
[ Topic Modeling ]
( 참고 : “딥러닝을 이용한 자연어 처리 입문” (https://wikidocs.net/book/2155) )
Topic Modeling은 말 그대로 글 속의 숨겨진 “주제”를 통계적인 기법을 사용해서 찾아내는 것이라고 할 수 있다. 이러한 Topic Modeling의 방법에는 크게 (1) LSA (Latent Semantic Analysis, 잠재의미분석)와, (2) LDA (Latent Dirichlet Allocation)가 있다.
2. LDA
1) Introduction
- 가정 : “문서는 Topic들의 혼합으로 구성되어 있고”, “각각의 Topic은 확률 분포에 기반하여 단어를 생성”
( 직관적 이해 : “나는 문서 작성을 위해서, ~~ 주제들을 각각 ~~의 비율로 넣을것이고,
이런 주제들을 구성하기 위해 ~~단어들을 넣을 것이야!” )
- 즉, 데이터가 주어진 상황에서, LDA는 ‘문서가 생성되는 과정을 역추적’하는 것이라고 볼 수 있다
2) Assumption
각각의 문서는 다음과 같은 가정을 거쳐서 작성이 되었다고 가정함
-
step 1) 문서에 사용할 단어의 개수 N을 정한다
-
step 2) 문서에 사용할 Topic의 혼합을, 확률분포에 기반하여 결정한다 ( topic 분포를 정한다 )
( ex. 세 개의 주제, 각각 스포츠 30%, 과일 40%, 연애 40% ,로 문서를 작성할거야! )
-
step 3) 문서에 사용할 각 단어를 정함 ( 단어의 출현 확률 분포를 정한다 )
( ex. 스포츠 주제를 작성하기 위해, 축구20%, 농구 15%, 야구 10%,…의 단어를 사용할 것이야! )
-
step 4) Topic 분포에서, topic T를 확률적으로 고른다
( ex. 따라서 스포츠는 30%의 확률로 뽑히고, 연애는 40%의 확률로 뽑힌다 )
-
step 5) 선택된 topic T에서, 단어의 출현 확률 분포에 기반해서 문서에 사용할 단어를 고른다
3) LDA Algorithm
-
step 1) LDA에게 Topic의 개수 k 입력
( 그러면, LDA는 k개의 토픽이 전체 문서들에 걸쳐 분포되어 있다고 가정한다 ) -
step 2) 단어에 Topic 할당
( 모든 단어들에게 반드시 하나의 Topic을 랜덤하게 할당한다. 이러한 Topic을 이후 단계에서 계속 update할 것이다 ) -
step 3) Topic Update
( 모든 단어들은, 자기 자신은 ‘잘못된’ topic에 할당되었다고 생각하고, 자신을 제외한 나머지 단어들은 ‘옳은’ topic에 할당되어 있다고 생각하고 update가 이루어진다. 각각의 단어들은 아래의 기준에 따라 topic이 update된다 )기준 1) P( t | d ) : 문서 d의 단어 들 중, Topic t에 해당하는 단어들의 비율 기준 2) P( w | t ) : 단어 w를 가지고 있는 모든 문서들 중, Topic t가 할당된 비율
EXAMPLE
다음과 같이 apple, banana, dog, cute, book 등의 단어로 구성된 두 개의 문서가 있다고 해보자. 여기서, 우리는 첫 번째 문서 (doc1)의 세 번째
단어인 apple을 update하고자 한다. ( 해당 단어 외의 나머지 단어들은 모두 topic이 ‘옳게’ 할당되어 있다고 가정한다 )

https://wikidocs.net/images/page/30708/lda1.PNG
기준 1)
- doc1의 (apple을 제외한) 4개의 단어는 각각 2개의 주제 A,B가 50:50으로 분포되어 있다. 따라서 apple은 Topic A,B에 모두 속할 가능성이 있다
기준 2)
- ‘apple’이란 단어를 포함한 모든 문서(doc1,doc2) 각각에 어떤 Topic이 있는지를 확인해본다.
- 그 결과, doc1에서도 100% (1/1)로 topic B에 할당되어 있고, doc2에서도 100% (2/2)로 topic B에 할당되어 있는 것을 확인할 수 있다.
- 이를 통해, doc1의 세 번째 단어인 apple을 ‘topic B’에 할당한다. 이러한 과정을 반복하여, 모든 단어들이 topic을 update해나간다.
4) LSA vs LDA
- LSA : DTM을 차원축소하여, 축소 차원에서 근접 단어들을 Topic으로 묶음
- LDA : 특정 단어가 특정 topic에 존재할 확률과, 문서에 특정 topic이 존재할 확률을 결합확률로 추정하여 Topic을 추출
5) 실습 ( fetch_20newsgroups )
불용어처리까지는 ‘LSA’에서 실습한 과정과 동일하다
import pandas as pd
from sklearn.datasets import fetch_20newsgroups
from nltk.corpus import stopwords
dataset = fetch_20newsgroups(shuffle=True,random_state=1, remove=('headers','footers','quotes'))
documents = dataset.data
news_df = pd.DataFrame({'document':documents})
news_df['clean_doc'] = news_df['document'].str.replace("[^a-zA-Z]", " ")
news_df['clean_doc'] = news_df['clean_doc'].apply(lambda x: ' '.join([w for w in x.split() if len(w)>3]))
news_df['clean_doc'] = news_df['clean_doc'].apply(lambda x: x.lower())
stop_words = stopwords.words('english')
tokenized_doc = news_df['clean_doc'].apply(lambda x : x.split())
(1) 정수 인코딩 & 단어 집합 생성
- 각 단어에 정수를 인코딩
- 각 뉴스에서 단어의 빈도수를 기록
- 각 단어를 (word_id, word_frequency) 형태로 표현
from gensim import corpora
dictionary = corpora.Dictionary(tokenized_doc)
corpus = [dictionary.doc2bow(text) for text in tokenized_doc]
6번째 news의 모든 단어를 (word_id, word_frequency) 형태로 출력
corpus[5]
[(49, 1),
(83, 1),
(150, 1),
(213, 1),
(214, 1),
(215, 1),
(216, 1),
(217, 1),
(218, 2),
(219, 1),
(220, 1),
(221, 1),
(222, 1),
(223, 1),
(224, 2),
(225, 1),
(226, 1),
(227, 1),
(228, 1),
(229, 1),
(230, 1)]
(2) train LDA
- 기존의 뉴스 데이터가 20개의 카테고리를 가졌기 때문에, topic의 개수를 20개로 지정하여 모델을 학습시킨다
- hyperparameters:
num_topics = 20 ( topic의 개수를 20개로 지정 ) num_words = 4 ( 각 topic을 구성하는 단어들을 상위 4개까지 표현 )
import gensim
NUM_TOPICS = 20
ldamodel = gensim.models.ldamodel.LdaModel(corpus, num_topics=NUM_TOPICS,
id2word=dictionary, passes=15)
topics = ldamodel.print_topics(num_words=4)
for topic in topics:
print(topic)
(0, '0.010*"nrhj" + 0.007*"wwiz" + 0.006*"bxom" + 0.006*"gizw"')
(1, '0.030*"windows" + 0.014*"color" + 0.011*"card" + 0.010*"video"')
(2, '0.023*"would" + 0.022*"thanks" + 0.020*"anyone" + 0.020*"please"')
(3, '0.017*"period" + 0.010*"power" + 0.009*"play" + 0.006*"scorer"')
(4, '0.005*"hitter" + 0.004*"innings" + 0.004*"inning" + 0.004*"pitched"')
(5, '0.007*"control" + 0.007*"guns" + 0.006*"firearms" + 0.006*"university"')
(6, '0.016*"file" + 0.011*"available" + 0.009*"program" + 0.009*"information"')
(7, '0.019*"game" + 0.017*"team" + 0.015*"year" + 0.013*"games"')
(8, '0.014*"health" + 0.010*"medical" + 0.010*"pain" + 0.008*"disease"')
(9, '0.017*"drive" + 0.015*"system" + 0.012*"chip" + 0.011*"scsi"')
(10, '0.011*"government" + 0.007*"armenian" + 0.007*"people" + 0.006*"armenians"')
(11, '0.013*"book" + 0.011*"jesus" + 0.008*"matthew" + 0.006*"word"')
(12, '0.020*"window" + 0.010*"motif" + 0.010*"using" + 0.009*"widget"')
(13, '0.013*"church" + 0.009*"water" + 0.009*"cover" + 0.008*"catholic"')
(14, '0.013*"keyboard" + 0.008*"road" + 0.006*"engine" + 0.005*"ford"')
(15, '0.028*"space" + 0.010*"nasa" + 0.007*"research" + 0.006*"center"')
(16, '0.016*"would" + 0.011*"people" + 0.009*"think" + 0.009*"like"')
(17, '0.012*"jesus" + 0.009*"believe" + 0.009*"christian" + 0.008*"bible"')
(18, '0.009*"bike" + 0.006*"cars" + 0.005*"miles" + 0.005*"tobacco"')
(19, '0.007*"power" + 0.006*"used" + 0.006*"good" + 0.006*"price"')
(3) Visualization
import pyLDAvis.gensim
pyLDAvis.enable_notebook()
vis = pyLDAvis.gensim.prepare(ldamodel, corpus, dictionary)
pyLDAvis.display(vis)
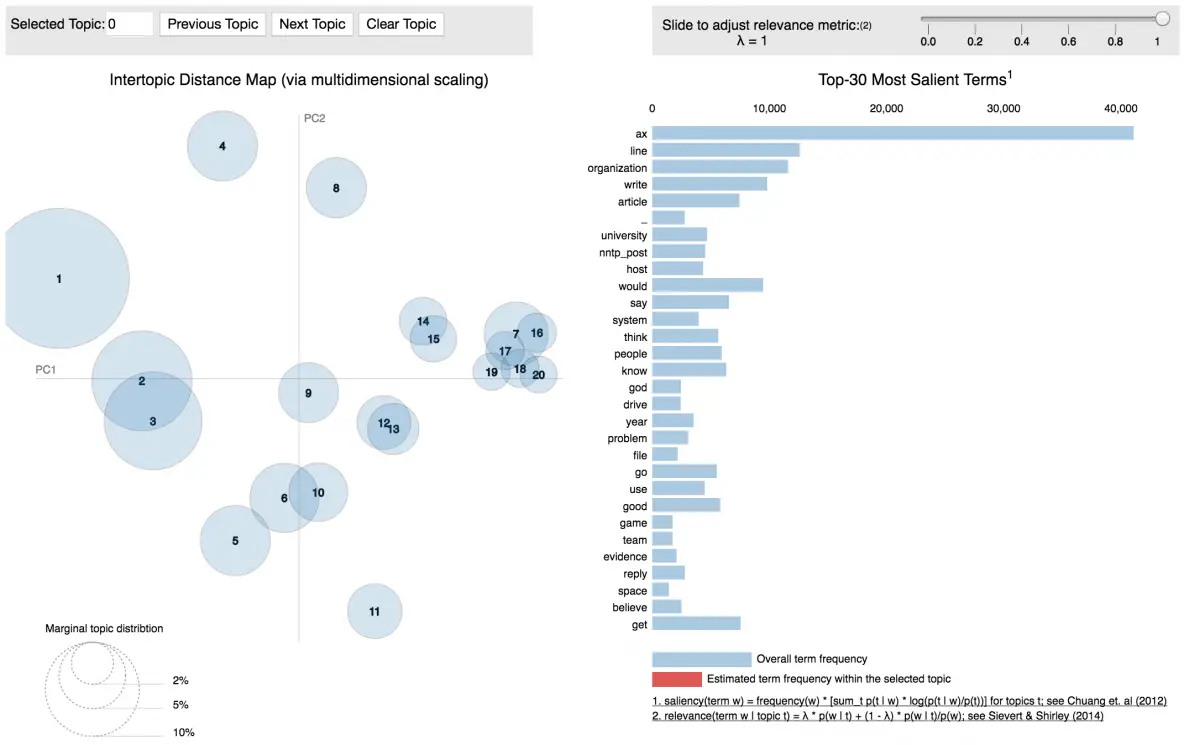
https://www.machinelearningplus.com/wp-content/uploads/2018/03/pyLDAvis.png
- 좌측의 원들은 ‘각각의 topic’을 나타낸다
- 원들 간의 거리는, ‘topic들 간의 유사한 정도’를 나타낸다
( 겹치는 원 = 유사한 topic ) - 우측에는 해당 topic을 구성하는 term과 그 비율을 나타낸다
(4) 문서 별 Topic 확인하기
for i, topic_list in enumerate(ldamodel[corpus]):
if i==5:
break
print(i, '번 째 문서의 TOPIC 비율 : ', topic_list)
0 번 째 문서의 TOPIC 비율 : [(10, 0.29285672), (11, 0.16073646), (16, 0.4919449), (18, 0.041558668)]
1 번 째 문서의 TOPIC 비율 : [(4, 0.025609754), (7, 0.25793052), (13, 0.026179668), (16, 0.45710588), (17, 0.21488152)]
2 번 째 문서의 TOPIC 비율 : [(10, 0.27561134), (16, 0.57688445), (18, 0.1337945)]
3 번 째 문서의 TOPIC 비율 : [(2, 0.07093574), (3, 0.08743375), (8, 0.016644193), (9, 0.31374454), (10, 0.08422507), (14, 0.018146532), (16, 0.39916867)]
4 번 째 문서의 TOPIC 비율 : [(7, 0.6907137), (16, 0.27595297)]
보기 쉽게 table로 만들어서 표현
def make_topic_table(ldamodel, corpus, texts):
topic_table = pd.DataFrame()
for i, topic_list in enumerate(ldamodel[corpus]):
# 각 document에서 비중이 높은 Topic 순으로 정렬
doc = topic_list[0] if ldamodel.per_word_topics else topic_list
doc = sorted(doc, key=lambda x:(x[1]), reverse=True)
for j, (topic_num, prop_topic) in enumerate(doc):
if j==0: # 가장 비중 높은 TOPIC
topic_table = topic_table.append(pd.Series([int(topic_num), round(prop_topic,4), topic_list]),
ignore_index=True)
else:
break
return(topic_table)
Topic_table = make_topic_table(ldamodel, corpus, tokenized_doc)
Topic_table = Topic_table.reset_index()
Topic_table.columns = ['Document #', 'TOP Topic','Top Topic %','Each Topic %']