
[ Recommender System ]
( 참고 : Fastcampus 추천시스템 강의 )
8. [code] Neighborhood-based CF
Neighborhood-based CF에는 아래와 같이 크게 2가지가 있다. 이 두 가지 알고리즘을 구현해볼 것이다.
- 1) Item-based CF
- 2) User-based CF
데이터 소개

1. Sparse Matrix 만들기
-
Movie ID x User ID의 sparse matrix를 만든다
( Movie ID: 8938개, User ID: 610개 )
-
pandas의
unstack사용하면 효율적으로 가능!
sparse_matrix = train_df.groupby('movieId').apply(lambda x: pd.Series(x['rating'].values, index=x['userId'])).unstack()
sparse_matrix.index.name = 'movieId'
sparse_matrix
2. Cosine Similarity
from sklearn.metrics.pairwise import cosine_similarity
def cossim_matrix(a, b):
cossim_values = cosine_similarity(a.values, b.values)
cossim_df = pd.DataFrame(data=cossim_values, columns = a.index.values, index=a.index)
return cossim_df
3. Item-based CF
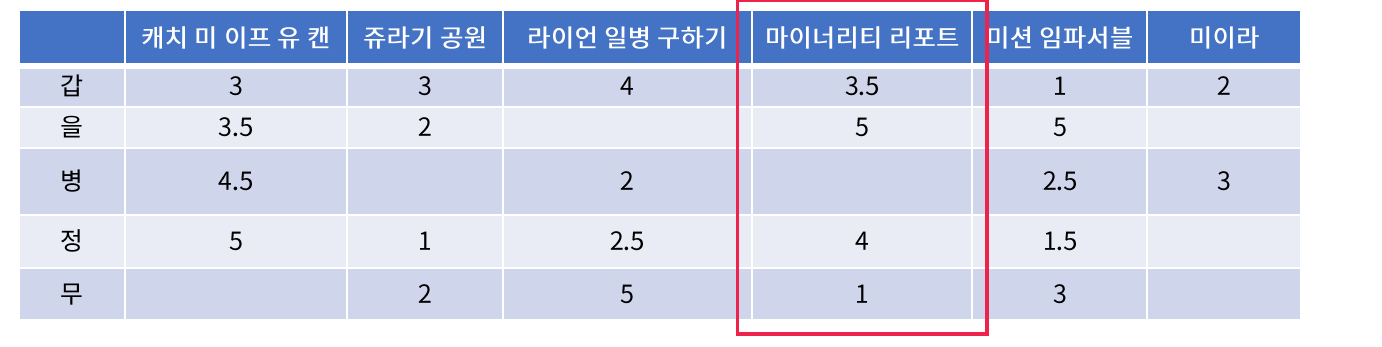
- 평가를 하지 않은 항목에 대해서는 0으로 채워넣는다
- 사람들의 평점 부여 정보를 바탕으로, item(영화)간의 코사인 유사도 행렬을 구한다.
item_sparse_matrix = sparse_matrix.fillna(0)
item_cossim_df = cossim_matrix(item_sparse_matrix, item_sparse_matrix)
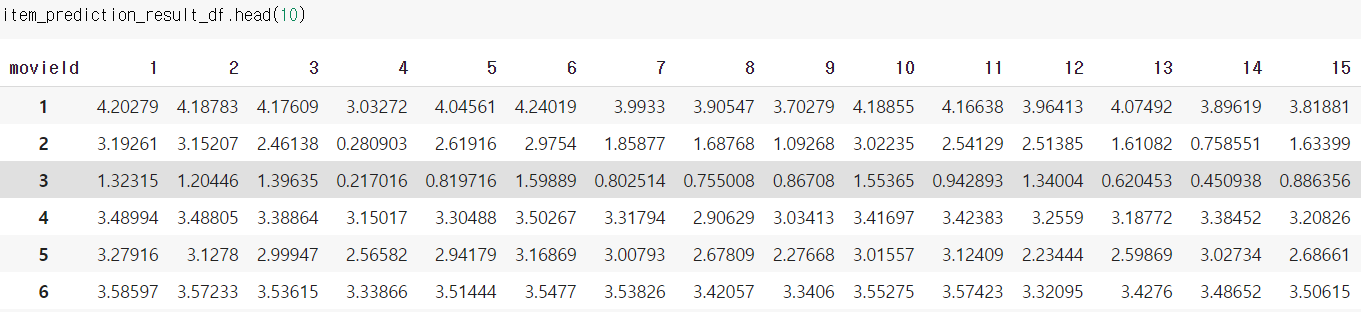
- Train 데이터의 유저 정보를 바탕으로, 예측을 한다
userId_grouped = train_df.groupby('userId')
item_prediction_result_df = pd.DataFrame(index=list(userId_grouped.indices.keys()), columns=item_sparse_matrix.index)
item_prediction_result_df
for userId, group in tqdm(userId_grouped):
user_sim = item_cossim_df.loc[group['movieId']]
user_rating = group['rating']
sim_sum = user_sim.sum(axis=0)
pred_ratings = np.matmul(user_sim.T.to_numpy(), user_rating) / (sim_sum+1)
item_prediction_result_df.loc[userId] = pred_ratings
4. User-based CF
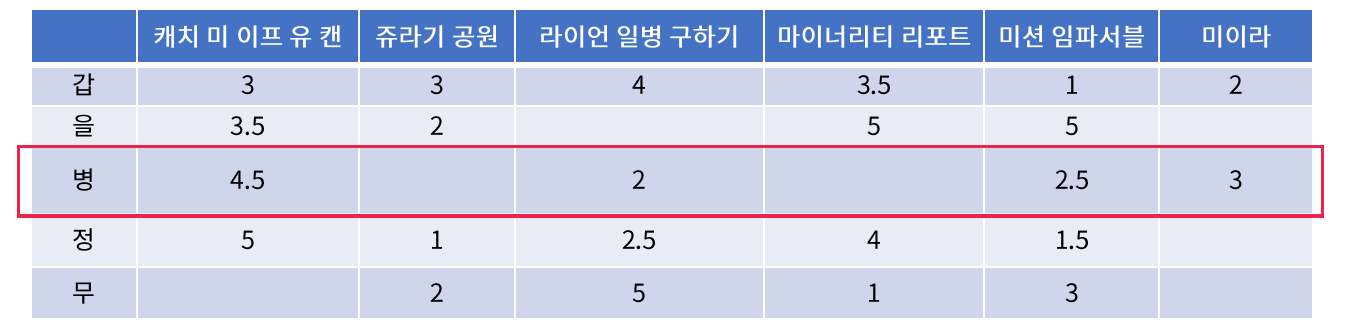
- 평가를 하지 않은 항목에 대해서는 0으로 채워넣는다
- 사람들의 평점 부여 정보를 바탕으로, user간의 코사인 유사도 행렬을 구한다.
user_sparse_matrix = sparse_matrix.fillna(0).transpose()
user_cossim_df = cossim_matrix(user_sparse_matrix, user_sparse_matrix)
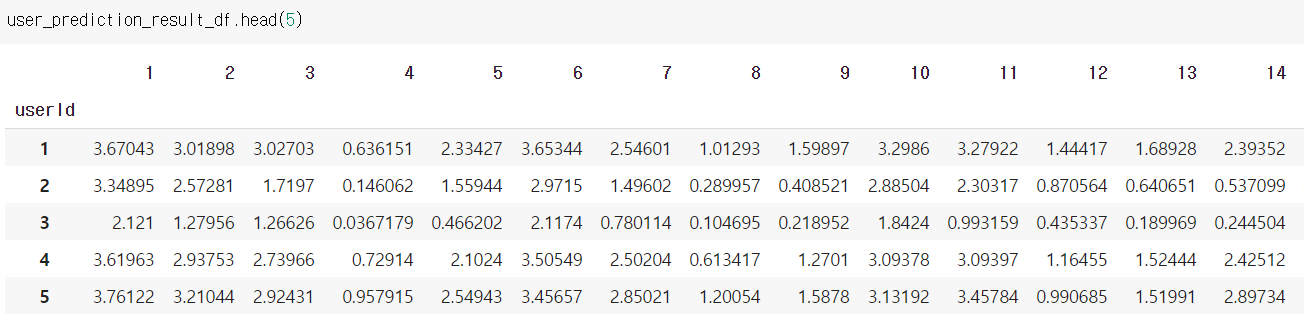
- Train 데이터의 유저 정보를 바탕으로, 예측을 한다
movieId_grouped = train_df.groupby('movieId')
user_prediction_result_df = pd.DataFrame(index=list(movieId_grouped.indices.keys()), columns=user_sparse_matrix.index)
for movieId, group in tqdm(movieId_grouped):
user_sim = user_cossim_df.loc[group['userId']]
user_rating = group['rating']
sim_sum = user_sim.sum(axis=0)
pred_ratings = np.matmul(user_sim.T.to_numpy(), user_rating) / (sim_sum+1)
user_prediction_result_df.loc[movieId] = pred_ratings
5. Evaluation
def evaluate(test_df, prediction_result_df):
groups_with_movie_ids = test_df.groupby(by='movieId')
groups_with_user_ids = test_df.groupby(by='userId')
intersection_movie_ids = sorted(list(set(list(prediction_result_df.columns)).intersection(set(list(groups_with_movie_ids.indices.keys())))))
intersection_user_ids = sorted(list(set(list(prediction_result_df.index)).intersection(set(groups_with_user_ids.indices.keys()))))
compressed_prediction_df = prediction_result_df.loc[intersection_user_ids][intersection_movie_ids]
grouped = test_df.groupby(by='userId')
result_df = pd.DataFrame(columns=['rmse'])
for userId, group in tqdm(grouped):
if userId in intersection_user_ids:
pred_ratings = compressed_prediction_df.loc[userId][compressed_prediction_df.loc[userId].index.intersection(list(group['movieId'].values))]
pred_ratings = pred_ratings.to_frame(name='rating').reset_index().rename(columns={'index':'movieId','rating':'pred_rating'})
actual_ratings = group[['rating', 'movieId']].rename(columns={'rating':'actual_rating'})
final_df = pd.merge(actual_ratings, pred_ratings, how='inner', on=['movieId'])
final_df = final_df.round(3)
return final_df
user_CF_result = evaluate(test_df, user_prediction_result_df)
item_CF_result = evaluate(test_df, item_prediction_result_df)
RMSE 비교
- user-based CF : 1.695
- item-based CF : 0.815
rmse_user_CF = np.sqrt(mean_squared_error(user_CF_result['actual_rating'].values,
user_CF_result['pred_rating'].values))
rmse_item_CF = np.sqrt(mean_squared_error(item_CF_result['actual_rating'].values,
item_CF_result['pred_rating'].values))