( 참고 : “FastCampus, 데이터 엔지니어링 올인원” )
[ Data Engineering ]
Spotify Project Architecture
목차
- Artists 관련 데이터 수집 프로세스
- 데이터 분석 환경 구축
- 서비스 관련 데이터 프로세스
1. Artists 관련 데이터 수집 프로세스
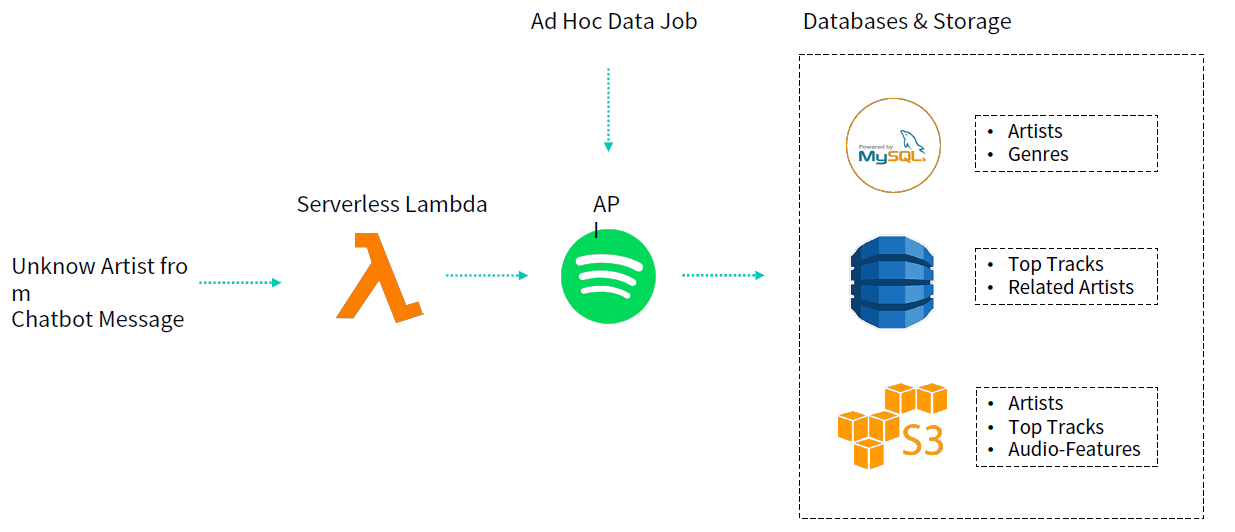
Artist, Genre, Top Tracks, Related Artists등의 정보를 얻을 것이다.
-
ex) message 받음 ( “나 BTS를 좋아해!”) -> 유사한 artists 반환해주기
-
BUT, 우리의 DB에 해당 artist(BTS)가 없을 경우?
-
Trigger에 의해 Spotify API를 hit해서, ( Lambda )
이를 통해 data를 받아옴 + 저장함 ( MySQL, DynamoDB, S3 )
-
Ad Hoc Data Job : 기존에 가지고 있는 몇천명의 artists 정보를 불러오기
-
2. 데이터 분석 환경 구축
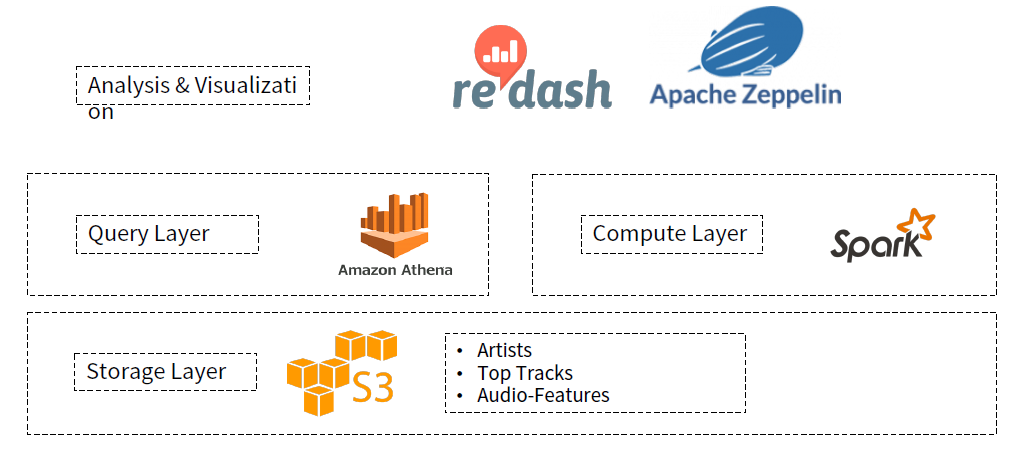
(1) S3라는 Storage layer에 저장이 됨
(2-1) S3에 있는 데이터를 기반으로, (Query layer) SQL을 기반으로한 Presto 서비스인 Amazon Athena를 통해서 다양한 ad-hoc 분석 진행 가능
(2-2) (Compute Layer) Spark를 사용하여 분산 처리
(3) Zeplin을 통해 Spark 환경에서 분석 가능!
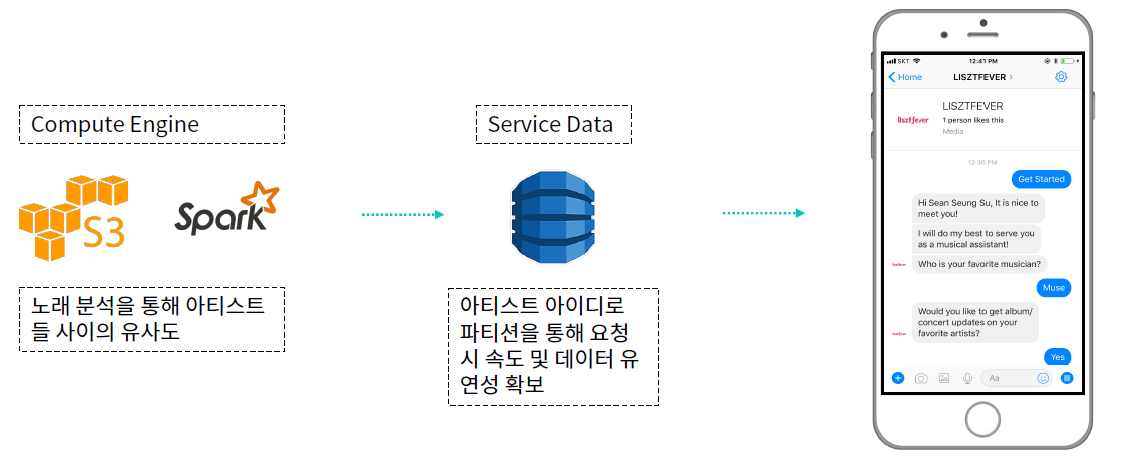
3. 서비스 관련 데이터 프로세스