
( 참고 : Fastcampus 강의 )
[ 19. SARSA ( = TD Control ) 실습 ]
1. 복습
(1) N-step TD

(2) N-step SARSA

(3) SARSA(\(\lambda\))
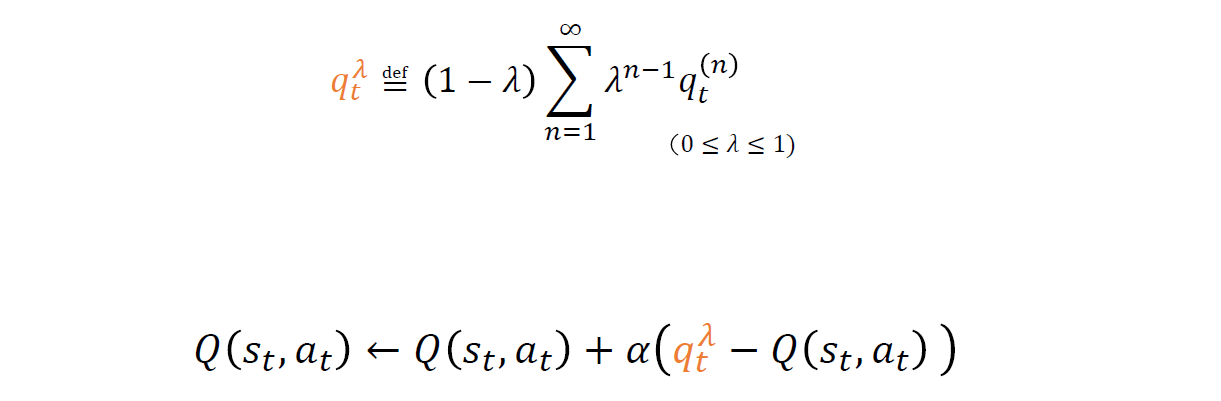
2. Agent 생성
sarsa_agent = SARSA(gamma=1.0,
lr=1e-1,
num_states=env.nS,
num_actions=env.nA,
epsilon=1.0)
3. SARSA Update 식
\(Q(s, a) \leftarrow Q(s, a)+\alpha\left(r+\gamma Q\left(s^{\prime}, a^{\prime}\right)-Q(s, a)\right)\).
def update_sample(self, s, a, r, s_, a_, done):
td_target = r + self.gamma * self.q[s_, a_] * (1 - done)
self.q[s, a] += self.lr * (td_target - self.q[s, a])
4. Run Iteration
episode 횟수 : 10,000 ( 출력 로그 간격 : 1,000)
num_episode = 10000
print_log = 1000
sarsa_qs = []
iter_idx = []
sarsa_rewards = []
for i in range(num_episode):
total_reward = 0
env.reset()
while True:
# (1) state 관찰 -> (2) action -> (3) reward,다음 state 받기
s = env.s
a = sarsa_agent.get_action(s)
s_, r, done, info = env.step(a)
# (4) 다음 state에 맞는 action
a_ = sarsa_agent.get_action(s_)
# (5) 앞에서 얻게 된 s,a,r,s_,a_로 update하기
sarsa_agent.update_sample(state=s,
action=a,
reward=r,
next_state=s_,
next_action=a_,
done=done)
total_reward += r
if done:
break
sarsa_rewards.append(total_reward)
if i % print_log == 0:
print("Running {} th episode".format(i))
print("Reward sum : {}".format(total_reward))
sarsa_qs.append(sarsa_agent.q.copy())
iter_idx.append(i)