analysis.” International conference on machine learning. PMLR, 2013. )
Deep CCA
- method to learn complex nonlinear transformations of two views of data such that the resulting representations are highly linearly correlated.
- can be viewed as a nonlinear extension of the linear method canonical correlation analysis (CCA).
- two parameters are jointly learned to maximize the total correlation
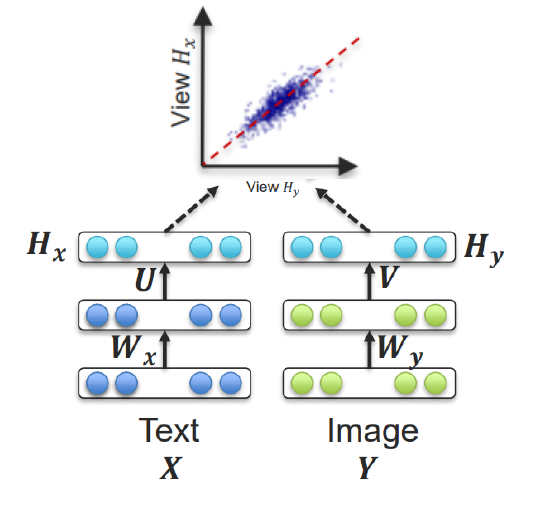
- \(\left(\boldsymbol{u}^{*}, \boldsymbol{v}^{*}\right)=\underset{\boldsymbol{u}, v}{\operatorname{argmax}} \operatorname{corr}\left(\boldsymbol{u}^{T} \boldsymbol{X}, \boldsymbol{v}^{T} \boldsymbol{Y}\right)\).
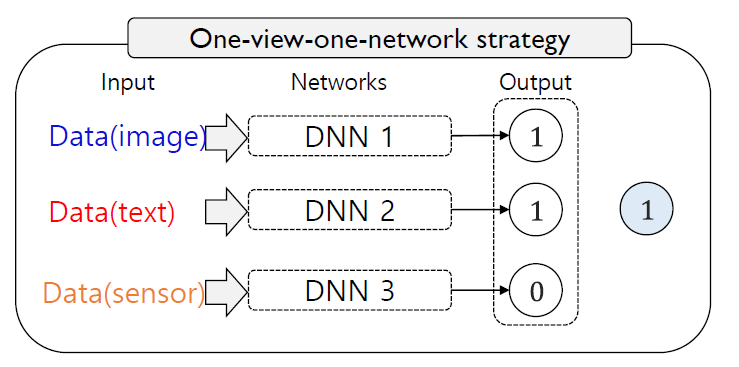
(2) Model의 통합
- 각기 다른 모델의 예측값을 통합 ( Co-training, Ensemble )
-
( 각각의 모델은 다른 가중치를 가지고 통합된다 )
\(P\left(\hat{Y}_{j}=c \mid I_{j}\right)=\sum_{\phi \in\{\text{text},\text{speech},\text{vision}\}} \gamma_{\phi} P_{\phi}\left(\hat{Y}_{j}=c \mid I_{j} ; \theta_{\phi}\right)\).
- \(\gamma\) : 가중치
(3) Embedding vector의 통합
- 각각의 데이터는 각자의 NN을 통해 학습된 뒤, 거기서 추출된 embedding vector를 (선형) 결합한다
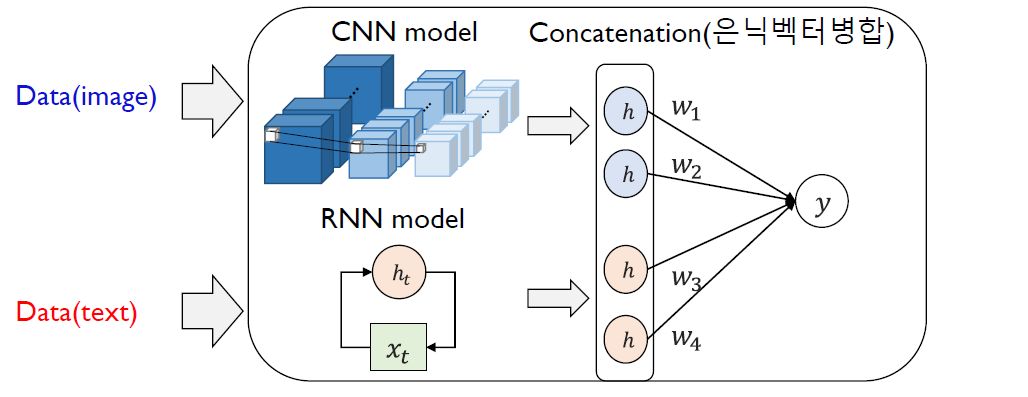
Example)
- Multimodal CNN (m-CNN)
- Multimodal RNN (m-RNN)
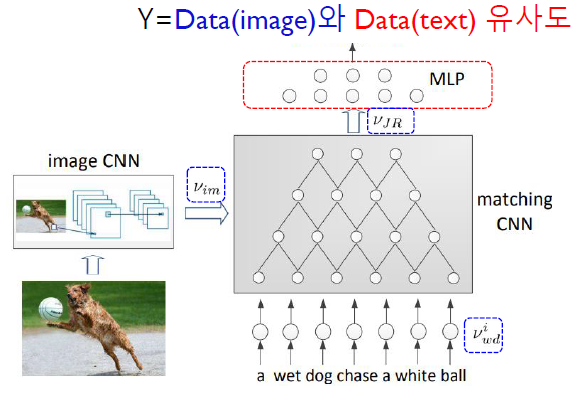
m-CNN (Ma et al,2015)
-
목적 : image & text의 관계 (matching 정도) 파악
-
두 가지 main 신경망
-
1) image/text의 특징을 concatenate을 하는 NN
\(\mathbf{v}=v_{w d}^{i}\left\|v_{w d}^{i+1}\right\| \cdots\left\|v_{w d}^{i+k_{r p}-1}\right\| v_{i m}\).
-
2) concatenate된 vector로써 최종 예측을 하는 NN
\(s_{\text {match }}=w_{s}\left(\sigma\left(w_{h}\right)\left(v_{J R}\right)+b_{h}\right)+b_{s}\).
-
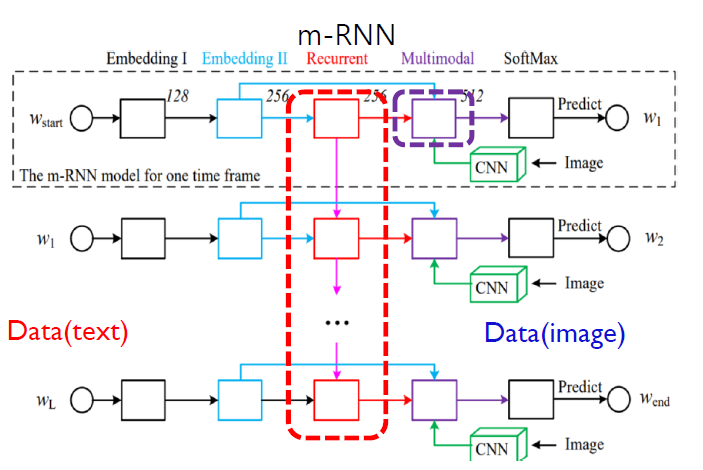
m-RNN (Mao et al,2014)
- 목적 : image와 관련된 text를 생성
- 두 가지 main 신경망
- 1) 시계얼 특성을 파악하는 NN (아래의 purple 상자)
- 2) image/text의 특징을 concatenate하는 NN (아래의 red 상자)
3. Challenges of Multimodal Learning
(1) Representation
-
multimodal data를 어떻게 잘 요약(축약)할 것인지!
-
잘 축약했다?
- 축약된 서로 다른 데이터가 “highly correlated”
-
두 가지 방법
-
joint representation ) 두 data가 합쳐진 뒤 하나의 representation으로!
-
coordinated representation ) 두 data가 각각 축약된 뒤, 이들을 서로 concatenate
ex) Deep CCA ( 위에 참조 )
-
(2) Translation
- entity를 “다른 modality”의 entity로 변환(생성)
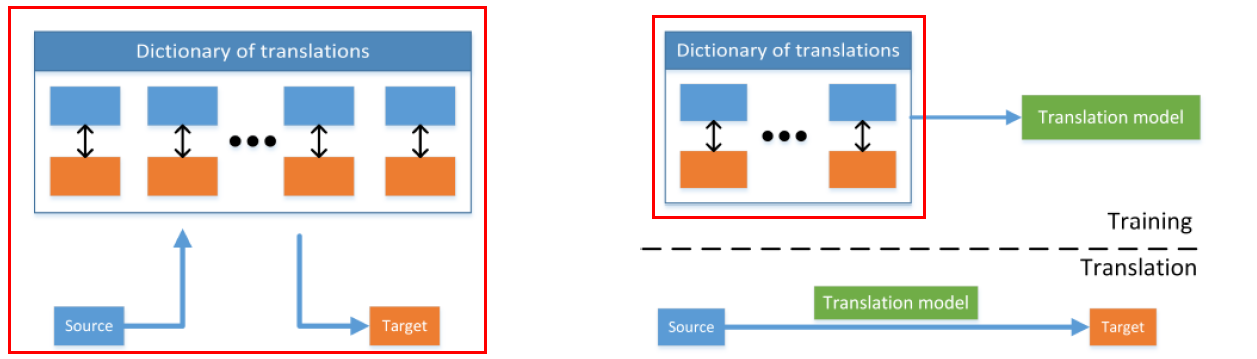
(3) Alignment
- 서로 다른 modality의 데이터의 관계를 파악!
(4) Fusion
- 서로 다른 modality의 데이터를 잘 결합하여 예측을 수행하는 것!
(5) Co-learning
-
knowledge가 부족한 특정 modality의 데이터를,
knowledge가 풍부한 다른 modality의 데이터를 사용하여 보완하는 것!