
Target-oriented Opinion Words Extraction with Target-fused Neural Sequence Labeling (2019)
Contents
- Abstract
- Introduction
- Our Methods
- Task formulation
- Framework
- Target-Fused Encoder
- Decoder & training
0. Abstract
ABSA의 2가지 main task
- (1) Opinion target extraction
- (2) Opinion words extraction
\(\rightarrow\) Few works aim to extract BOTH AS PAIRS
Propose a novel TOWE (=Target-oriented Opinion Words Extraction)
- extract opinion words for a given opinion target
- 이를 수행 하기 위해 target-fused seuqence labeling NN을 만듬
1. Introduction

given a review & target in a review…
Goal of TOWE : Extract the corresponding opinion words
( 핵심은, learning a target-specific context representations )
TOWE를 수행하기 위한 powerful target-fused sequence labeling NN을 제안함
Inward-Outward LSTM
- neural encoder to incorporate target info & generate target-fused context
- pass target info to the left & right context respectively
Contribution
- (1) (sequence labeling subtask for ABSA인) TOWE를 제안함
- (2) TOWE를 풀기 위한 novel sequence labeing NN를 만듬
- generate target-specific context representations
2. Our Methods
2-1) Task formulation
Notation
-
sentence : \(s=\left\{w_{1}, w_{2}, \ldots, w_{i}, \ldots, w_{n}\right\}\)
-
task : sequence labeling
( target-oriented opinion words를 뽑아내기 위해서 )
-
\(y_{i} \in\{B, I, O\}\).
(B: Beginning, I: Inside, O: Others)
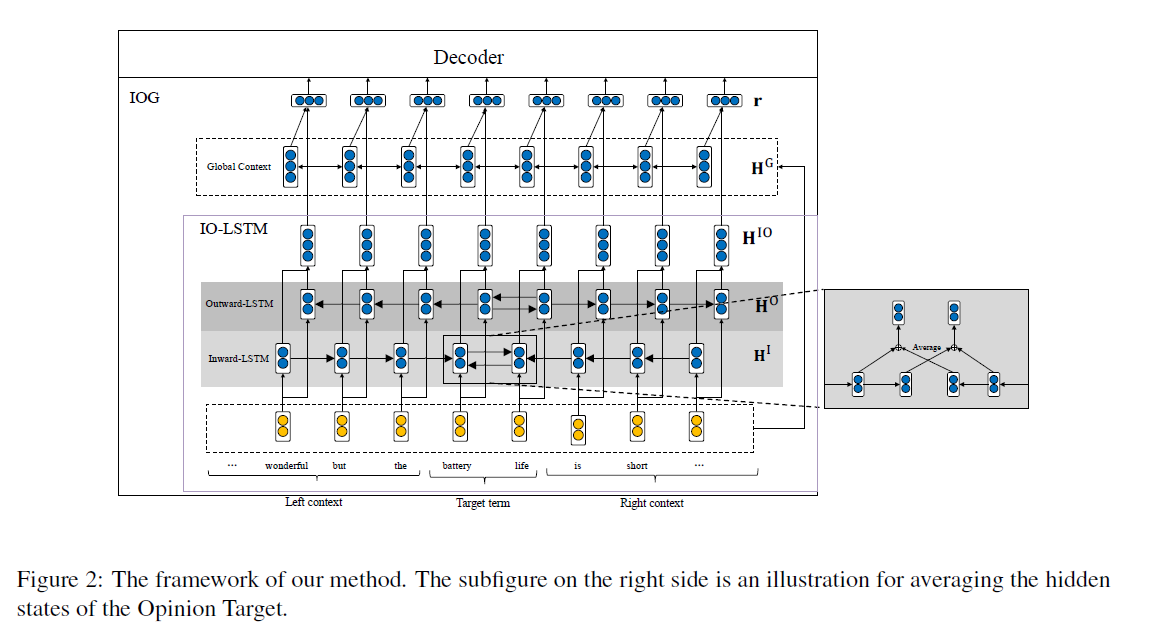
2-2) Framework
Propose a target-fused encoder
- to incorporate target information into context
- learn target-specific context representations
그런 뒤, decoder에 pass해서 sequence labeling을 수행한다
Model
- Encoder : Inward-Outward LSTM
- Decoder ( 2 different strategies )
2-3) Target-Fused Encoder
step 1) generate input vector
-
embedding lookup table \(\mathbb{L} \in \mathbb{R}^{d \times \mid V \mid }\) 사용해서
-
map \(s=\left\{w_{1}, w_{2}, \ldots, w_{t}, \ldots, w_{n}\right\}\)
into \(\left\{\mathbf{e}_{1}, \mathbf{e}_{2}, \cdots, \mathbf{e}_{i}, \ldots, \mathbf{e}_{n}\right\}\)
step 2) split sentence into 3 segments
- LEFT : \(\left\{w_{1}, w_{2}, \cdots, w_{l}\right\}\)
- TARGET : \(\left\{w_{l+1}, \cdots, w_{r-1}\right\}\)
- RIGHT : \(\left\{w_{r}, \cdots, w_{n}\right\}\)
step 3) left LSTM & right LSTM 사용하여 modeling
(a) Inward-LSTM
2개의 LSTM을 “양 끝에서부터 가운데 target으로 향하도록”
-
\(\begin{aligned} \mathbf{h}_{i}^{\mathrm{L}} &=\overrightarrow{\operatorname{LSTM}}\left(\mathbf{h}_{i-1}^{\mathrm{L}}, \mathbf{e}_{i}\right), \forall i \in[1, \cdots, r-1] \\ \mathbf{h}_{i}^{\mathrm{R}} &=\overleftarrow{\operatorname{LSTM}}\left(\mathbf{h}_{i+1}^{\mathrm{R}}, \mathbf{e}_{i}\right), \forall i \in[l+1, \cdots, n] \end{aligned}\).
-
이 둘을 average하여…
\[\mathbf{h}_{i}^{\mathrm{LR}}=\frac{\left(\mathbf{h}_{i}^{\mathrm{L}}+\mathbf{h}_{i}^{\mathrm{R}}\right)}{2}, \forall i \in[l+1, \cdots, r-1]\]
최종적인 context representation : \(\mathbf{H}^{\mathrm{I}}= \left\{\mathbf{h}_{1}^{\mathrm{L}}, \cdots, \mathbf{h}_{l}^{\mathrm{L}}, \mathbf{h}_{l+1}^{\mathrm{LR}}, \cdots, \mathbf{h}_{r-1}^{\mathrm{LR}}, \mathbf{h}_{r}^{\mathrm{R}}, \cdots, \mathbf{h}_{n}^{\mathrm{R}}\right\}\)
(b) Outward-LSTM
2개의 LSTM을 “가운데 target에서 양 끝을 향하도록”
- 위의 (a)와 마찬가지로 구한 뒤 average하기
(c) IO-LSTM = (a)+(b)
\(\mathbf{h}_{i}^{\mathrm{IO}}=\left[\mathbf{h}_{i}^{\mathrm{I}} ; \mathbf{h}_{i}^{\mathrm{O}}\right]\).
(d) IOG : IO-LSTM + Global context
whole sentence의 global meaning을 이해하는 것도 매우 중요!
따라서 global context를 도입한다!
( use BiLSTM to model whole sentence embeddings )
\(\begin{aligned} \mathbf{h}_{i}^{\mathrm{G}} &=\left[\overrightarrow{\mathbf{h}}_{i} ; \overleftarrow{\mathbf{h}_{i}}\right] \\ \overrightarrow{\mathbf{h}}_{i} &=\operatorname{LSTM}\left(\overrightarrow{\mathbf{h}}_{i-1}, \mathbf{e}_{i}\right) \\ \overleftarrow{\mathbf{h}}_{i} &=\operatorname{LSTM}\left(\overleftarrow{\mathbf{h}}_{i+1}, \mathbf{e}_{i}\right) \end{aligned}\).
final target-specific contextualized representation \(\mathrm{r}\) for each word:
- \(\mathbf{r}_{i}=\left[\mathbf{h}_{i}^{\mathrm{IO}} ; \mathbf{h}_{i}^{\mathrm{G}}\right]\).
2-4) Decoder & training
sequential representation \(r\) 을 사용하여
compute \(p(\mathbf{y} \mid \mathbf{r})\) where \(\mathbf{y}=\left\{y_{1}, \cdots, y_{n}\right\}\)
(a) (decoding 방법 1) Greedy decoding
-
Softmax : \(p\left(y_{i} \mid \mathbf{r}_{i}\right)=\operatorname{softmax}\left(\mathbf{W}_{s} \mathbf{r}_{i}+\mathbf{b}_{s}\right)\).
-
NLL : \(L(s)=-\sum_{i=1}^{n} \sum_{k=1}^{3} \mathbb{I}\left(y_{i}=k\right) \log p\left(y_{i}=k \mid w_{i}\right)\)
(b) (decoding 방법 2) CRF ( Conditional Random Field )
- correlations between tags 고려
- score the whole sequence of tags
\(p(\mathbf{y} \mid \mathbf{r})=\frac{\exp (s(\mathbf{r}, \mathbf{y}))}{\sum_{y^{\prime} \in Y} \exp \left(s\left(\mathbf{r}, \mathbf{y}^{\prime}\right)\right)}\).
\(Y\) : set of all possible tag sequences
\(s(\mathbf{r}, \mathbf{y})=\sum_{i}^{n}\left(\mathbf{A}_{y_{i-1}, y_{i}}+\mathbf{P}_{i, y_{i}}\right)\) : score function
- \(\mathbf{A}_{y_{i-1}, y_{i}}\) : transition score from \(y_{i-1}\) to \(y_{i}\)
- \(\mathbf{P}_{i}=\mathbf{W}_{s} \mathbf{r}_{i}+\mathbf{b}_{s}\).
Sentence에 대한 Loss로 NLL 사용 : \(L(s)=-\log p(\mathbf{y} \mid \mathbf{r})\)
최종 : minimize \(J(\theta)=\sum^{ \mid D \mid } L(s)\)