
Continual Learning
Continual Learning에 대해 간단히 소개하는 글
Contents
- Introduction
- 등장 배경
- Continual Learning (연속 학습)
- Multi-task Learning
- Online Learning
- 접근 방법
- Regularization
- Structure
- Memory
1. Introduction
인간은 어렸을때 배운 것을, 나이가 들어서도 복습하지 않고도 잘 까먹지 않는다. 예를 들면, 어렸을때 배운 자전거 타는 방법이든, 젓가락질 하는 방법이든, 아주 예전에 배운 뒤 따로 학습하지 않아도 해당 지식을 잘 기억하고 있다. 이에 반해, 우리가 학습시키는 DL 모델들은 그러지 않은 경우가 많다.
우리 인간과 마찬가지로, “한번 학습한 것은 잘 까먹지 않도록” 하는 모델을 만드는 것이 바로 Continual Learning이다!
Continual Learning is a concept to learn a model for a large number of tasks sequentially without forgetting knowledge obtained from the preceding tasks, where the data in the old tasks are not available any more during training new ones. ( PaperswithCode )
2. 등장 배경
Transfer Learning (전이 학습)은, 이전에 어떠한 task를 풀기 위해 학습했던 모델의 weight를, 다른 task를 풀기 위해 학습시킬 예정인 모델의 initial weight로써 활용하는 학습 방법을 말한다. 이는 새로운 모델의 학습을 보다 빠르게 학습시키고 우수한 성능을 가지게끔 한다. 하지만 이 방법의 한계점은, “과거에 학습했던 내용을 잊어버린다”는 점이다. 이와 관련하여 아래의 2가지 큰 문제들이 존재한다.
- 파괴적 망각 (Catastrophic Forgetting)
- 의미 변화 (Semantic Drift)
(1) Catastrophic Forgetting
( 기존 task : task A, 신규 task : task B )
task A를 풀기 위한 모델을 만든 뒤, 이를 task B를 풀기 위한 모델로써 전이를 하게 되면, 이전 task인 task A는 더이상 잘 풀지 못하게 되는데, 이를 “파괴적 망각(Catastrophic Forgetting)”이라 한다. ( 이전 dataset에 대한 정보 손실 불가피 )
(2) Semantic Drift
task B를 학습하면서 pre-trained weight는 변하게 된다. 이 변화가 크게 발생하게 된다면, 이전의 모델에서 가지던 weight의 의미는 더이상 존재하지 않게 된다. 예를 들면, 특정 layer 혹은 node가 사람의 얼굴과 관련된 정보를 담고 있었는데, weight가 변화된 이후로는 강아지의 몸통을 담는 의미를 가지게 될 수도 있다.
3. Continual Learning (연속 학습)
( Continual Learning(연속 학습)은 Lifelong Learning(평생 학습)이라고도 부른다 )
위의 두 문제점 (1) Catastrophic Forgetting & (2) Semantic Drift를 해결하고자 나온 방법론으로써, 아래와 같은 2가지 특징이 있다.
(1) Multi-task Learning
-
하나의 모델로 여러 개의 task를 풀고자 함
-
task A를 푸는 모델 (가), task B를 풀고자 하는 모델 (나)를 각각 따로 학습하는 것은 비효율적!
따라서, task A,B를 한번에 풀 수 있는 모델 (다)를 학습시킨다!
(2) Online Learning
- 계속해서 유입되는 데이터를 기존의 모델에 반영하여 파라미터를 update!
- 모든 Task들이 동시에 들어오지는 않는다. 새로운 Task가 들어올 때마다, 매번 전체 dataset으로 모델을 다시 학습시키는 것은 너무 비효율적이기 때문에, 순차적으로 유입되는 데이터를 계속 기존의 모델에 편입시켜서 모델을 변화시키는 방향으로 학습을 시켜야 한다!
4. 접근 방법
Continual Learning에는 다음과 같은 3가지의 접근 방법이 있다.
- 1) Regularization
- 2) Structure
- 3) Memory
(1) Regularization
기존 task를 푸는데에 있어서, NN의 weight들이 성능 개선이 기여한 정도에 따라 weight update를 제한하는 방법
( 중요한 역할을 했던 weight : semantic drift가 발생하지 않도록 한다 )
ex) Elastic Weight Consolidation
Elastic Weight Consolidation (EWC)
-
probabilistic approach
-
weight가 중요하다/중요하지 않다?
-
posterior probability , \(p(\theta \mid D)\)
( \(\theta\) : weight, \(D\) : 기존 task의 dataset )
-
\(\begin{aligned} \log p(\theta \mid D) &=\log p(D \mid \theta)+\log p(\theta)-\log p(D) \\ &=\log p\left(D_{B} \mid \theta\right)+\log p\left(\theta \mid D_{A}\right)-\log p\left(D_{B}\right) \end{aligned}\).
-
-
true posterior는 intractable하기 때문에, Laplace Approximation을 사용하여 Gaussian으로 근사한다. ( mean params : \(\theta_{A}^{*}\) )
-
아래 식과 같이 Fisher Information matrix가 붙은 penalty term을 loss function에 넣어서 regularize한다.
- \(\mathcal{L}(\theta)=\mathcal{L}_{B}(\theta)+\sum_{i} \frac{\lambda}{2} F_{i}\left(\theta_{i}-\theta_{A, i}^{*}\right)^{2}\).
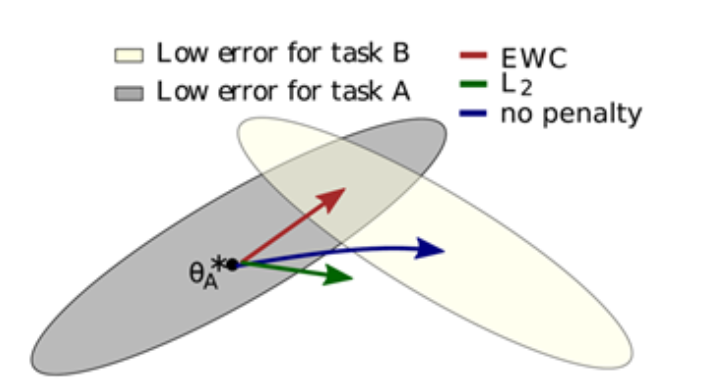
no-penalty, L2 penalty, EWC 세 가지 방법의 비교 결과 :
(2) Structure
NN의 Structure를 동적으로 변경
( = node/layer를 추가하여 새로운 task를 위한 parameter 추가 )
ex) Progressive Network
Progressive Network
Transfer Learning vs Progressive Networks
-
Transfer Learning : pre-trained weight를 새로운 task를 위한 모델의 initial weight로 설정
-
Progressive Networks : pre-trained weight를 그대로 사용! 대신 추가로 layer/node를 추가하여 구조를 변경 (=Sub network)
( Sub network는 오로지 새로운 task만을 위해서만 사용 )
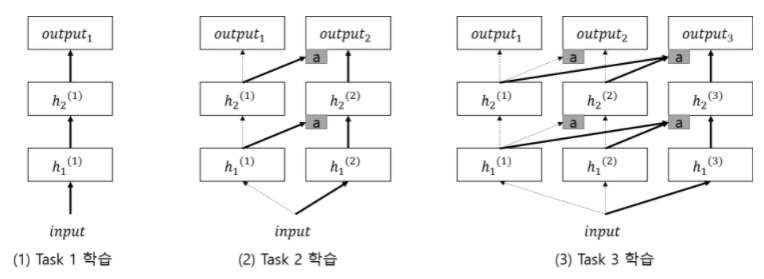
(사진 1 ) Task 1를 위한 일반적인 NN
(사진 2 ) Task 2를 위한 Sub network를 추가!
- 기존 NN의 weight는 고정 ( 위 그림에서 점선 ) \(\rightarrow\) Catastrophic Forgetting 해결 위해
- Lateral Connection (측면 연결) : 기존 NN의 weight를 Sub network에 연결하는 것
(사진 3 ) Task 3
- 마찬가지~
요약 :
-
1) 새로운 NN(=Sub network)를 추가함으로써 Catastrophic forgetting 문제 해결 ( 기존 task도 여전히 잘 풀 수 있다! )
-
2) Lateral Connection 통해 이전 task에 학습된 정보 전달 가능 ( Knowledge Transfer가 잘 이루어짐 )
(3) Memory
생물학적인 기억 메커니즘을 모방하자는 아이디어에서 출발
ex) Deep Generative Replay
Deep Generative Replay (DGR)
- 뇌의 해마를 모방하여 만든 알고리즘
- 해마 : 뇌에 들어온 정보를 “단기간 저장”한 뒤, 일부는 “장기 기억”으로, 일부는 “삭제”
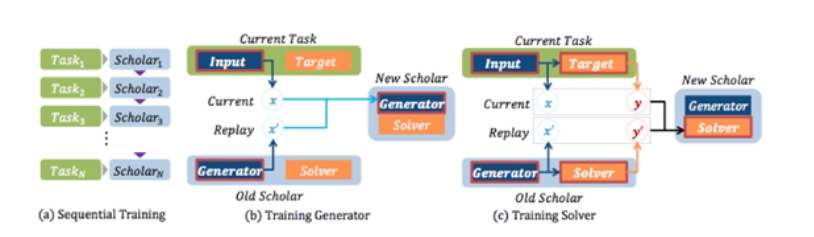
- Generator & Solver
(1) Generator
- GAN을 기반으로 함
- 유사한 데이터를 재현 ( 여러 task의 input data를 기억 )
- 단기기억과 같은 역할을 함
(2) Solver
-
(기존 task A, 신규 task B)
-
task B를 학습할 때, Generator를 통해 재현된 task A 데이터를, task B의 데이터와 함께 사용하여 학습
( = Multi-task 가능해짐 )
-
Scholar 모델이라고도 불림
-
장기기억과 같은 역할을 함
Reference
-
Overcoming catastrophic forgetting in neural networks ( J Kirkpatrick, et al. , 2016 )
-
Progressive Neural Networks ( AA Rusu et al., 2016 )
-
Continual Learning with Deep Generative Replay (Shin, et al. , 2017)
-
https://ralblack0.github.io/2020/03/22/lifelong-learning.html
-
https://mambo-coding-note.tistory.com/476