
Multi-Task Time Series Forecasting with Shared Attention (2021)
Contents
- Abstract
- Introduction
- Related Works
- Shared-Private Attention Sharing scheme
- Task Definition
- Preliminary Exploration
- General Global shared Attention
- Hybrid Local-global Shared Attention
0. Abstract
-
most of existing methods : SINGLE-task forecasting problem
-
Transformer : can catch LONG term dependency
\(\rightarrow\) propose two self-attention based sharing schemes for multi-task time series forecasting,
which can train jointly across multiple tasks
( augment (1) Transformer + (2) external public multi-head attention )
1. Introduction
[1] Traditional time series
- ARIMA
- VAR (Vector Auto-regression)
- SVR
- DNNs
- RNNs
- LSTM
- GRU
[2] Meta multi-task learning
- proposed a new sharing scheme of composition function across multiple tasks
[3] Transformer
- capture long term dependency
Most of works focus on single-task learning, or combining multi-task learning with RNN
Thus, this paper proposes…
- bridge the gap between
- 1) multi-task learning
- 2) Transformer attention-based architecture
- jointly train on multiple related tasks
Summary
- 1) first to propose an attention-based multi-task learning framework ( MTL-Trans )
- 2) propose 2 different attention sharing architectures
- 3) conduct extensive experiments
2. Related Works
- Time Series Forecasting
- Transformer framework
- Multi-task Learning
Transformer
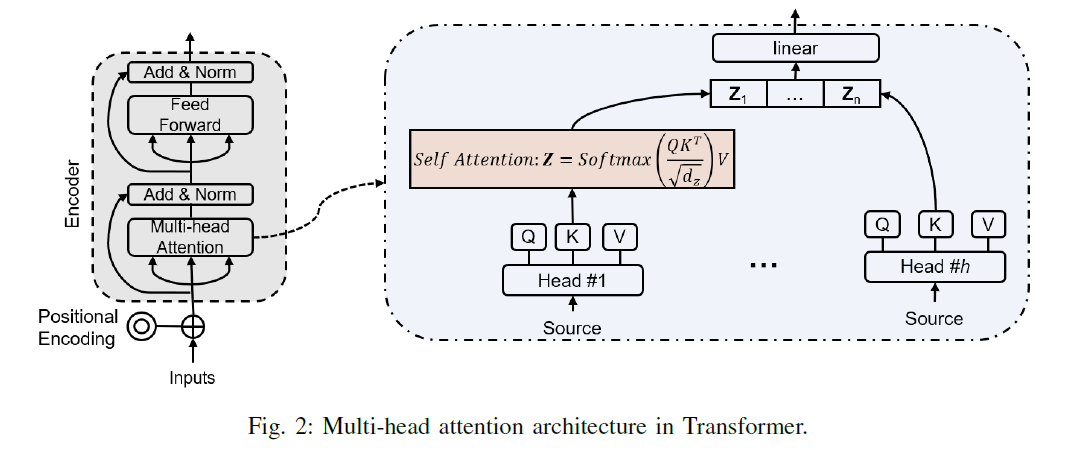
3. Shared-Private Attention Sharing scheme
(1) Task Definition
focus on single-step forecasting
Notation
-
dataset : \(\mathcal{D}= \left\{ \left\{\mathbf{x}_{m n}, \mathbf{y}_{m n}\right\} \mid _{n=1} ^{N_{m}}\right\} \mid _{m=1} ^{M}\)with multiple sequence tasks
- \(M\) : number of tasks
- \(N_{m}\) : number of instances in \(m\)-th task
- \(\mathbf{x}_{m n}\) : \(n\) th sample in \(m\)-th task
- \(\mathbf{x}_{m n}=\left\{x_{m n}^{t_{1}}, \ldots, x_{m n}^{t_{s}}\right\}\) : historical observation values with length \(s\)
- \(\mathbf{y}_{m n}=\left\{y_{m n}^{t_{2}}, \ldots, y_{m n}^{t_{s+1}}\right\}\) : future t.s sequence with the same length \(s\) corresponding to \(\mathbf{x}_{m n}\)
-
goal : learn a function that maps…
-
\(\left\{ \mathbf{x}_{m n} \mid _{n=1} ^{N_{m}}\right\} \mid _{m=1} ^{M}\) \(\rightarrow\) \(\left\{ \mathbf{y}_{m n} \mid _{n=1} ^{N_{m}}\right\} \mid _{m=1} ^{M}\)…. “JOINTLY”
by using the latent similarities among tasks, based on MULTI-task learning
-
(2) Preliminary Exploration
-
1) scaled dot-production attention (생략)
-
2) multi-head attention (생략)
-
3) masking self-attention head (생략)
-
4) shared-private attention scheme
-
main challenge = how to design the sharing scheme?
-
in this paper… provide a shared attention model, MTL-Trans among multiple tasks,
based on Transformer with two different sharing schemes!
-
2가지의 sharing schemes
- General Global shared Attention
- Hybrid Local-global Shared Attention
(3) General Global shared Attention
기존 Transformer의 2가지 attention
- attention 1) self-attention
- attention 2) encoder-decoder attention
이 논문에서는 attention 1) self-attention 만을 사용함
General Global shared Attention
- a) private (task-specific) attention layer
- b) shared (task-invariant) attention layer
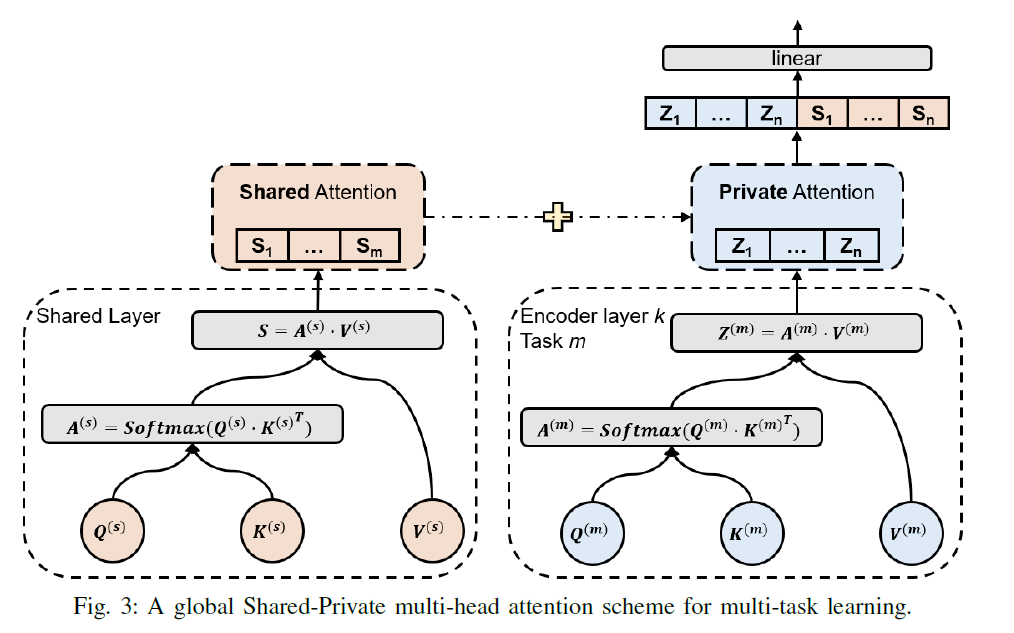
Algorithm
- (input) \(\mathbf{x}^{(m)}=\left(x_{1}, x_{2}, \cdots, x_{n}\right)\) from a random selected task
- (“shared attention” information output)
- \(\mathbf{s}^{(m)}=\text { MultiheadAttention }_{\text {shared }}\left(\mathbf{x}^{(m)}\right)\).
- \(\mathbf{s}^{(m)}=\left(s_{1}, s_{2}, \cdots, s_{n}\right)\), where \(s_{i} \in \mathcal{R}^{d_{s}}\)
- (“task specific” attention output)
- \(\mathbf{z}_{k}^{(m)}=\text { MultiheadAttention }_{k}\left(\mathbf{z}_{k-1}^{(m)}\right)\).
- \(\mathbf{z}_{k}^{(m)}=\left(z_{1}, z_{2}, \cdots, z_{n}\right)\), where \(\mathbf{z}_{k-1}^{(m)}\) is the output of the \((k-1)\) th encoder from task \(m\).
- (attention output from \(k\)th encoder layer)
- \(\mathbf{z}_{k}^{(m)}=\left[\begin{array}{c} \mathbf{z}_{k}^{(m)} \\ \mathbf{s}^{(m)} \end{array}\right]^{T} W^{O}\). where \(W^{O} \in \mathcal{R}^{\left(d_{s}+d_{z}\right) \times d_{z}}\)
(4) Hybrid Local-global Shared Attention
can make all tasks share a global attention memory & record task-specific information besides shared information
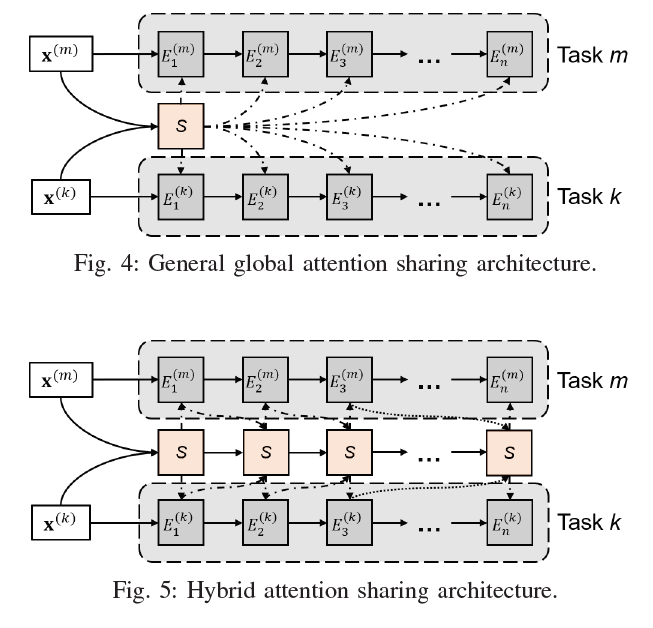
-
given an output sequence \(\mathbf{z}_{k}^{(m)}=\) \(\left(z_{1}, z_{2}, \cdots, z_{n}\right)\) from the \(k\) th encoder layer for task \(m\),
this will be fed back into shared multi-head attention layer
\(\mathbf{s}_{\text {updated }}^{(m)}=\text { MultiheadAttention }_{\text {shared }}\left(\mathbf{z}_{k}^{(m)}\right)\).
-
“shared attention values” and “private outputs” … concatenated, and
fed into next encoder layer
\(\mathbf{z}_{k+1}^{(m)}=\text { MultiheadAttention }_{k+1}\left(\left[\begin{array}{c} \mathbf{z}_{k}^{(m)} \\ \mathbf{s}_{\text {updated }}^{(m)} \end{array}\right]\right)\).
-
by recurrently feeding outputs… enhance the capacity of memorizing