
LINE : Large-scale Information Network Embedding
INTRODUCTION
이 논문은 network 상의 매우 많은 vertices들을 어떻게 저차원의 vector space로 embedding하는지에 관한 글이다. 이렇게 저차원 공간으로 임베딩하는 주요 이유는 “visualization”, “node classification”( 해당 node/vertice가 어느 class에 속하는지 ), “link prediction”( 두 node가 서로 연결되어있는지 predict ) 등이 있다.
네트워크 임베딩에 여러 방법들이 있지만, 이 논문에서 제시하는 LINE은 undirected/directed/weighted 네트워크에 모두 적용 가능하며, 특히 node수가 많은 “large scale”에서 다른 방법들에 비해 효율적으로 빠르게 작동한다는 점에서 눈에 띈다.
CONTRIBUTION
LINE에서 주요하게 다룬 두 가지 핵심은
a) first-order proximity & second-order proximity를 모두 고려한 objective function
b) edge sampling algorithm : Negative Sampling
이다
a. Objective Function
이 알고리즘의 목적함수 (objective function)을 알아보기 전에, first order proximity와 second order proximity에 대해 먼저 알아보자. 여기서 proximity는 근접성, 쉽게 표현하면 얼마나 가까운지(비슷한지)로, similiarity로 표현하여도 무방하다. 이 두 proximity(similarity)는 다음과 같이 한 문장으로 표현할 수 있다.
first order proximity? : “두 node를 연결하는 weight가 높다면 두 node는 비슷하다”
second order proximity? : “두 node가 서로 공유하고 있는 node들 (neighbours)이 비슷하다면, 두 node는 비슷하다”
아래 그림을 예시로 보자.
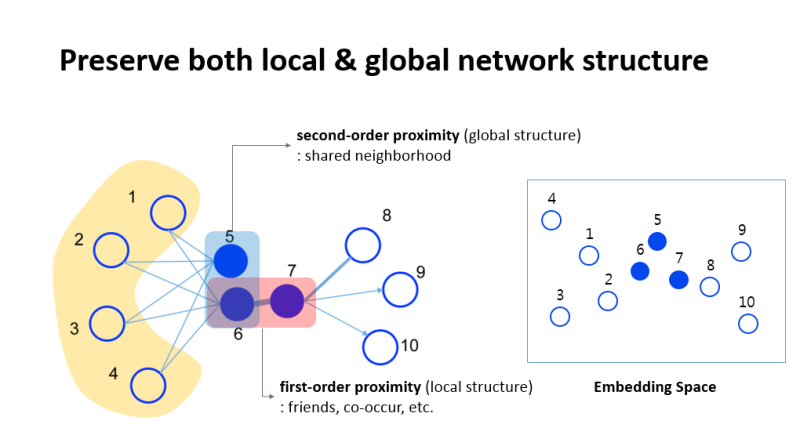
이 그림에서, node 6과 node 7은 서로 강하게 연결(high weight)되어 있다. 그렇기 때문에 이 둘은 서로 높은 “first order proximity”를 가진다고 할 수 있다. 이에 반해, node5와 node6은 서로 연결되어 있지는 않지만, 이 둘이 공유하는 노드는 4개나 있다(node1~4). 그렇기 때문에 이 둘은 “second order proximity”가 높다고 할 수 있다.
이처럼, LINE은 두 가지 측면에서 simliarity를 바라본다.
WHY?
기존에 있던 대부분의 graph embedding algorithm들은 “first-order proximity”를 잘 보존하는 embedding model을 만들었다. 하지만, 오늘 날 real world는, 그 node/vertice수 (ex. text속의 단어 수 혹은 facebook의 회원의 수 등)가 매우 많기 때문에 임의로 뽑은 서로 다른 두개의 node사이에 link가 없는 경우가 대부분이기 때문에 , 이 first order proximity로만 표현하기엔 적절하지 않다. 그래서 이를 보완하고자 second order proximity가 등장하게 된것이다. LINE은 이 두 가지를 모두 고려한다.
“local” structure를 잡아내기 위한 “first order proximity”, “global” structure를 잡아내기 위한 “second order proximity”
b. edge sampling algorithm : Negative Sampling
위 처럼 이 두 가지를 모두 고려한 objective function(수식은 이후에 자세히 설명)이 있다고 하더라도, optimize하기에는 쉽지 않다. 최근에 자주 사용하는 optimization 방법으로 SGD(Stochastic Gradient Descent)가 있긴 하지만, 현실 세계의 network에서는 이를 저굥하기가 쉽지 않다. update 해야 할 weight의 수(수 많은 node로 인한 수 많은 edge들!)가 너무 많기 때문이다. 이러기 위해 LINE은 negative sampling을 사용하여 효율성을 높인다. (https://github.com/seunghan96/datascience/blob/master/%5B%EC%97%B0%EA%B5%AC%EC%8B%A4%EC%9D%B8%ED%84%B4%5DComputing_Science_and_Engineering/2%EC%A3%BC%EC%B0%A8/Negative_Sampling.md 참고)
weight를 update하는데에 있어서 모든 edge를 대상으로 하지 않고, 일부를 sample하는 방식이다. 각 edge가 sample될 확률은 해당 edge가 가지는 weight와 비례한다.