Neural Acoustic Feature Extraction
참고 : https://ratsgo.github.io/speechbook/docs/neuralfe
1. Introduction
NAF vs. MFCCs
-
Neural Acoustic Feature Extraction : NN(learning)-based \(\rightarrow\) stochastic
-
MFCCs : rule-based \(\rightarrow\) deterministic
Two algorithms:
- (1) Wave2Vec
- key idea: Similarity ( 현재 음성 프레임, 다음 음성 프레임 ) \(\uparrow\)
- (2) SincNet
- key idea: 새로운 CNN 계열 구조
- (3) PASE (Problem-Agnostic Speech Encoder)
- based on Sincnet
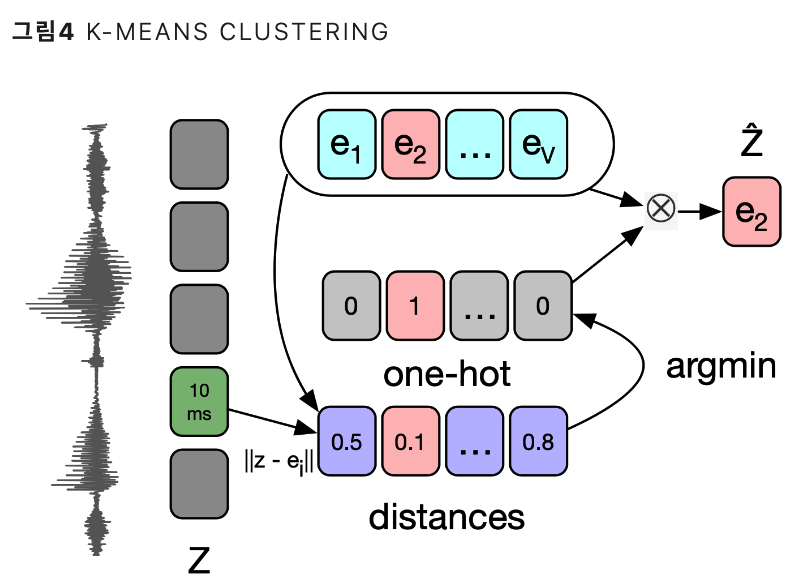
2. Wav2Vec
Architecture
( 둘 다 CNN 기반 )
- \(f\) : encoder
- \(g\) : context network
Task : binary classificaiton
- predict pos/negative pair
- positive = adjacent representation
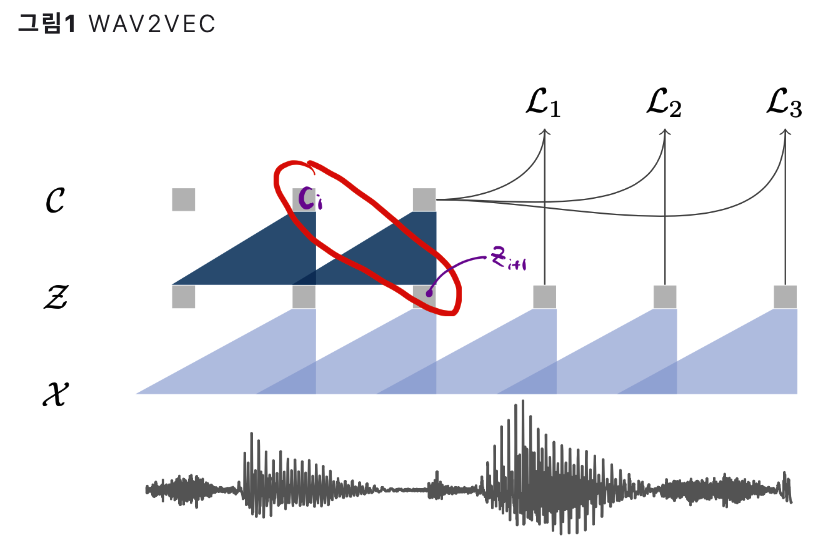
3. VQ-Wav2Vec
Wav2Vec + Vector Quantization
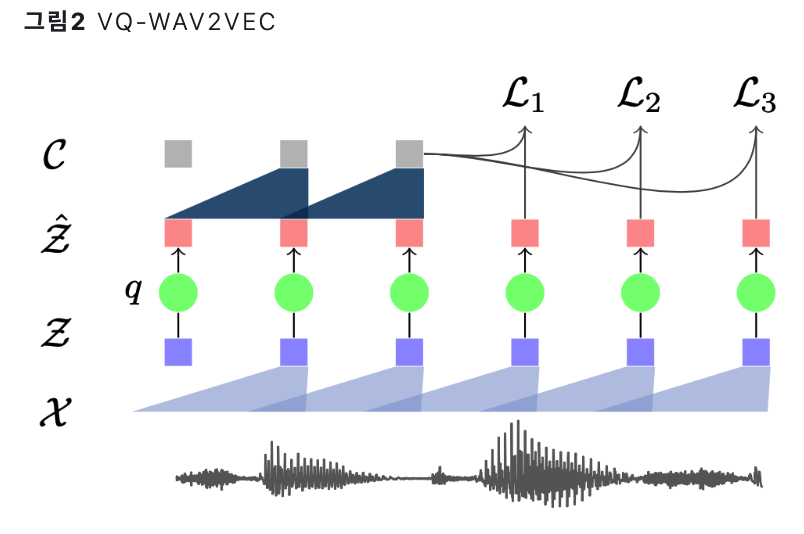
방법 1) Vector Quantization
Vector Quantization with Gumbel Softmax
- step 1) calculate embedding \(\mathcal{Z}\)
- step 2)
linear(\(\mathcal{Z}\)) … logits - step 3)
OHencode(linear(\(\mathcal{Z}\)) )
step 4) \(E \mathcal{Z}\) …… \(E\): embedding matrix
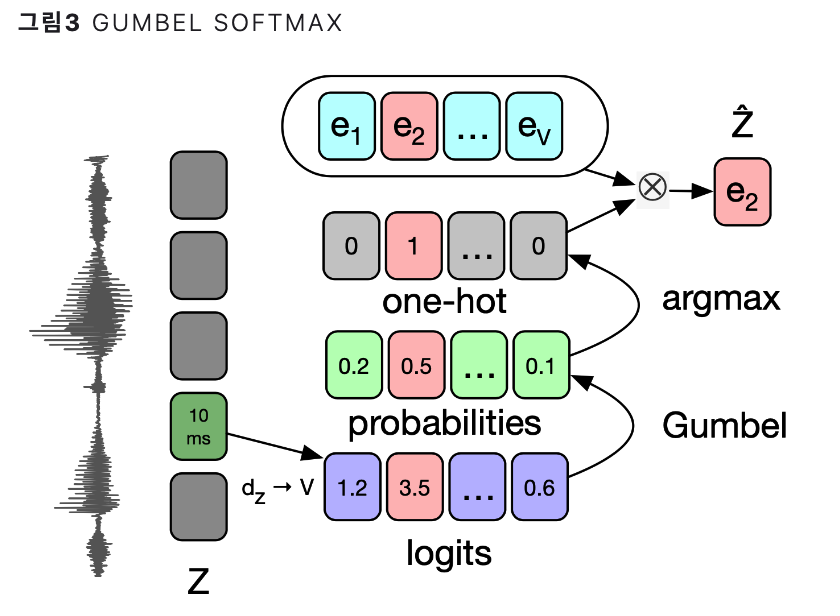
방법 2) K-means Clustering
Distance btw \(E\) and \(Z\)
\(\rightarrow\) 가장 가까운 \(E\) 벡터를 하나 선택