
[ Recommender System ]
( 참고 : Fastcampus 추천시스템 강의 )
6. [code] 간단한 추천 시스템
-
랜덤으로 평점 예측하기
-
영화 평균 평점기반 예측하기
-
사용자 평균 평점기반 예측하기
-
Rule기반 영화 랭킹 예측하기
데이터 소개
- Movie Lens data
- Train ) (80068, 4) Test ) (20168, 4)
1. 랜덤으로 평점 예측하기
- 평점이 가질 수 있는 값인 0.5 , 1.0 , … ,5.0 중 랜덤하게 선택하여 예측한다
ratings_range = np.arange(0.5, 5.5, step=0.5)
pred_random = [np.random.choice(ratings_range) for x in range(len(test_df))]
test_df['pred_ratings_random'] = pred_random
2. 영화 평균 평점 기반 예측하기
avg_rating_prediction:- if 특정 영화/유저에 대한 평점이 train set에 있었다면 :해당 값들의 “평균”으로
- else : 1번 방법처럼 random하게 고르기
def avg_rating_prediction(training_set, x):
if x in training_set.index:
pred_rating = training_set.loc[x]['rating']
else:
pred_rating = np.random.choice(ratings_range)
return pred_rating
- ex) “스파이더맨4”를 본 8000여명의 사람들의 평점 평균이 3.87이었다면, 해당 값(3.87)로 예측하기
train_movie_df = train_df.groupby('movieId').mean()
test_df['pred_rating_movie'] = test_df['movieId'].apply(lambda x: avg_rating_prediction(train_movie_df, x))
3. 사용자 평균 평점기반 예측하기
- ex) “이승한”이 여태까지 본 영화들 80편에 대한 평균 평점이 4.24였다면, 이승한이 볼 새로운 영화에 대한 평점 예측도 4.24로!
train_user_df = train_df.groupby('userId').mean()
test_df['pred_rating_user'] = test_df['userId'].apply(lambda x: avg_rating_prediction(train_user_df, x))
4. Rule기반 영화 랭킹 예측하기
train set에 포함된 유저의 영화 평균 평점과 영화의 장르를 활용하여, 장르별 평균 평점 계산
\(\rightarrow\) test set의 영화 장르의 평균 평점으로 예측
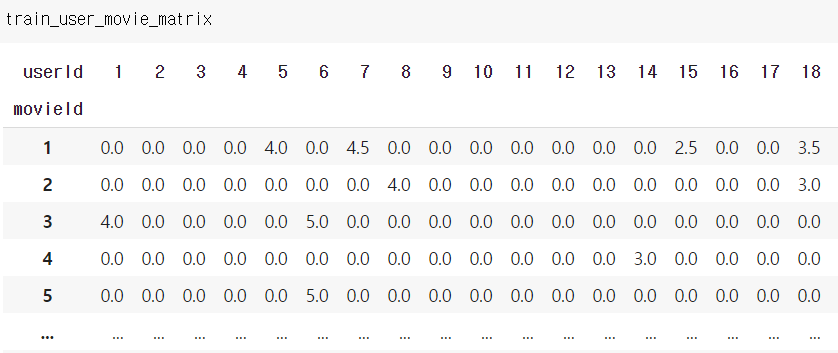
- User id 와 Movie id의 pivot table ( value = rating )
train_user_movie_matrix = train_df.pivot(
index='movieId',
columns='userId',
values='rating'
).fillna(0)
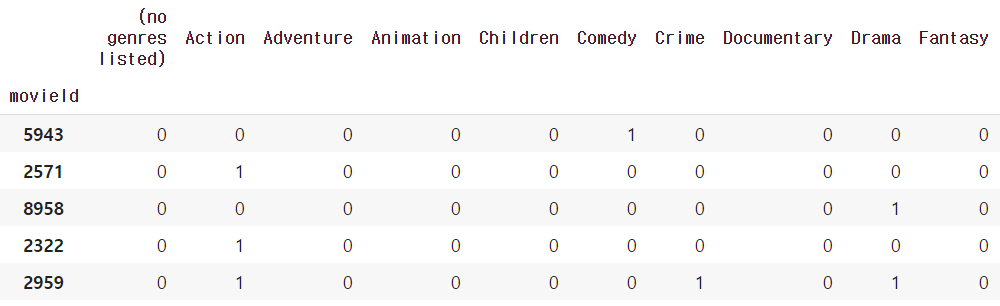
- 특정 영화가 속하는 장르를 dummy variable로 나타냄
genres_df = movies_df['genres'].str.get_dummies(sep='|')
genres_df = genres_df.loc[train_df.movieId.unique()]
- 영화 별 평점 평균
train_movie_avg_ratings_df = train_user_movie_matrix.copy()
train_movie_avg_ratings_df = train_movie_avg_ratings_df.replace(0, np.NaN)
train_movie_avg_ratings_df = train_movie_avg_ratings_df.mean(axis = 1)
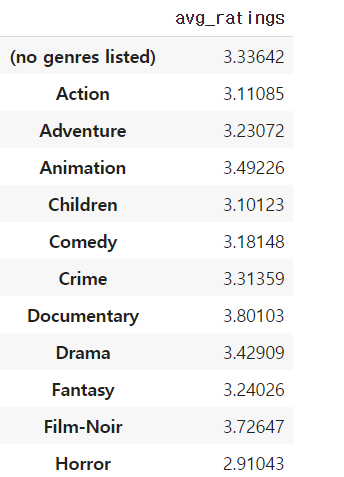
- 장르 별 평균
genres_avg_ratings_df = pd.DataFrame(index=genres_df.columns, columns=['avg_ratings'])
for genre in genres_avg_ratings_df.index:
genre_avg_rating = train_movie_avg_ratings_df.loc[genres_df[genres_df[genre].isin([1])].index].mean()
genres_avg_ratings_df.loc[genre]['avg_ratings'] = genre_avg_rating
genres_avg_ratings_df
- 장르 별 평균을 예측값으로 적용하기
def get_genre_avg_ratings(x):
genres_list = movies_df.loc[x]['genres'].split('|')
rating = 0
for genre in genres_list:
rating += genres_avg_ratings_df.loc[genre]['avg_ratings']
return rating / len(genres_list)
test_df['pred_rating_genre'] = test_df['movieId'].progress_apply(lambda x: get_genre_avg_ratings(x))
5. 최종 결과 및 성능 비교
RMSE로 위 4가지 방법들의 성능ㅊ 비교
for col in test_df.columns[test_df.columns.str.contains('pred')]:
print('MSE of {} : {}'.
format(col,np.sqrt(mean_squared_error(y_true=test_df['rating'].values, y_pred=test_df[col].values)).round(3)))
