
( 참고 : 패스트 캠퍼스 , 한번에 끝내는 컴퓨터비전 초격차 패키지 )
01.Image Classification
0. Task
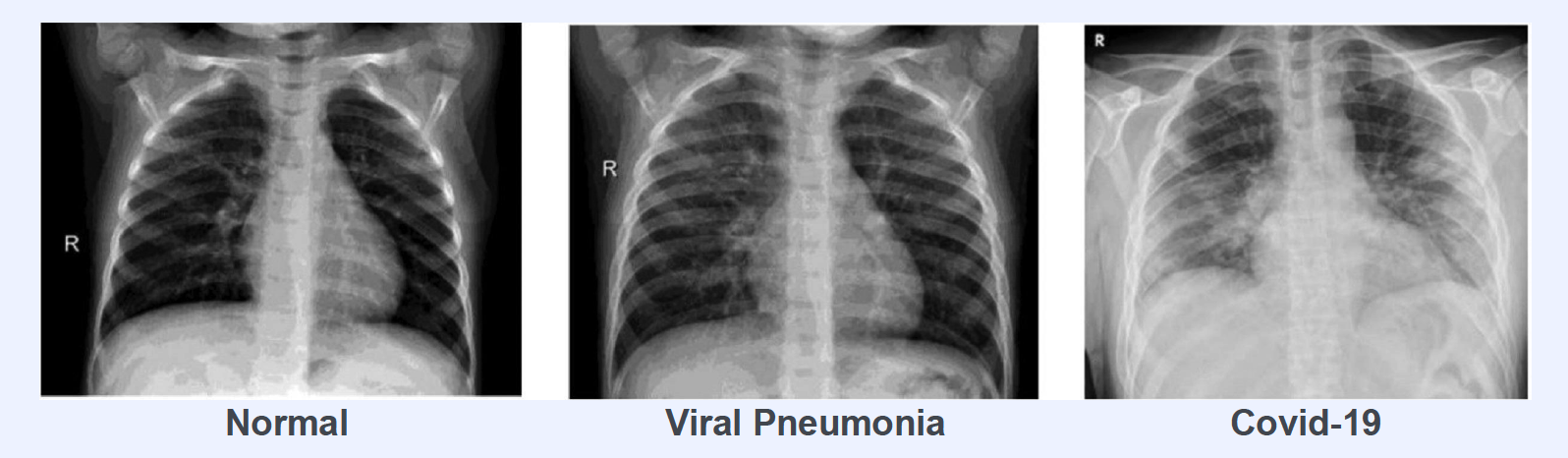
Image Classification with Covid Chest-Xray Images
- label : (1) normal / (2) covid / (3) viral pneumonia
1. Import Packages
import os
import copy
import random
import cv2
import torch
import numpy as np
from torch import nn
from torchvision import transforms, models
from torch.utils.data import Dataset, DataLoader
import matplotlib.pyplot as plt
from ipywidgets import interact
For Deterministic Output,
\(\rightarrow\) Set random seed
random_seed = 2022
random.seed(random_seed)
np.random.seed(random_seed)
torch.manual_seed(random_seed)
torch.cuda.manual_seed(random_seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
2. Import Datasets
Functions to import image files
def list_image_files(data_dir, sub_dir, image_format):
images_dir = os.path.join(data_dir, sub_dir)
image_files = []
for file_path in os.listdir(images_dir):
if file_path.split(".")[-1] in image_format:
image_files.append(os.path.join(sub_dir, file_path))
return image_files
Import datasets
- images have 3 types of formats : (jpeg, jpg, png)
data_dir = "../DATASET/Classification/train/"
image_format = ["jpeg", "jpg", "png"]
normals_list = list_image_files(data_dir, "Normal")
covids_list = list_image_files(data_dir, "Covid")
pneumonias_list = list_image_files(data_dir, "Viral Pneumonia")
3. Image File \(\rightarrow\) 3d RGB array
Function
cv2.imread: read image filescv2.cvtColor(xxx, cv2.COLOR_BGR2RGB): convert colors- from BGR -> RGB
def get_RGB_image(data_dir, file_name):
image_file = os.path.join(data_dir, file_name)
image = cv2.imread(image_file)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
return image
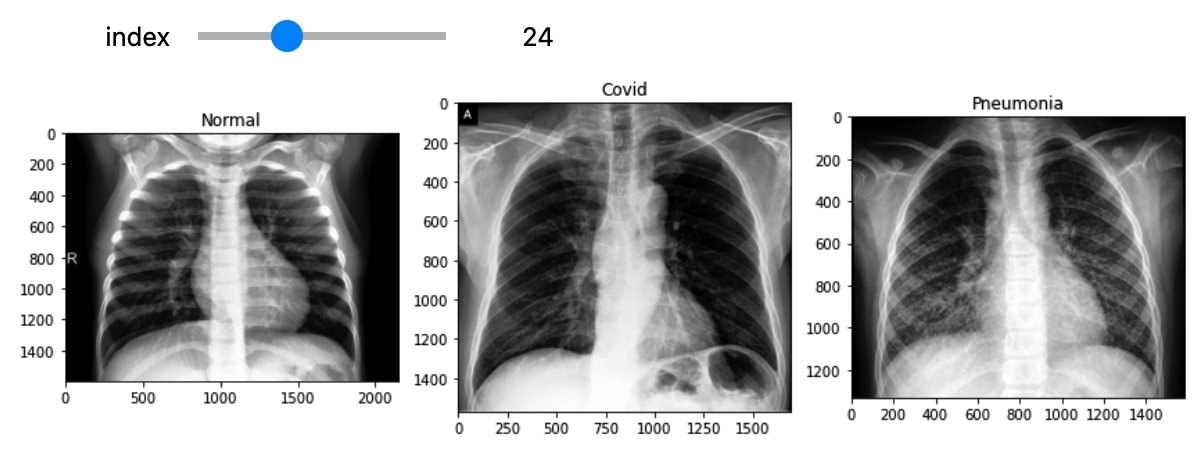
4. Visualize Images
Compare three types of classes at one image! ( subplot )
min_num_files = min(len(normals_list), len(covids_list), len(pneumonias_list))
Visualize interactively! ( with slide bar )
- use
@interact
@interact(index=(0, min_num_files-1))
def show_samples(index=0):
normal_image = get_RGB_image(data_dir, normals_list[index])
covid_image = get_RGB_image(data_dir, covids_list[index])
pneumonia_image = get_RGB_image(data_dir, pneumonias_list[index])
#================================================#
plt.figure(figsize=(12, 8))
#------------------------------------------------#
plt.subplot(131)
plt.title("Normal")
plt.imshow(normal_image)
#------------------------------------------------#
plt.subplot(132)
plt.title("Covid")
plt.imshow(covid_image)
#------------------------------------------------#
plt.subplot(133)
plt.title("Pneumonia")
plt.imshow(pneumonia_image)
#------------------------------------------------#
plt.tight_layout()
5. Build Training Dataset ( Tensor (X) )
from torch.utils.data import Dataset, DataLoader
Training dataset directory & 3 types of class :
train_data_dir = "../DATASET/Classification/train/"
class_list = ["Normal", "Covid", "Viral Pneumonia"]
Basic Format of Dataset
__init____len____getitem__
class Chest_dataset(Dataset):
def __init__(self, x):
pass
def __len__(self):
pass
def __getitem__(self, x):
pass
class Chest_dataset(Dataset):
def __init__(self, data_dir, transform=None):
self.data_dir = data_dir
normals = list_image_files(data_dir, "Normal")
covids = list_image_files(data_dir, "Covid")
pneumonias = list_image_files(data_dir, "Viral Pneumonia")
total_file_paths = normals + covids + pneumonias
self.files_path = total_file_paths
self.transform = transform
def __len__(self):
return len(self.files_path) # total number of data
def __getitem__(self, index):
# (1) get path of certain image
image_file = os.path.join(self.data_dir, self.files_path[index])
# (2) read & convert color
image = cv2.imread(image_file)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# (3) get target
### target_str : "Normal", "Covid", "Viral Pneumonia"
### target : 0, 1, 2
target_str = self.files_path[index].split(os.sep)[0]
target = class_list.index(target_str)
# (4) (optional) transform into tensor
if self.transform:
image = self.transform(image)
target = torch.Tensor([target]).long()
return {"image":image, "target":target}
Build Training Dataset
training_dset = Chest_dataset(train_data_dir)
Visualize certain data
index = 200
image_ex = training_dset[index]["image"]
target_ex = class_list[training_dset[index]["target"]]
plt.title(target_ex)
plt.imshow(image_ex)
6. Build Training Dataset ( Tensor (O) )
Transform the data into tensor ( with torchvision.transforms )
Step 1) Transform to Tensor : transforms.ToTensor
Step 2) Resize Images : transforms.Resize
Step 3) Normalize Images : transforms.Normalize
from torchvision import transforms
transformer = transforms.Compose([
transforms.ToTensor(),
transforms.Resize((224, 224)),
transforms.Normalize(mean=[0.5, 0.5, 0.5],
std=[0.5, 0.5, 0.5])
])
Build Training Dataset
training_dset = Chest_dataset(train_data_dir, transform = transformer)
Check shape of images
index = 200
image_ex = training_dset[index]["image"]
target_ex = class_list[training_dset[index]["target"]]
print(image.shape)
print(label)
torch.Size([3, 224, 224])
tensor([2])
7. Dataloader
Function that returns train & val dataloaders in dictionary
def build_dataloader(train_data_dir, val_data_dir):
dataloaders = {}
# (1) Datasets
train_dset = Chest_dataset(train_data_dir, transformer)
val_dset = Chest_dataset(val_data_dir, transformer)
# (2) Dataloaders
# -- train : shuffle (O)
# -- val : shuffle (X)
dataloaders["train"] = DataLoader(train_dset, batch_size=4, shuffle=True, drop_last=True)
dataloaders["val"] = DataLoader(val_dset, batch_size=1, shuffle=False, drop_last=False)
return dataloaders
Build dataloaders
train_data_dir = "../DATASET/Classification/train/"
val_data_dir = "../DATASET/Classification/test/"
dataloaders = build_dataloader(train_data_dir, val_data_dir)
Check data from dataloader
for batch_idx, batch in enumerate(dataloaders["train"]):
if batch_idx == 0:
break
target = batch['target'] # batch size = 4
print(target.shape)
print(target)
print(target.squeeze())
torch.Size([4, 1])
tensor([[1],
[0],
[0],
[1]])
tensor([1, 0, 0, 1])
8. Build Model ( VGG10 )
from torchvision import models
model = models.vgg19(pretrained=True) # use PRE-trained version
https://www.researchgate.net/profile/Clifford-Yang/publication/325137356/figure/fig2/AS:670371271413777@1536840374533/llustration-of-the-network-architecture-of-VGG-19-model-conv-means-convolution-FC-means.jpg
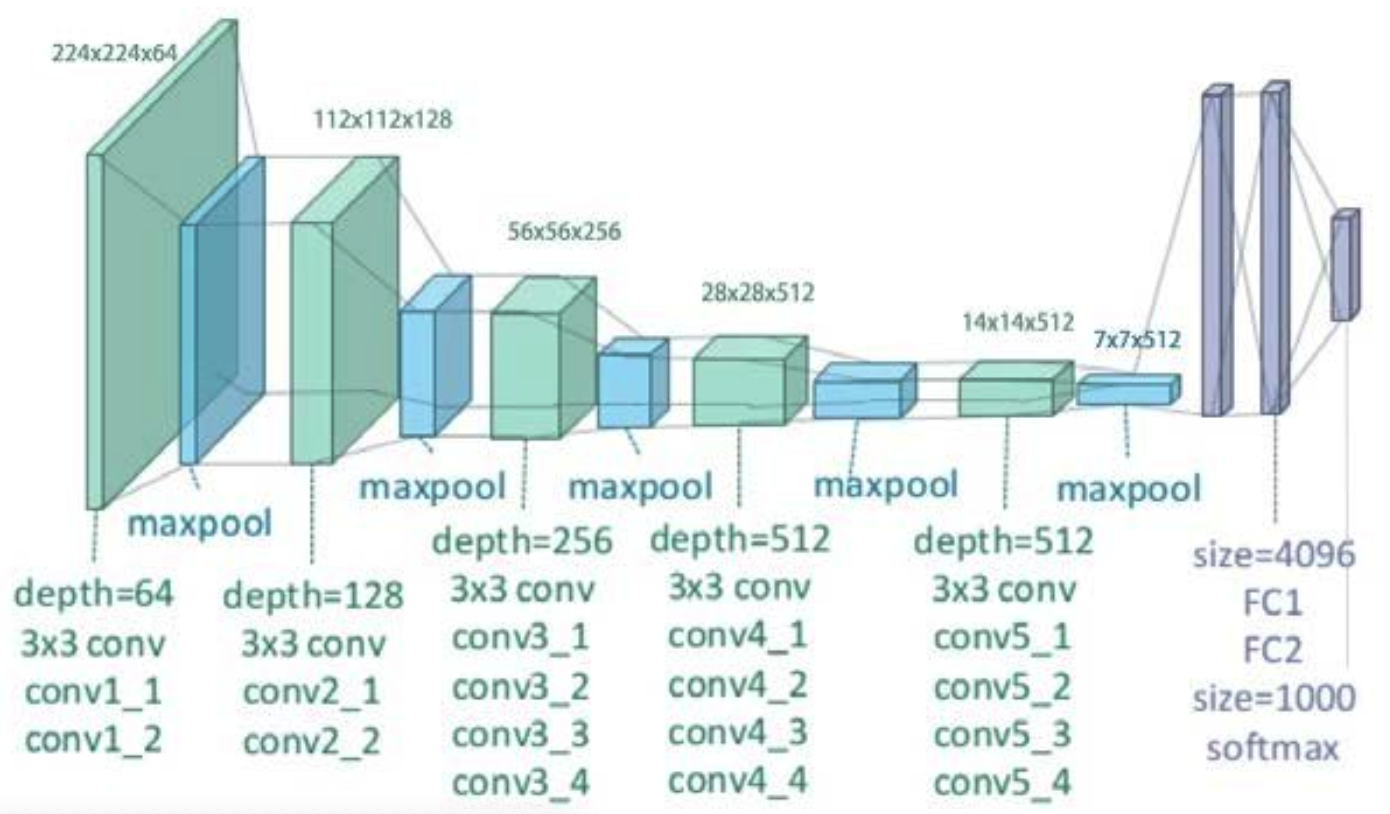
Show the summary of VGG16 : can check…
- architecture ( types of layers )
- change of the feature maps
- number of parameters
from torchsummary import summary
input_size = (3, 224, 224)
summary(model, input_size, batch_size=1, device="cpu")
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [1, 64, 224, 224] 1,792
ReLU-2 [1, 64, 224, 224] 0
Conv2d-3 [1, 64, 224, 224] 36,928
ReLU-4 [1, 64, 224, 224] 0
MaxPool2d-5 [1, 64, 112, 112] 0
Conv2d-6 [1, 128, 112, 112] 73,856
ReLU-7 [1, 128, 112, 112] 0
Conv2d-8 [1, 128, 112, 112] 147,584
ReLU-9 [1, 128, 112, 112] 0
MaxPool2d-10 [1, 128, 56, 56] 0
...
Conv2d-35 [1, 512, 14, 14] 2,359,808
ReLU-36 [1, 512, 14, 14] 0
MaxPool2d-37 [1, 512, 7, 7] 0
AdaptiveAvgPool2d-38 [1, 512, 7, 7] 0
Linear-39 [1, 4096] 102,764,544
ReLU-40 [1, 4096] 0
Dropout-41 [1, 4096] 0
Linear-42 [1, 4096] 16,781,312
ReLU-43 [1, 4096] 0
Dropout-44 [1, 4096] 0
Linear-45 [1, 1000] 4,097,000
Forward/backward pass size (MB): 238.69
Params size (MB): 548.05
Estimated Total Size (MB): 787.31
----------------------------------------------------------------
9. Fine Tuning
Output size :
- original VGG16 : 1000
- our task : 3
\(\rightarrow\) need to change the HEAD part!
Overwrite the layer modules in model!
def build_vgg19_based_model(device_name='cpu'):
device = torch.device(device_name)
# (1) Pre-trained model
model = models.vgg19(pretrained=True)
# (2) change the HEAD part (output dim=3)
model.avgpool = nn.AdaptiveAvgPool2d(output_size=(1,1))
model.classifier = nn.Sequential(
nn.Flatten(),
nn.Linear(512, 256),
nn.ReLU(),
nn.Linear(256, len(class_list)),
nn.Softmax(dim=1)
)
return model.to(device)
model = build_vgg19_based_model(device_name='cpu')
10. Loss Function & Optimizer
Loss function : CE loss
Optimizer : SGD
loss_func = nn.CrossEntropyLoss(reduction="mean")
optimizer = torch.optim.SGD(model.parameters(), lr= 1E-3, momentum=0.9)
11. Training function
device = torch.device("cpu") # "cuda"
with torch.no_grad() 대신, with torch.set_grad_enabled 사용하면 편리!
def train_one_epoch(dataloaders, model, optimizer, loss_func, device):
losses = {}
accuracies = {}
for phase in ["train", "val"]:
running_loss = 0.0
running_correct = 0
# Dropout시, 보정 고려!
if phase == "train":
model.train()
else:
model.eval()
for index, batch in enumerate(dataloaders[phase]):
image = batch["image"].to(device)
target = batch["target"].squeeze(1).to(device)
optimizer.zero_grad()
# Train time : Gradient (O)
# Test time : Gradient (X)
with torch.set_grad_enabled(phase == "train"):
prediction = model(image)
loss = loss_func(prediction, target)
# Back-prop only in TRAIN time!
if phase == "train":
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item()
running_correct += get_accuracy(image, target, model)
if phase == "train":
if index % 10 == 0:
print(f"{index}/{len(dataloaders[phase])} - Running Loss: {loss.item()}")
losses[phase] = running_loss / len(dataloaders[phase])
accuracies[phase] = running_correct / len(dataloaders[phase])
return losses, accuracies
12. Validation function & Save Models
@torch.no_grad() to not save gradient
@torch.no_grad()
def get_accuracy(image, target, model):
batch_size = image.shape[0]
prediction = model(image)
# get "class label" of predicted value
_, pred_label = torch.max(prediction, dim=1)
is_correct = (pred_label == target)
return is_correct.cpu().numpy().sum() / batch_size
torch.save to save model weights
def save_best_model(model_state, model_name, save_dir="./trained_model"):
os.makedirs(save_dir, exist_ok=True) # make directory, if NOT EXISTS
torch.save(model_state, os.path.join(save_dir, model_name))
13. Summary
device = torch.device("cuda")
train_data_dir = "../DATASET/Classification/train/"
val_data_dir = "../DATASET/Classification/test/"
dataloaders = build_dataloader(train_data_dir, val_data_dir)
model = build_vgg19_based_model(device='cuda')
loss_func = nn.CrossEntropyLoss(reduction="mean")
optimizer = torch.optim.SGD(model.parameters(), lr= 1E-3, momentum=0.9)
num_epochs = 10
best_acc = 0.0
train_loss, train_accuracy = [], []
val_loss, val_accuracy = [], []
for epoch in range(num_epochs):
losses, accuracies = train_one_epoch(dataloaders, model, optimizer, loss_func, device)
train_loss.append(losses["train"])
val_loss.append(losses["val"])
train_accuracy.append(accuracies["train"])
val_accuracy.append(accuracies["val"])
print(f"{epoch+1}/{num_epochs}-Train Loss: {losses['train']}, Val Loss: {losses['val']}")
print(f"{epoch+1}/{num_epochs}-Train Acc: {accuracies['train']}, Val Acc: {accuracies['val']}")
# save best model with highest validation accuracy
if (epoch > 3) and (accuracies["val"] > best_acc):
best_acc = accuracies["val"]
best_model = copy.deepcopy(model.state_dict())
save_best_model(best_model, f"model_{epoch+1:02d}.pth")
print(f"Best Accuracy: {best_acc}")
14. Test on new images
Import Test Datasets
test_data_dir = "../DATASET/Classification/test/"
class_list = ["Normal", "Covid", "Viral Pneumonia"]
test_normals_list = list_image_files(test_data_dir, "Normal")
test_covids_list = list_image_files(test_data_dir, "Covid")
test_pneumonias_list = list_image_files(test_data_dir, "Viral Pneumonia")
Convert colors ( BGR - > RGB )
normal_image = get_RGB_image(data_dir, test_normals_list[index])
covid_image = get_RGB_image(data_dir, test_covids_list[index])
pneumonia_image = get_RGB_image(data_dir, test_pneumonias_list[index])
Need the same process(transformation) to the test images
def preprocess_image(image):
# (1) transform to tensor ( + resize & normalization )
transformer = transforms.Compose([
transforms.ToTensor(),
transforms.Resize((224, 244)),
transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5,0.5,0.5])
])
tensor_image = transformer(image) # (C, H, W)
# (2) Change shape ( make "batch size" dimension )
tensor_image = tensor_image.unsqueeze(0) # (B, C, H, W)
return tensor_image
Load trained model & test on new dataset
model_ckpt = torch.load("./trained_model/model_06.pth")
model = build_vgg19_based_model(device='cpu')
model.load_state_dict(model_ckpt) # load model weight
model.eval()
Function to test on new images
#===========================================================================#
## OPTION 1
def model_predict(image, model):
tensor_image = preprocess_image(image)
with torch.no_grad():
prediction = model(tensor_image)
_, pred_label = torch.max(prediction.detach(), dim=1)
pred_label = pred_label.squeeze(0)
return pred_label.item()
#===========================================================================#
## OPTION 2
@torch.no_grad()
def model_predict(image, model):
tensor_image = preprocess_image(image)
prediction = model(tensor_image)
_, pred_label = torch.max(prediction.detach(), dim=1)
pred_label = pred_label.squeeze(0)
return pred_label.item() # .item() : get only the numeric value!
pred1 = model_predict(normal_image, model)
pred2 = model_predict(covid_image, model)
pred3 = model_predict(pneumonia_image, model)
pred1_str = class_list[pred1]
pred2_str = class_list[pred2]
pred3_str = class_list[pred3]