
[ Recommender System ]
17. Training Deep AutoEncoder for Collaborative Filtering
( 참고 : Fastcampus 추천시스템 강의 )
paper : Training Deep AutoEncoder for Collaborative Filtering ( Kuchaiev and Ginsburg, 2017 )
( https://arxiv.org/abs/1708.01715 )
Abstract
- Deep 할 수록 generalization 성능 \(\uparrow\) ( 6 layer사용 & end-to-end )
-
Negative parts를 포함한 non-linear activation function 중요!
- Regularization ( ex. dropout )을 사용하여 overfitting 방지
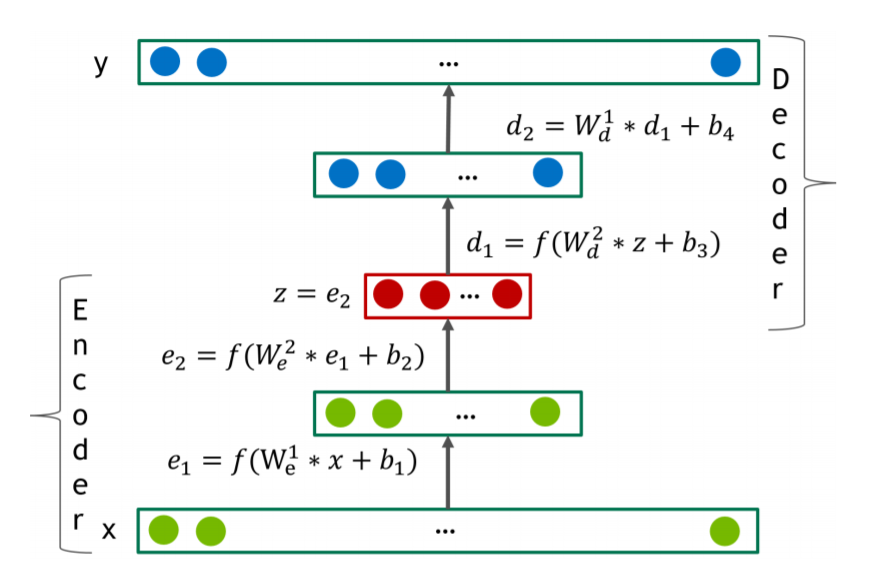
1. Model
Loss Function : \(M M S E=\frac{m_{i} *\left(r_{i}-y_{i}\right)^{2}}{\sum_{i=0}^{i=n} m_{i}}\)
- MMSE = Rating이 “있는” 것만을 loss 고려 + MSE
- \(m_i=0\) if rating=0, o.w = 1
- \(y_i\) = predictied rating
Dense re-feeding ( 다음의 순서로 진행 )
- (sparse한) \(x\) & \(f(x)\) 로 loss 계산………….first forward pass
- back prop
- \(f(x)\)로 \(f(f(x))\)를 구함 ( 둘 다 dense matrix ) ……….. second forward pass
- back prop