
Multimodal Transformer for Unaligned Multimodal Language Sequences
Abstract
인간의 행동/언어 관련 많은 행동들은 Multimodal
(time-series와 관련된) Multimodal modeling에서의 문제점
- 1) non-alignment
- 2) long-range dependencies
이 문제를 해결하기 위해 제안한 MulT (Multimodal Transformer)
MulT
-
non-alignment를 align함으로써 해결하는게 아님!
( non-aligned 상태 그대로 사용 )
-
directional pairwise cross-modal attention 사용
- interaction between modalities 잡아내
- one modality \(\rightarrow\) other modality
1. Introduction
HETEROgeneties across modalities
-
ex) 화나서 친구한테 욕 엄청한 다음, 꾹 참다가 5초뒤 때림
( 욕을 뱉었던 시간 \(\neq\) 때린 시간 )
-
“unaligned”되어있다 & long term dependencies across modalities가 필요!
- unaligned = modality 별 sequence 길이가 다름!
기존의 방법들 : unaligned를 aligned로 수정하려는 시도들!
문제저 많음
- manual, interaction 포착 X, long-range cross modal contingencies of original features 고려 못함, 도메인 지식 필요 등….
그래서 MulT를 제안!
- 핵심 : cross-modal attention module
- 전체 발화(utterance)를 attention
- one modality \(\rightarrow\) other modality
2.Related Work
Human Multimodal Language Analysis
-
Early Fusion / Late Fusion
-
Hierarchical attention
-
Adjusted the word representations using accompanying non-verbal behaviors
-
cyclic translation objective
-
cross-modal AE for audio-visual alignment
위의 모든 방법들은 모두 “aligned” 가정 하에!
( 우리 MulT는 align 안해도 됨! )
Transformer
친숙하니 Skip
3. Proposed Method
for modedling unaligned multimodal language sequences\
[ 아키텍처 상세 소개 ]
multiple directional pairwise crossmodal transformer 사용!
- 각각의 crossmodal transformer : source modality \(\rightarrow\) target modality 유도
- “모든” pair of modality를 모델링함
3-1. Crossmodal Attention
( 두 modalities \(\alpha\) & \(\beta\) )
latent adaptation from \(\alpha\) to \(\beta\) :
\[Y_{\alpha}:=\mathrm{CM}_{\beta \rightarrow \alpha}\left(X_{\alpha}, X_{B}\right) \in \mathbb{R}^{T_{\alpha} \times d_{v}}\] \[\begin{aligned} Y_{\alpha} &=\mathrm{CM}_{\beta \rightarrow \alpha}\left(X_{\alpha}, X_{\beta}\right) \\ &=\operatorname{softmax}\left(\frac{Q_{\alpha} K_{\beta}^{\top}}{\sqrt{d_{k}}}\right) V_{\beta} \\ &=\operatorname{softmax}\left(\frac{X_{\alpha} W_{Q_{\alpha}} W_{K_{\beta}}^{\top} X_{\beta}^{\top}}{\sqrt{d_{k}}}\right) X_{\beta} W_{V_{\beta}} \end{aligned}\]* self attention 아님!
그런 뒤…
- residual connection
- pointwise FFNN
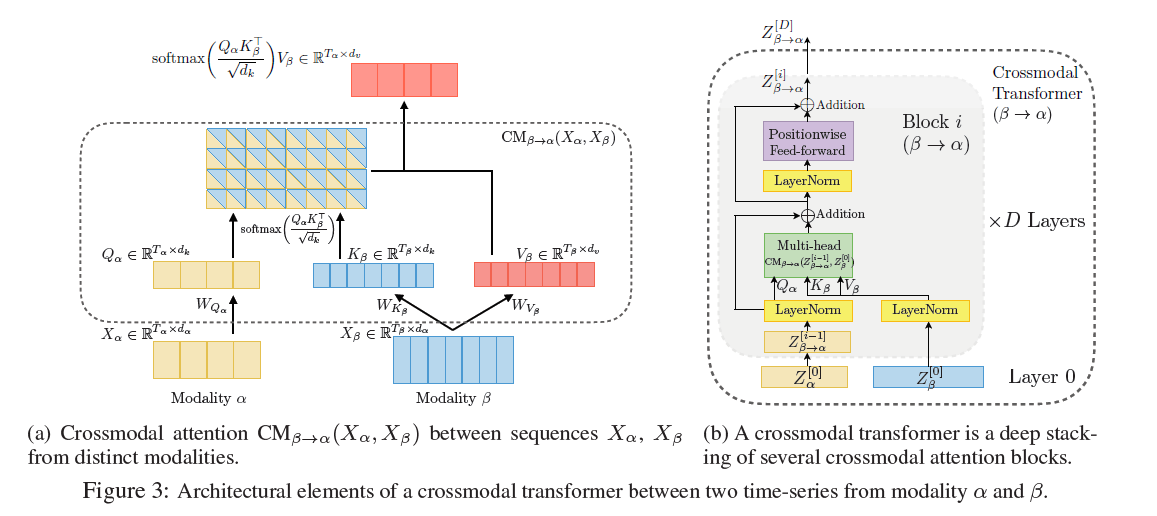
3-2. Overall Architecture
- \(L\) (Language). \(V\) (Video), \(A\) (Audio)
Temporal Convolutions
- 주변 요소 (neighborhood elements) 정보 반영 위한 1D conv layer 사용
Positional Embedding
- temporal 정보 catch
Crossmodal Transformer
-
하나의 crossmodal transformer는 \(D\) 개의 crossmodal attention block으로 구성
( 위에서 crossmodal attention block 자세히 설명했었음 )
-
한 modality에서 다른 modality로 정보 전달 가능케함
Self-Attention Transformers & Prediction
같은 target modality를 가지는 crossmodal transformer의 output들 concatenate!
- ex) \(Z_{L}=\left[Z_{V \rightarrow L}^{[D]} ; Z_{A \rightarrow L}^{[D]}\right]\)
- concatenate되있는거 NN타고 최종 output 산출