
Code Review for QACGBERT (Quasi-Attention Context-Guided BERT)
참고 : https://github.com/frankaging/Quasi-Attention-ABSA/blob/main/code/model/QACGBERT.py
1. Architecture
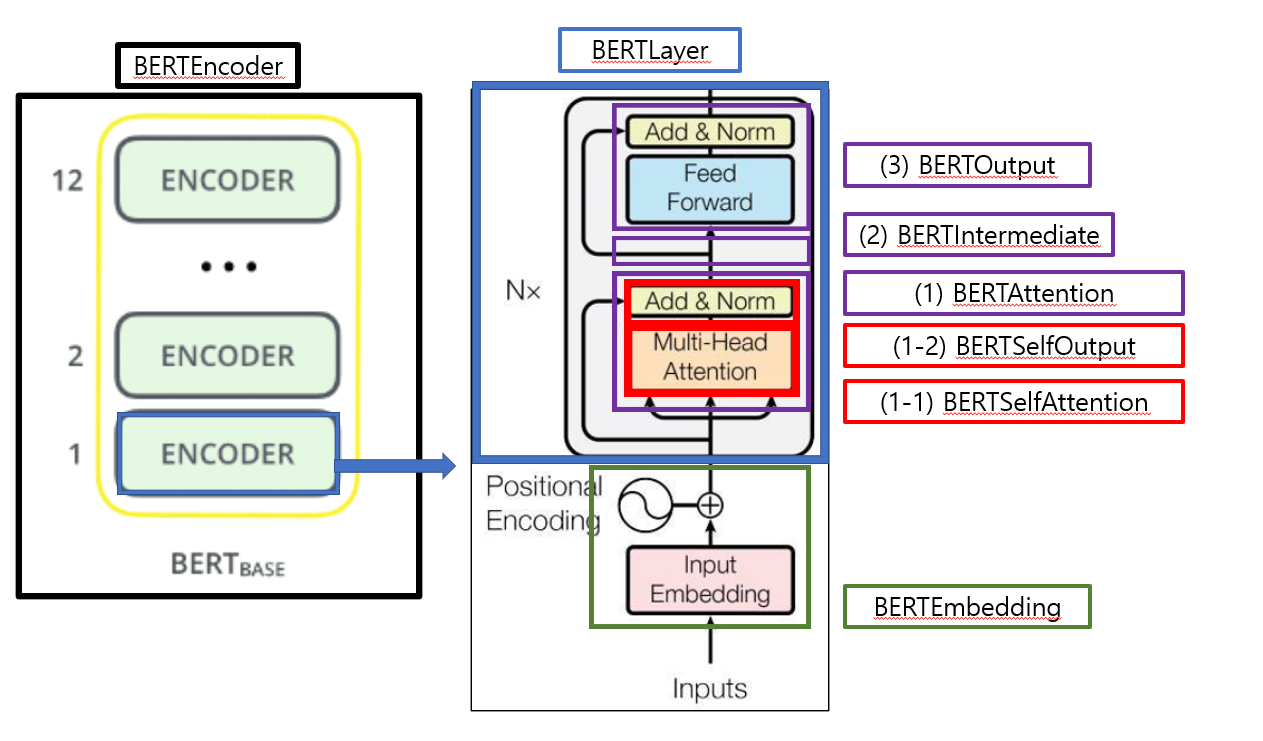
ContextBertModel
-
(1) BERTEmbedding
-
(2) Context BERTEncoder x N
- 2-1) Context BERT Attention
- a) Context BERT Self-Attention
- b) Context BERT Self-Output
- 2-2) BERT Intermediate
- 2-3) BERT Output
- 2-1) Context BERT Attention
2. Class & Function introduction
1) Main Modules
Model : ContextBertModel
-
BERT Embedding :
BERTEmbedding -
Encoder :
BERTEncoder- Bert layer :
BERTLayer- Attention :
BERTAttention- Context Self Attention :
BERTSelfAttention - Self Attention output :
BERTSelfOutput
- Context Self Attention :
- Intermediate layer :
BERTIntermediate - Output layer :
BERTOutput
- Attention :
- Bert layer :
2) Functions / Other Classes
- GeLU :
gelu - Layer Normalization :
BERTLayerNorm - Pooler :
BERTPooler
3. Code Review (with Pytorch)
3-1) Main Modules
ContextBertModel
전체적인 CGBERT의 알고리즘
( (큰 흐름에서) BERT와의 유일한 차이점 : Step3 )
-
Step 1) attention_mask : 패딩 마스크 생성
( 문장별로 단어 길이 다른것을 감안해주기 위함 )
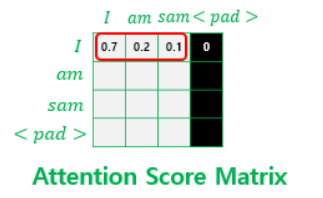
-
Step 2) 세 종류의 embedding을 더함
( 세 종류의 embedding은 아래에 구체적으로 설명 )
-
Step 3) Context를 embedding함 ( 8차원 \(\rightarrow\) hidden_size 차원)
-
Step 4) \(L\)개의 Encoder Layer를 통과
- 그 안에 Self Attention / FFNN 등으로 구성
-
Step 5) Pooling
class ContextBertModel(nn.Module):
def __init__(self, config: BertConfig):
super(ContextBertModel, self).__init__()
self.embeddings = BERTEmbeddings(config)
self.encoder = ContextBERTEncoder(config)
self.pooler = ContextBERTPooler(config)
self.context_embeddings = nn.Embedding(2*4, config.hidden_size)
def forward(self, input_ids, token_type_ids=None, attention_mask=None,device=None,ontext_ids=None):
if attention_mask is None:
attention_mask = torch.ones_like(input_ids)
if token_type_ids is None:
token_type_ids = torch.zeros_like(input_ids)
# Step 1) attention mask 생성
## 3D attention mask 생성 ( from 2D attention mask )
## mask의 size = [배치 크기, 1, 1, 문장 길이]
mask3d = attention_mask.unsqueeze(1).unsqueeze(2).float()
mask3d = (1.0 - mask3d) * -10000.0
# Step 2) 세 종류의 embedding을 더함
embedded = self.embeddings(input_ids, token_type_ids)
#-----------------------------------------------#
# Step 3) Context를 Embedding함
#-----------------------------------------------#
seq_len = embedding_output.shape[1]
C_embed = self.context_embeddings(context_ids).squeeze(dim=1)
embedded_c = torch.stack(seq_len*[C_embed], dim=1)
#---------------------------------------------------#
# Step 4) L개의 (Transformer) Encoder layer 를 거침
## 기존과의 차이점1) 단어 embedding & context embedding 둘 다 encoding됨
## 기존과의 차이점2) 여러 Attention (1,2,1+2)
all_encoder_layers, all_A_probs, all_A1_probs, all_A2_probs, all_lambda_context = self.encoder(embedded, mask3d,device,embedded_c)
# Step 5) (맨 마지막 L번째 layer output 제외하고) Pooling
layers_wo_last = all_encoder_layers[-1]
pooled_output = self.pooler(layers_wo_last, attention_mask)
return pooled_output, all_A_probs, all_A1_probs, all_A2_probs, all_lambda_context
BERT Embedding
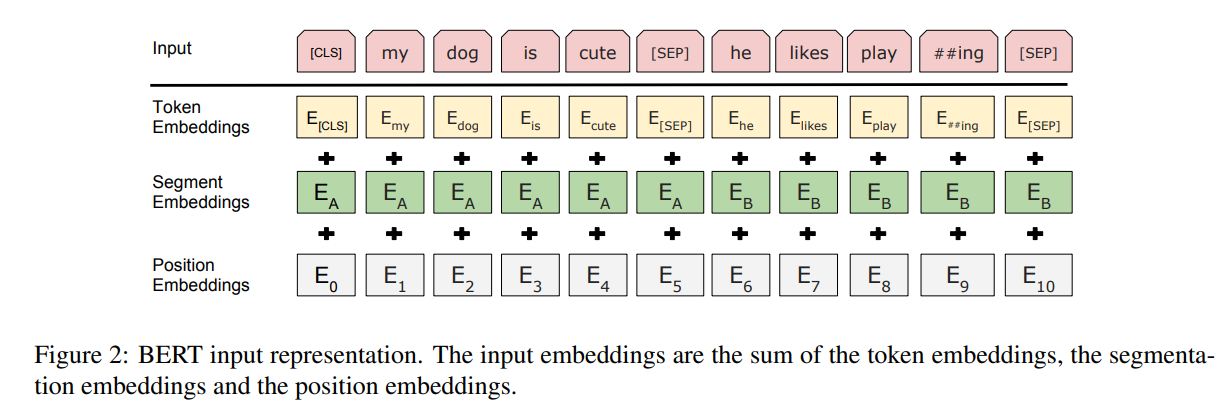
( BERT와 동일 )
class BERTEmbeddings(nn.Module):
def __init__(self, config):
super(BERTEmbeddings, self).__init__()
#-----------Embeddings--------------#
self.word_embeddings = nn.Embedding(config.vocab_size, config.hidden_size)
self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.hidden_size)
self.token_type_embeddings = nn.Embedding(config.type_vocab_size, config.hidden_size)
#----------- ETC --------------#
self.LayerNorm = BERTLayerNorm(config)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, input_ids, token_type_ids=None):
# (1) Position embedding을 위한 (문장의 token 길이만큼의) index 생성
seq_length = input_ids.size(1)
position_ids = torch.arange(seq_length, dtype=torch.long, device=input_ids.device)
position_ids = position_ids.unsqueeze(0).expand_as(input_ids)
if token_type_ids is None:
token_type_ids = torch.zeros_like(input_ids)
# (2) 세 종류의 Embedding을 더함
words_embeddings = self.word_embeddings(input_ids)
position_embeddings = self.position_embeddings(position_ids)
token_type_embeddings = self.token_type_embeddings(token_type_ids)
embeddings = words_embeddings + position_embeddings + token_type_embeddings
# (3) Layer Normalization + Dropout
embeddings = self.LayerNorm(embeddings)
embeddings = self.dropout(embeddings)
return embeddings
Context BERT Encoder
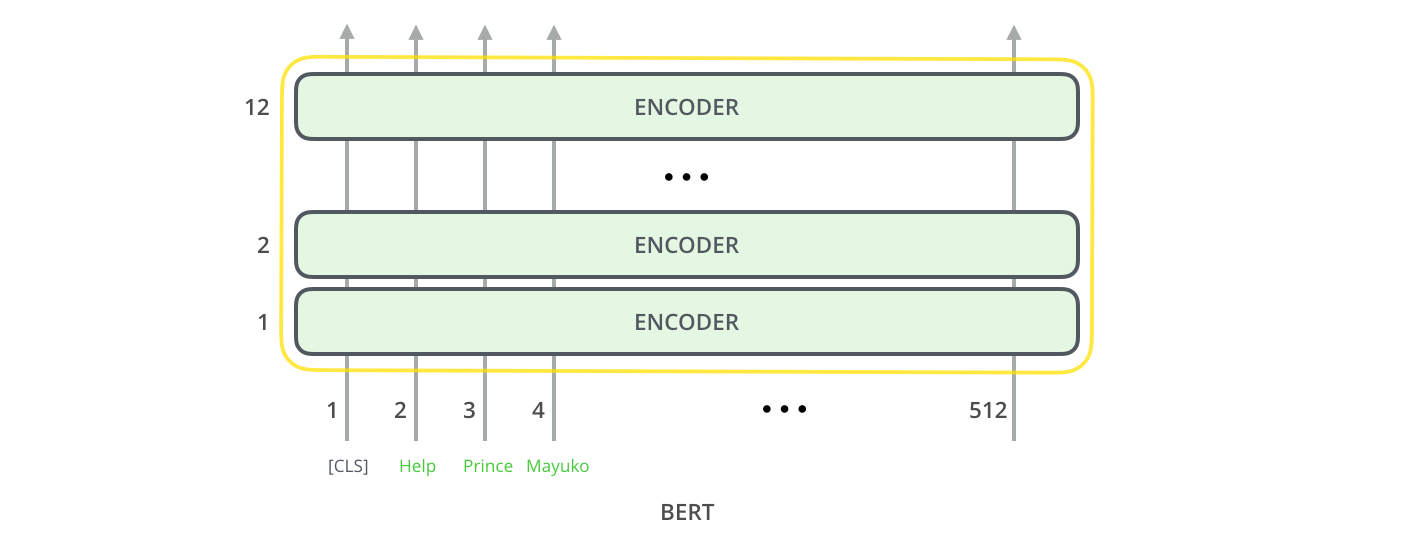
( Context를 Encoding하는 layer가 추가된 것 외에는 전부 동일 )
deep_context_transform_layer가 추가됨
( 여러 종류의 Attention )
class ContextBERTEncoder(nn.Module):
def __init__(self, config):
super(ContextBERTEncoder, self).__init__()
# (1) 일반 Layer
layer = ContextBERTLayer(config)
self.layer = nn.ModuleList([copy.deepcopy(layer) for _ in range(config.num_hidden_layers)])
# (2) Context Layer
layer_c = nn.Linear(2*config.hidden_size, config.hidden_size)
self.context_layer = nn.ModuleList([copy.deepcopy(layer_c) for _ in range(config.num_hidden_layers)])
def forward(self, hidden_states, attention_mask,
device=None, context_embeddings=None):
all_encoder_layers = []
all_A_probs = []
all_A1_probs = []
all_A2_probs = []
all_lambda_context = []
layer_index = 0
for layer_module in self.layer:
# update context
## 출력된 C_embed의 크기 : (batch_size, seq_len, d_hidden).
deep_context_hidden = torch.cat([context_embeddings, hidden_states], dim=-1)
deep_context_hidden = self.context_layer[layer_index](deep_context_hidden)
deep_context_hidden += context_embeddings
# BERT encoding
hidden_states, A_probs, attention_probs, quasi_attention_prob, lambda_context = layer_module(hidden_states, attention_mask,device, deep_context_hidden)
all_encoder_layers.append(hidden_states)
all_A_probs.append(A_probs.clone())
all_A1_probs.append(attention_probs.clone())
all_A2_probs.append(quasi_attention_prob.clone())
all_lambda_context.append(lambda_context.clone())
layer_index += 1
return all_encoder_layers,all_A_probs, all_A1_probs, all_A2_probs, all_lambda_context
[A] Context BERT Layer
( BERTAttention 대신 ContextBERTAttention을 사용한 사실 외에는 전부 동일 )
class ContextBERTLayer(nn.Module):
def __init__(self, config):
super(ContextBERTLayer, self).__init__()
#-----------------------------------------------#
self.attention = ContextBERTAttention(config) # (Step 1)
#-----------------------------------------------#
self.intermediate = BERTIntermediate(config) # (Step 2)
self.output = BERTOutput(config) # (Step 3)
def forward(self, hidden_states, attention_mask,
device=None, C_embed=None):
attention_output, A_probs, A1_probs, A2_probs, lambda_context = self.attention(hidden_states, attention_mask,device, C_embed)
intermediate_output = self.intermediate(attention_output)
layer_output = self.output(intermediate_output, attention_output)
return layer_output, A_probs, A1_probs, A2_probs, lambda_context
[A-1] Context BERT Attention
class ContextBERTAttention(nn.Module):
def __init__(self, config):
super(ContextBERTAttention, self).__init__()
#-----------------------------------------------#
self.self = ContextBERTSelfAttention(config) # (Step 1)
#-----------------------------------------------#
self.output = BERTSelfOutput(config) # (Step 2)
def forward(self, input_tensor, attention_mask,device=None, C_embed=None):
self_output, A_probs, A1_probs, A2_probs, lambda_context = self.self.forward(input_tensor, attention_mask,device, C_embed)
attention_output = self.output(self_output, input_tensor)
return attention_output, A_probs, A1_probs, A2_probs, lambda_context
[A-1-a] Self Attention
[ New attention matrix ] :
- linear combination of regular softmax attention matrix & quasi-attention matrix
- (논문) \(\hat{\mathbf{A}}^{h}=\mathbf{A}_{\text {Self-Attn }}^{h}+\lambda_{A}^{h} \mathbf{A}_{\text {Quasi-Attn }}^{h}\).
- (코드 구현) \(\hat{\mathbf{A}}^{h}=\mathbf{A}_{\text {Quasi-Attn }}^{h}\)
\(\mathbf{A}_{\text {Quasi-Attn }}^{h}\)를 어떻게 구할까?
- quasi-context query \(\mathrm{C}_{Q}^{h}\)
- quasi-context key \(\mathbf{C}_{K}^{h}\) 구하기
\(\left[\begin{array}{c} \mathbf{C}_{Q}^{h} \\ \mathbf{C}_{K}^{h} \end{array}\right]=\mathbf{C}^{h}\left[\begin{array}{l} \mathbf{Z}_{Q} \\ \mathbf{Z}_{K} \end{array}\right]\).
Quasi-attention matrix ( \(\mathbf{A}_{\text {Quasi-Attn }}^{h}\) ) :
\(\mathbf{A}_{Q u a s i-\mathrm{Att} n}^{h}=\alpha \cdot \operatorname{sigmoid}\left(\frac{f_{\psi}\left(\mathbf{C}_{Q}^{h}, \mathbf{C}_{K}^{h}\right)}{\sqrt{d_{h}}}\right)\).
- \(\alpha\) : scaling factor … 1로 사용할 것임
- \(f_{\psi}(\cdot)\) : similarity measure ( \(Q\) 와 \(V\) 사이의 ) …. dot product로 사용할 것임
- 따라서, \(\mathbf{A}_{\text {Quasi-Attn }}^{h}\) 는 0~1사이 값
( 아래 내용은 코드에서는 반영되지 않은, Paper 상의 내용 )
그런 뒤 bidirectional gating factor \(\lambda_A\)를 아래와 같이 설정
\(\begin{gathered} {\left[\begin{array}{c} \lambda_{Q}^{h} \\ \lambda_{K}^{h} \end{array}\right]=\operatorname{sigmoid}\left(\left[\begin{array}{c} \mathbf{Q}^{h} \\ \mathbf{K}^{h} \end{array}\right]\left[\begin{array}{c} \mathbf{V}_{Q}^{h} \\ \mathbf{V}_{K}^{h} \end{array}\right]+\left[\begin{array}{c} \mathbf{C}_{Q}^{h} \\ \mathbf{C}_{K}^{h} \end{array}\right]\left[\begin{array}{c} \mathbf{V}_{Q}^{C} \\ \mathbf{V}_{K}^{C} \end{array}\right]\right)} \\ \lambda_{A}^{h}=1-\left(\beta \cdot \lambda_{Q}^{h}+\gamma \cdot \lambda_{K}^{h}\right) \end{gathered}\).
- \(\lambda_{Q}^{h}\) 와 \(\lambda_{K}^{h}\) 가 head 마다 다를 수 있게 함
- \(\beta=1\), \(\gamma=1\)로 설정
-
따라서, \(\lambda_A\)는 0~1사이
- 최종적인 Attention \(\hat{\mathbf{A}}\)는 -1~2사이에 놓이게 되어있다!
class ContextBERTSelfAttention(nn.Module):
def __init__(self, config):
super(ContextBERTSelfAttention, self).__init__()
self.num_attention_heads = config.num_attention_heads
self.attention_head_size = int(config.hidden_size / config.num_attention_heads)
self.all_head_size = self.num_attention_heads * self.attention_head_size
## (1) Weight (matrices)
self.Wq = nn.Linear(config.hidden_size, self.all_head_size)
self.Wk = nn.Linear(config.hidden_size, self.all_head_size)
self.Wv = nn.Linear(config.hidden_size, self.all_head_size)
self.Wcq = nn.Linear(self.attention_head_size, self.attention_head_size)
self.Wck = nn.Linear(self.attention_head_size, self.attention_head_size)
## (2) Lambda (scalar)
self.lambda_Qc = nn.Linear(self.attention_head_size, 1, bias=False)
self.lambda_Q = nn.Linear(self.attention_head_size, 1, bias=False)
self.lambda_Kc = nn.Linear(self.attention_head_size, 1, bias=False)
self.lambda_K = nn.Linear(self.attention_head_size, 1, bias=False)
## (3) Dropout & activation
self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
self.lambda_act = nn.Sigmoid()
self.quasi_act = nn.Sigmoid()
def transpose_for_scores(self, x):
new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
x = x.view(*new_x_shape)
return x.permute(0, 2, 1, 3)
def forward(self, hidden_states, attention_mask,device=None, C_embed=None):
#-------------------------------#
Q = self.transpose_for_scores(self.Wq(hidden_states))
K = self.transpose_for_scores(self.Wk(hidden_states))
V = self.transpose_for_scores(self.Wv(hidden_states))
#-------------------------------#
Qc = self.transpose_for_scores(self.Wcq(C_embed))
Qc = self.dropout(Qc)
Kc = self.transpose_for_scores(self.Wck(C_embed))
Kc = self.dropout(Kc)
#-------------------------------#
#----------------------------------------------------------#
# [STEP 1] Attention (일반) 계산하기
#----------------------------------------------------------#
A_score = torch.matmul(Q, K.transpose(-1, -2))
A_score = A_score / math.sqrt(self.attention_head_size)
A_score = A_score + attention_mask
A1 = nn.Softmax(dim=-1)(A_score) # [0, 1]
#----------------------------------------------------------#
# [STEP 2] Attention (Quasi) 계산하기
#----------------------------------------------------------#
A_quasi_score = torch.matmul(Qc, Kc.transpose(-1, -2))
A_quasi_score = A_quasi_score / math.sqrt(self.attention_head_size)
A_quasi_score = A_quasi_score + attention_mask
quasi_scalar = 1.0
A_quasi_score = 1.0 * quasi_scalar * self.quasi_act(A_quasi_score) # [-1, 0]
#----------------------------------------------------------#
# [STEP 3] Quasi-gated control 계산하기
#----------------------------------------------------------#
## (1) lambda_Q
lambda_Q1 = self.lambda_Q(Q)
lambda_Q2 = self.lambda_Qc(Qc)
lambda_Q = self.quasi_act(lambda_Q1 + lambda_Q2)
## (2) lambda_K
lambda_K1 = self.lambda_K(K)
lambda_K2 = self.lambda_Kc(Kc)
lambda_K = self.quasi_act(lambda_K1 + lambda_K2)
## (3) Linear Combination
lambda_Q_scalar = 1.0
lambda_K_scalar = 1.0
lambda_context = lambda_Q_scalar*lambda_Q + lambda_K_scalar*lambda_K
lambda_context = (1 - lambda_context)
A2 = lambda_context * A_quasi_score
#----------------------------------------------------------#
# [STEP 4] 최종 Attention 계산
# ( 일반 Attention & Quasi Attention 조합 )
#----------------------------------------------------------#
A = A1 + A2
A = self.dropout(A)
#----------------------------------------------------------#
# [STEP 5] context layer 계산하기 ( A x V )
#----------------------------------------------------------#
context_layer = torch.matmul(A, V)
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
context_layer = context_layer.view(*new_context_layer_shape)
return context_layer, A, A1, A2, lambda_context
[A-1-b] Self Attention Output
( BERT와 동일 )
class BERTSelfOutput(nn.Module):
def __init__(self, config):
super(BERTSelfOutput, self).__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.LayerNorm = BERTLayerNorm(config)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, hidden_states, input_tensor):
hidden_states = self.dense(hidden_states)
hidden_states = self.dropout(hidden_states)
hidden_states = self.LayerNorm(hidden_states + input_tensor)
return hidden_states
[A-2] Intermediate Layer
- ( BERT와 동일 )
class BERTIntermediate(nn.Module):
def __init__(self, config):
super(BERTIntermediate, self).__init__()
self.dense = nn.Linear(config.hidden_size, config.intermediate_size)
self.intermediate_act_fn = gelu
def forward(self, hidden_states):
hidden_states = self.dense(hidden_states)
hidden_states = self.intermediate_act_fn(hidden_states)
return hidden_states
[A-3] Output Layer
( BERT와 동일 )
class BERTOutput(nn.Module):
def __init__(self, config):
super(BERTOutput, self).__init__()
self.dense = nn.Linear(config.intermediate_size, config.hidden_size)
self.LayerNorm = BERTLayerNorm(config)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, hidden_states, input_tensor):
hidden_states = self.dense(hidden_states)
hidden_states = self.dropout(hidden_states)
hidden_states = self.LayerNorm(hidden_states + input_tensor)
return hidden_states
3-2) Functions / Other Classes
GeLU
\(\operatorname{GELU}(x)=0.5 x\left(1+\tanh \left(\sqrt{2 / \pi}\left(x+0.044715 x^{3}\right)\right)\right)\).
def gelu(x):
return x * 0.5 * (1.0 + torch.erf(x / math.sqrt(2.0)))
Layer Normalization
( BERT와 동일 )
- \(\gamma\) : scaling parameter / \(\beta\) : shift parameter
class BERTLayerNorm(nn.Module):
def __init__(self, config, variance_epsilon=1e-12):
super(BERTLayerNorm, self).__init__()
self.gamma = nn.Parameter(torch.ones(config.hidden_size))
self.beta = nn.Parameter(torch.zeros(config.hidden_size))
self.variance_epsilon = variance_epsilon
def forward(self, x):
mu = x.mean(-1, keepdim=True)
std = (x - mu).pow(2).mean(-1, keepdim=True)
x = (x - mu) / torch.sqrt(std + self.variance_epsilon)
return self.gamma * x + self.beta
ContextBERTPooler
- (구 BERT의 Pooling) 첫번째 [CLS] 토큰만을 대상으로 수행
- (CGBERT의 Pooling) local context attention mechanism
- + Dense Layer & Activation Function을 거처서 출력됨
class ContextBERTPooler(nn.Module):
def __init__(self, config):
super(ContextBERTPooler, self).__init__()
self.attention_gate = nn.Sequential(nn.Linear(config.hidden_size, 32),
nn.ReLU(),
nn.Dropout(config.hidden_dropout_prob),
nn.Linear(32, 1))
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.activation = nn.Tanh()
def forward(self, hidden_states, attention_mask):
#----------- 일반 BERT와는 다른 Pooling -------------#
# In pooling, we are using a local context attention mechanism
attn_scores = self.attention_gate(hidden_states)
extended_attention_mask = attention_mask.unsqueeze(dim=-1)
attn_scores = attn_scores.masked_fill(extended_attention_mask == 0, -1e9)
attn_scores = F.softmax(attn_scores, dim=1)
hs_pooled = torch.matmul(attn_scores.permute(0,2,1), hidden_states).squeeze(dim=1)
#---------------------------------------------------#
pooled_output = self.dense(hs_pooled)
pooled_output = self.activation(pooled_output)
return pooled_output
[ Configuration ]
Configuration class to store the configuration of a BertModel
( 괄호 안의 값은 default 값 )
- vocab_size : Vocabulary의 개수 (32000)
- hidden_size : encoder layers and the pooler layer의 hidden dimension (768)
- num_hidden_layers : Encoder의 hidden layer의 개수 (12)
- num_attention_heads : attention head의 개수 (12)
- intermediate_size : intermediate layer (FFNN)의 dimension (3072)
- hidden_act : encoder ( & pooler )에서 사용되는 activation function (gelu)
- hidden_dropout_prob : dropout probability (0.1)
- max_position_embeddings : 최대 문장 길이 (512)
- type_vocab_size : token_type_ids의 vocab 개수 (16)
- initializer_range : weight를 initialize할때의 사용하는 Truncated Normal distn의 standard deviation (0.02)
class BertConfig(object):
def __init__(self,
vocab_size=32000,
hidden_size=768,
num_hidden_layers=12,
num_attention_heads=12,
intermediate_size=3072,
hidden_act="gelu",
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
max_position_embeddings=512,
type_vocab_size=16,
initializer_range=0.02,
full_pooler=False):
self.vocab_size = vocab_size
self.hidden_size = hidden_size
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
self.hidden_act = hidden_act
self.intermediate_size = intermediate_size
self.hidden_dropout_prob = hidden_dropout_prob
self.attention_probs_dropout_prob = attention_probs_dropout_prob
self.max_position_embeddings = max_position_embeddings
self.type_vocab_size = type_vocab_size
self.initializer_range = initializer_range
self.full_pooler = full_pooler
#-----------------------------------------------------------#
# Configuration을 [dictionary] 형태로 받은 뒤 Setting하기
#-----------------------------------------------------------#
## [ Dictionary ] 형태
@classmethod
def from_dict(cls, json_object):
config = BertConfig(vocab_size=None)
for (key, value) in six.iteritems(json_object):
config.__dict__[key] = value
return config
## [ Json ] 형태
@classmethod
# Configuration을 dictionary형태로 받은 뒤 Setting하기
def from_json_file(cls, json_file):
with open(json_file, "r") as reader:
text = reader.read()
return cls.from_dict(json.loads(text))
def to_dict(self):
output = copy.deepcopy(self.__dict__)
return output
def to_json_string(self):
return json.dumps(self.to_dict(), indent=2, sort_keys=True) + "\n"
4. Sequence Classification
- ex) BIO Tagging, TO Tagging
- for AE (Aspect Extraction)
- lambda context : $\lambda_{A}^{h}=1-\left(\beta \cdot \lambda_{Q}^{h}+\gamma \cdot \lambda_{K}^{h}\right)$
class QACGBertForSequenceClassification(nn.Module):
"""Proposed Context-Aware Bert Model for Sequence Classification
"""
def __init__(self, config, num_labels, init_weight=False, init_lrp=False):
super(QACGBertForSequenceClassification, self).__init__()
self.bert = ContextBertModel(config)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
self.classifier = nn.Linear(config.hidden_size, num_labels)
self.num_head = config.num_attention_heads
self.config = config
####################################################
# -------------- Weight Initialiation ------------ #
if init_weight:
print("init_weight = True")
def init_weights(module):
# [weight 1] NN의 기본 parameter ....( N(0,sigma^2) )
if isinstance(module, (nn.Linear, nn.Embedding)):
module.weight.data.normal_(mean=0.0, std=config.initializer_range)
# [weight 2] Layer Normalization의 parameter ( gamma & beta ) ... ( N(0,sigma^2) )
elif isinstance(module, BERTLayerNorm):
module.beta.data.normal_(mean=0.0, std=config.initializer_range)
module.gamma.data.normal_(mean=0.0, std=config.initializer_range)
# [weight 3] bias ...... ( zero )
if isinstance(module, nn.Linear):
if module.bias is not None:
module.bias.data.zero_()
self.apply(init_weights)
perturb = 1e-2
for layer in self.bert.encoder.layer:
layer.attention.self.lambda_Qc.weight.data.normal_(mean=0.0, std=perturb)
layer.attention.self.lambda_Kc.weight.data.normal_(mean=0.0, std=perturb)
layer.attention.self.lambda_Q.weight.data.normal_(mean=0.0, std=perturb)
layer.attention.self.lambda_K.weight.data.normal_(mean=0.0, std=perturb)
####################################################
if init_lrp:
print("init_lrp = True")
init_hooks_lrp(self)
def forward(self, input_ids, token_type_ids, attention_mask, seq_lens,
device=None, labels=None,context_ids=None):
# (1) BERT의 output
### pooled 결과, Attention (1+2, 1, 2), lambda context
pooled_output, all_A_probs, all_A1_probs, all_A2_probs, all_lambda_context = \
self.bert(input_ids, token_type_ids, attention_mask,device, context_ids)
# (2) Classification Result
pooled_output = self.dropout(pooled_output)
logits = self.classifier(pooled_output)
### (2-1) label 존재 O 시 : 예측값 + Loss & Attention 반환
if labels is not None:
loss_fct = CrossEntropyLoss()
loss = loss_fct(logits, labels)
return loss, logits, all_A_probs, all_A1_probs, all_A2_probs, all_lambda_context
### (2-1) label 존재 X 시 : 예측값 반환
else:
return logits
def backward_gradient(self, sensitivity_grads):
classifier_out = func_activations['model.classifier']
embedding_output = func_activations['model.bert.embeddings']
sensitivity_grads = torch.autograd.grad(classifier_out, embedding_output,
grad_outputs=sensitivity_grads)[0]
return sensitivity_grads