
( 참고 : Fastcampus 강의 )
[ 35. (paper 1) DQN (Deep Q-Network) code review 2 ]
1. Import Packages
import sys; sys.path.append('..')
import torch
import gym
from src.part3.MLP import MultiLayerPerceptron as MLP
from src.part5.DQN import DQN, prepare_training_inputs
from src.common.memory.memory import ReplayMemory
from src.common.train_utils import to_tensor
2. DQN (Deep Q-Network) 알고리즘
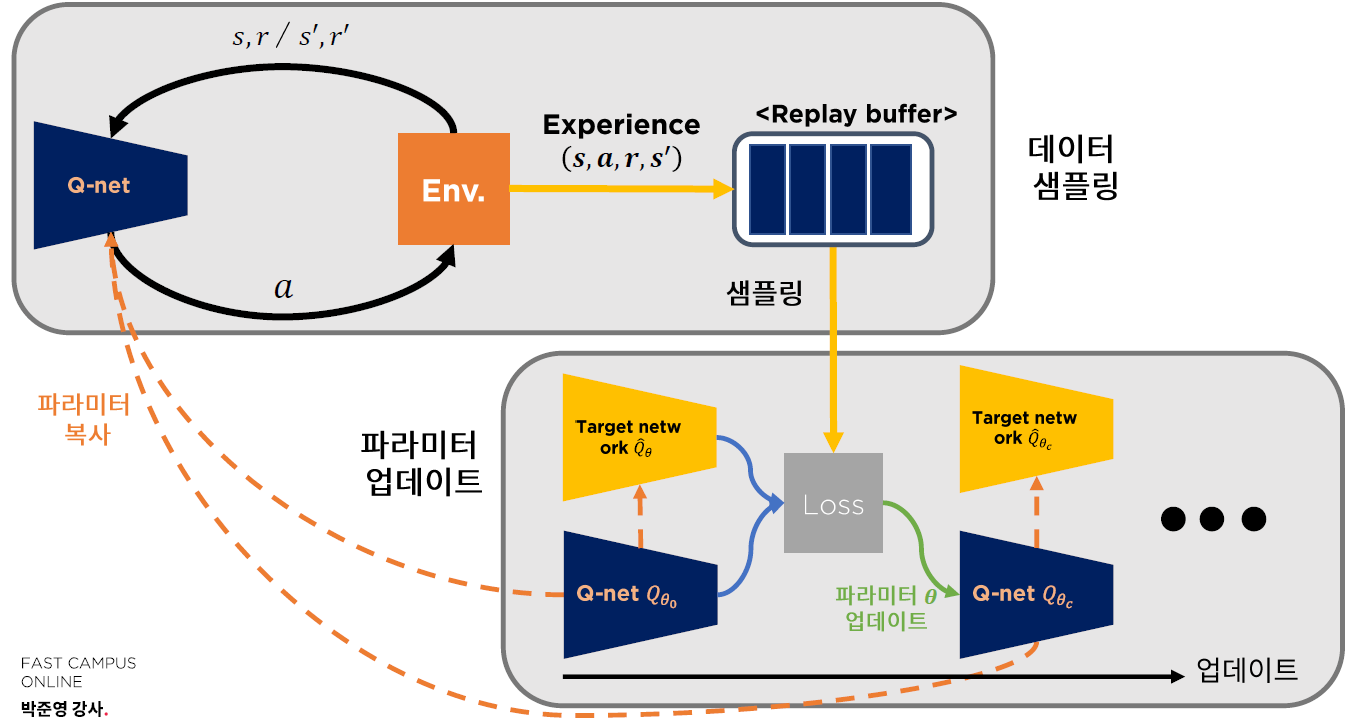
Batch Update
\(\theta \leftarrow \theta + \eta \frac{\partial \frac{1}{m}\sum_{i=1}^{m}\mathcal{L}(s_i, a_i, r_i, s_i^{'})}{\partial \theta}\),
Loss Function
\(\mathcal{L}(s_i, a_i, r_i, s_i^{'}) = \mid r_i+\gamma \max_{a'} Q_\theta(s_i^{'},a')-Q_\theta(s_i, a_i) \mid _2\).
where \((s_i, a_i, r_i, s_i^{'}) \sim \mathcal{D}\).
3. DQN model
state_dim: input state의 차원 ( ex. 8x8 =64 grid )action_dim: action의 차원(가능한 가지 수) ( ex. 상/하/좌/우 \(\rightarrow\) 4 )qnet: Q-network ( NN )qnet_target: Target Networklr: learning rategamma: discount factor (감가율)epsilon: epsilon-greedy의 \(\epsilon\)
class DQN(nn.Module):
def __init__(self,
state_dim: int,
action_dim: int,
qnet: nn.Module,
qnet_target: nn.Module,
lr: float,
gamma: float,
epsilon: float):
super(DQN, self).__init__()
self.state_dim = state_dim
self.action_dim = action_dim
self.qnet = qnet
self.qnet_target = qnet_target
self.lr = lr
self.gamma = gamma
self.opt = torch.optim.Adam(params=self.qnet.parameters(), lr=lr)
self.register_buffer('epsilon', torch.ones(1) * epsilon)
self.criteria = nn.SmoothL1Loss()
#------- epsilon greedy----------#
def get_action(self, state):
qs = self.qnet(state)
prob = np.random.uniform(0.0, 1.0, 1)
if torch.from_numpy(prob).float() <= self.epsilon: # (case1) random
action = np.random.choice(range(self.action_dim))
else: # (case2) greedy
action = qs.argmax(dim=-1)
return int(action)
#------- Update (SGD) ----------#
def update(self, s, a, r, s_, d):
## [Y] Target Network로부터 target 계산하기 ( moving target 이슈 해결 )
with torch.no_grad():
q_max, _ = self.qnet_target(s_).max(dim=-1, keepdims=True)
q_target = r + self.gamma * q_max * (1 - d)
## [Y hat] Q-Network의 예측값
q_val = self.qnet(s).gather(1, a)
## Loss 계산 ( Smooth L1 Loss)
loss = self.criteria(q_val, q_target)
self.opt.zero_grad()
loss.backward()
self.opt.step()
Smooth L1 Loss
self.criteria = nn.SmoothL1Loss()
\(loss(x,y) = \frac{1}{n}\sum_i z_i\).
- \(\mid x_i - y_i \mid <1\) 일때, \(z_i = 0.5(x_i - y_i)^2\)
- \(\mid x_i - y_i \mid \geq1\) 일때, \(z_i = \mid x_i - y_i \mid -0.5\)
4. Experinece Replay ( Replay Memory )
- experience에서 얻은 값들 (sample들)을 저장하는 공간
- 학습을 위해 이 Memory에서 일부를 sampling한다
from random import sample
class ReplayMemory:
def __init__(self, max_size):
self.buffer = [None] * max_size # Memory의 최대 저장 공간
self.max_size = max_size
self.index = 0
self.size = 0
# Memory에 expereince를 집어넣음
def push(self, obj):
self.buffer[self.index] = obj
self.size = min(self.size + 1, self.max_size)
self.index = (self.index + 1) % self.max_size
# Memory에 저장된 expereince들을 sampling
def sample(self, batch_size):
indices = sample(range(self.size), batch_size)
return [self.buffer[index] for index in indices]
# 현재 Memory에 차 있는 용량
def __len__(self):
return self.size
5. Training
(1) Hyperparameters
- 최대 (Experinece Replay의) 메모리 공간 : 50,000
- Replay Memory에 2,000개 이상의 sample이 쌓이면 학습 시작
- epsilon-greedy의 \(\epsilon\)을 서서히 decay시킬 것
- max : 0.08 ~ min : 0.01
- 총 epsiode 횟수 : 3,000
- target network를 갱신하는 횟수 빈도 (\(C\) ) = 10
- 매 100 step마다 결과값 출력
lr = 1e-4 * 5
batch_size = 256
gamma = 1.0
memory_size = 50000
total_eps = 3000
eps_max = 0.08
eps_min = 0.01
sampling_only_until = 2000
target_update_interval = 10
print_every = 100
(2) Load Models
두 개의 NN을 설정
- 1) Q-network
qnet - 2) Target-Network
qnet_target
qnet_target의 파라미터 <- qnet의 파라미터
qnet = MLP(4, 2, num_neurons=[128])
qnet_target = MLP(4, 2, num_neurons=[128])
qnet_target.load_state_dict(qnet.state_dict())
agent = DQN(4, 1, qnet=qnet, qnet_target=qnet_target, lr=lr, gamma=gamma, epsilon=1.0)
환경과 Replay memory 생성
env = gym.make('CartPole-v1')
memory = ReplayMemory(memory_size)
for n_epi in range(total_eps):
epsilon = max(eps_min, eps_max - eps_min * (n_epi / 200))
agent.epsilon = torch.tensor(epsilon) # exploration을 위한 epsilon
s = env.reset()
cum_r = 0 # cumulative reward
#------ 하나의 epsiode가 끝날때 까지 반복 --------- #
while True:
s = to_tensor(s, size=(1, 4))
a = agent.get_action(s)
s_, r, d, info = env.step(a)
experience = (s,
torch.tensor(a).view(1, 1),
torch.tensor(r / 100.0).view(1, 1),
torch.tensor(s_).view(1, 4),
torch.tensor(d).view(1, 1))
memory.push(experience) # Replay Memory에 저장하기
s = s_
cum_r += r
if done:
break
#-------------------------------------------------#
#---- 2,000개 이상의 sample이 쌓이면 Train 시작 -----#
if len(memory) >= sampling_only_until:
sampled_exps = memory.sample(batch_size)
sampled_exps = prepare_training_inputs(sampled_exps)
agent.update(*sampled_exps)
#-------------------------------------------------#
#---- 매 10 step마다 Target Network를 Q Network로 동기화 -----#
if n_epi % target_update_interval == 0:
qnet_target.load_state_dict(qnet.state_dict())
#----------------------------------------------------------#
if n_epi % print_every == 0:
msg = (n_epi, cum_r, epsilon)
print("Episode : {:4.0f} | Cumulative Reward : {:4.0f} | Epsilon : {:.3f}".format(*msg))