
( 출처 : 연세대학교 데이터베이스 시스템 수업 (CSI6541) 강의자료 )
Chapter 14. Recovery
Contents
- Failure Classification
- Recovery and Atomicity
- Log-Based Recovery
- Shadow Paging
- Recovery with Concurrent Transactions
- Buffer Management
(1) Failure Classification
a) Transaction failure
(1) Logical errors :
- transaction cannot complete, due to some logical error condition
(2) System errors:
- the DB system must terminate an active transaction due to an error condition (e.g., deadlock)
(3) System crash:
- a power failure or other hardware or software failure causes the system to crash
(4) Disk failure:
- a head crash or similar disk failure destroys all or part of disk storage
b) Recovery Algorithms
Definition )
- techniques to ensure (1) DB consistency, (2) transaction atomicity, and (3) durability despite failures
Consists of 2 parts :
- (1) Actions taken DURING normal transaction processing
- to ensure enough information exists to recover from failures
- (2) Actions taken AFTER a failure
- to recover the DB contents to a state that ensures atomicity, consistency, and durability
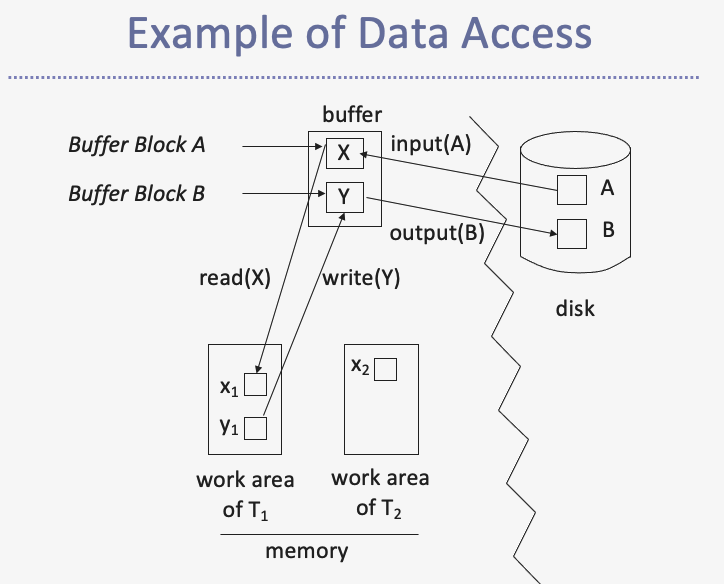
c) Data Access
Definitions )
-
Physical blocks : blocks residing on the disk
-
Buffer blocks : blocks residing temporarily in main memory
Block movements between disk & main memory :
- are initiated through input(B) and output(B) operations
Each transaction \(T_i\) has its “private work-area”,
where local copies of all data items accessed and updated by \(T_i\) are kept
( for simplicity, assume that each data item fits in a single block )
Transaction transfers data items between (1) buffer blocks & (2) its private work-area using read(X) and write(X) operations
Transactions
-
Perform read(X) when accessing X for the first time
-
All subsequent accesses are to the local copy
-
After last access, transaction executes write(X)
Output(BX) does not need to follow write(X) immediately
(2) Recovery and Atomicity
Inconsistent state
- Modifying the DB, without ensuring that the transaction will commit may leave the database in an inconsistent state
Example )
- Transaction \(T_i\) : transfers $$50 from account A to account B
- Goal : either to perform “all” DB modifications made by \(T_i\) or “none at all”
- Several output operations may be required for \(T_i\)
\(\rightarrow\) A failure may occur after one of these modifications have been made but before all of them are made
To ensure atomicity despite failures …
\(\rightarrow\) we first output information describing the modifications to **stable storage ** without modifying the DB itself
2 approaches
- (1) Log-based recovery
- (2) Shadow-paging
We assume (initially) that transactions run serially
(3) Log-Based Recovery
Log = sequence of log records
- records all the update activities in the DB
When transaction \(T_i\) starts….
- (1) Registers itself by writing a <\(T_i\) start> log record
- (2) Before \(T_i\) executes write(X), a log record <\(T_i\), X, V1, V2> is written
- where V1 is an old value and V2 is a new value
- (3) When \(T_i\) finishes its last statement, the log record <\(T_i\) commit> is written
Assumption
-
log records are written directly to stable storage
( = they are not buffered )
2 approaches using logs:
- (1) Deferred DB modification
- (2) Immediate DB modification
a) Defered DB modification
records all DB modifications in the log,
but defers all the writes until the transaction partially commits
-
Transaction starts by writing <\(T_i\) start> record to log
-
A write(X) operation by \(T_i\) results in the writing of a new record to the log
-
The write is not performed on \(X\) at this time, but deferred!!

b) Immediate DB modification
allows DB modifications to be output to the DB, while the transaction is still in the active stage
-
Update log record must be written before DB item is written
-
Output of updated buffer blocks can take place at any time before or after transaction commit
-
Order in which blocks are output can be different from the order in which they are written
When recovering after failure:
-
(1) Transaction \(T_i\) needs to be UNDONE…
if the log contains the record <\(T_i\) start>, but does not contain the record <\(T_i\) commit>
-
(2) Transaction \(T_i\) needs to be REDONE …
if the log contains both the record <\(T_i\) start> and the record <\(T_i\) commit>

c) Checkpoints
Problems in recovery procedure
-
Searching the entire log is time-consuming
-
Most of the transactions that need to be redone have already written their updates into the DB
To reduce these types of overhead ….
\(\rightarrow\) the system periodically performs “checkpoints”, which require the following sequence of actions :
-
(1) Output onto stable storage “all log records currently residing in main memory“
-
(2) Output to the disk “all modified buffer blocks“
-
(3) Output onto stable storage “a log record <checkpoint>“
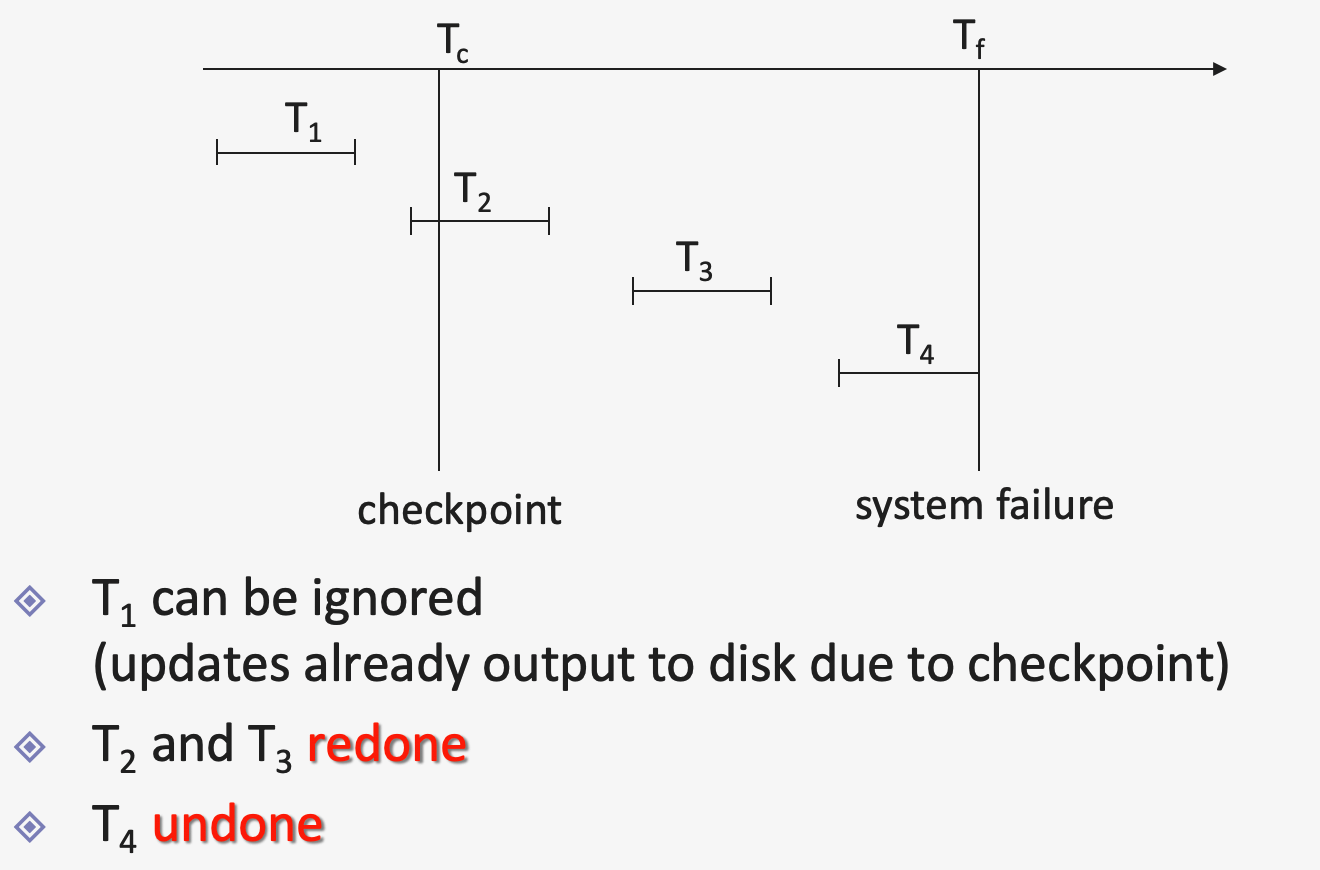
During recovery, we need to consider
- (1) only the MOST RECENT transaction \(T_i\) that started before the checkpoint, and
- (2) transactions that started after \(T_i\)
Procedure
-
step 1) Scan backward from end of log to find the most recent <checkpoint> record
-
step 2) Continue scanning backwards till a record <\(T_i\) start> is found
-
step 3) Need only consider the part of log “following above start record”
-
step 4)
- 4-1) For all transactions starting from \(T_i\) or later with no <\(T_i\) commit>, execute undo(\(T_i\))
- 4-2) Scanning forward in the log, for all transactions starting from \(T_i\) or later with <\(T_i\) commit>, execute redo(\(T_i\))
(4) Shadow Paging
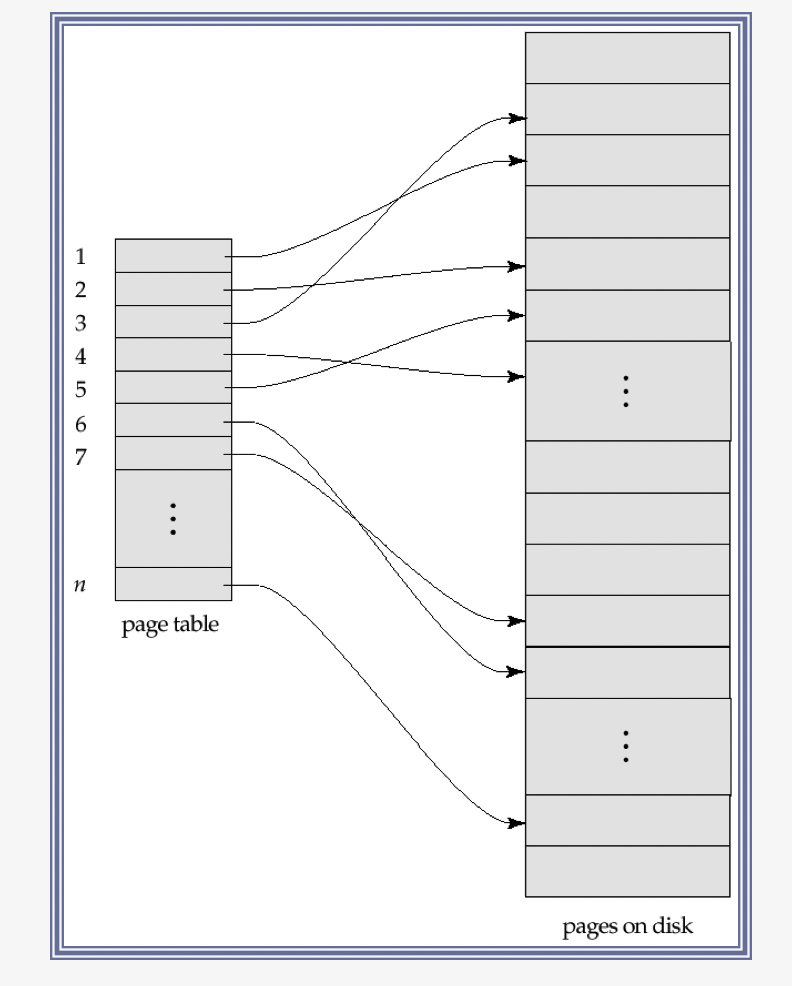
a) Page & Page Table
DB is partitioned into some number of fixed-length blocks ( = pages )
The pages do not need to be stored in any particular order on disk
We use a “page table” to find the \(i\)th “page” of the DB for a given \(i\)
b) Shadow Paging
Shadow Paging
- alternative to log-based recovery
- useful if transactions execute serially
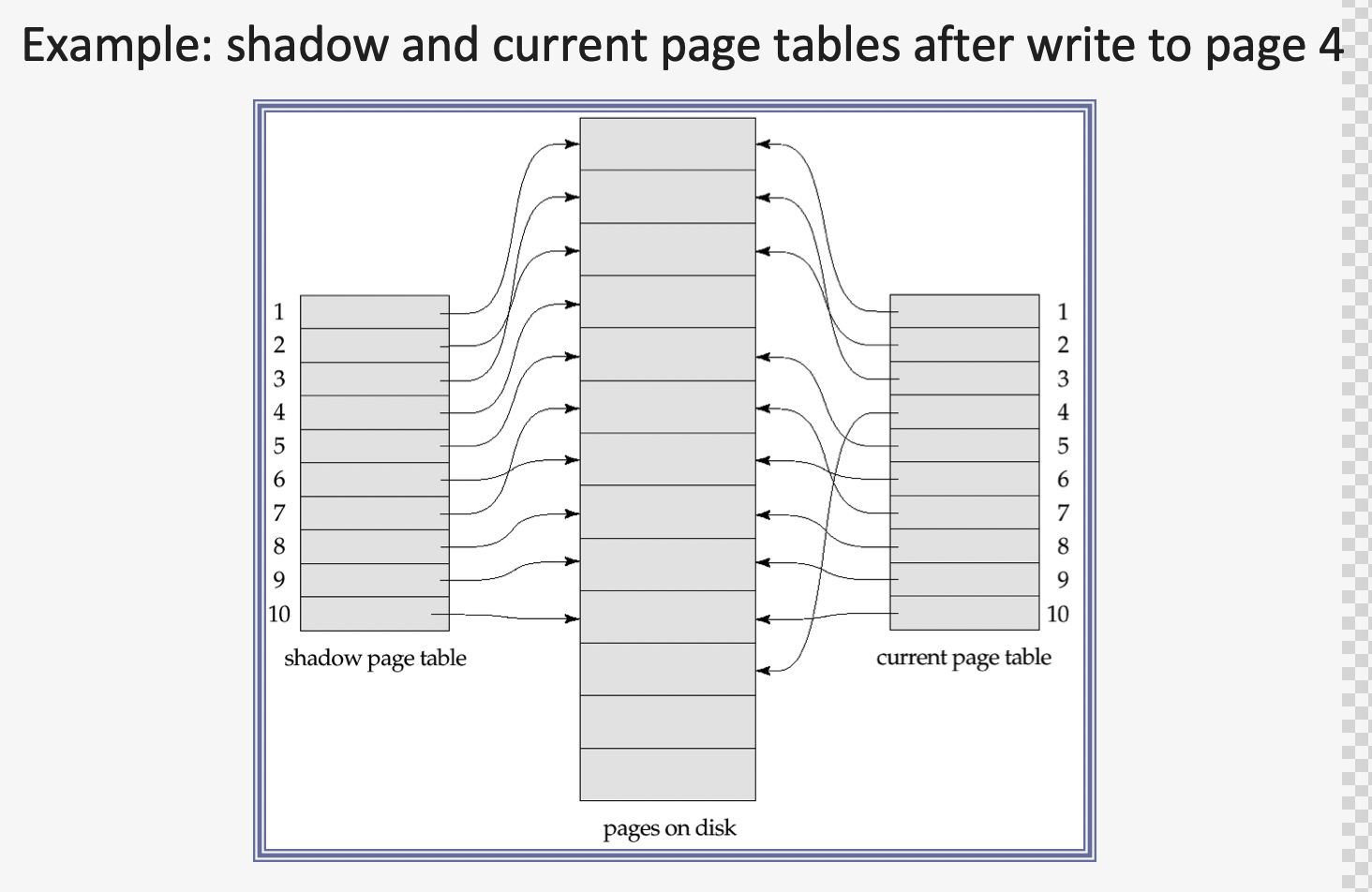
Key Idea : maintain 2 page tables during the lifetime of a transaction
-
page 1) ”current” page table
-
page 2) ”shadow” page table
\(\rightarrow\) Both page tables are identical when the transaction starts
Shadow Table
- never changed over the duration of the transaction
Current Page Table
-
may be changed when a transaction performs a write operation
-
All input and output operations use the current page table to locate database pages on disk
Suppose that \(T_j\) performs a write(\(X\)), and that \(X\) resides on the \(i\)th page
The system executes the write operation as follows:
-
If the \(i\)th page is not already in main memory
\(\rightarrow\) then the system issues input(X)
-
If this is the write first performed on the \(i\)th page by this transaction,
\(\rightarrow\) then the system modifies the current page table as follows:
- (1) It finds an unused page on disk
- (2) It copies the contents of the \(i\)th page to the page found in above step
- (3) It modifies the current page table so that the \(i\)th entry points to the page found in above step
-
It assigns the value of \(x_j\) to \(X\) in the buffer page
Summary
https://itwiki.kr/w/%EA%B7%B8%EB%A6%BC%EC%9E%90%ED%8E%98%EC%9D%B4%EC%A7%95%ED%9A%8C%EB%B3%B5_%EA%B8%B0%EB%B2%95
- 트랜잭션이 실행되는 메모리상의 Current Page Table과 하드디스크의 Shadow Page Table 이용
- 트랜잭션 시작시점에 Current Page Table과 동일한 Shadow Page Table 생성
- 트랜잭션 성공 시 : Shadow Page Table 삭제
- 트랜잭션 실패 시 : Shadow Page Table을 Current Page Table로 함
(5) Recovery with Concurrent Transactions
modify the log-based recovery schemes,
to allow MULTIPLE transactions to execute CONCURRENTLY
( = share a “single buffer” and a “single log” )
Checkpoint technique & actions taken on recovery have to be changed
Review
-
UNDO-list = consists of incomplete transactions that must be undone
-
REDO-list = consists of finished transactions that must be redone
Checkpoint
checkpoint log record : <checkpoint L>
- L : list of transactions active at the time of checkpoint
Procedures
-
step 1) Initialize undo-list and redo-list to empty
-
step 2) Scan the log backward from the end
& stop when the first <checkpoint L> record is found
- step 3) For each record found during the backward scan:
- if the record is <Ti commit> \(\rightarrow\) add Ti to REDO-list;
- If the record is <Ti start> & not in redo-list \(\rightarrow\) add Ti to undo-list
- step 4) For every Ti in L …
- if Ti is not in redo-list \(\rightarrow\) add Ti to UNDO-list
Recovery
Procedures
-
step 1) Scan log backward from the end
& perform UNDO for each log record in Ti on UNDO-list
& stop when <Ti start> records have been found for every Ti in undo-list
-
step 2) Locate the most recent <checkpoint L> record
-
step 3) Scan log forward from the <checkpoint L> record
& perform REDO for each log record in Ti on REDO-list
[ Caution ] first UNDO, then REDO!
(6) Buffer Management
Log Record Buffering
Log records
-
buffered in “main memory ( not directly to stable storage )
-
output to stable storage, when …
-
(1) block of log records in the buffer is full,
-
(2) log force operation is executed
-
log force : performed to commit a transaction by forcing all its log records to stable storage
( Several log records can be output using a single output operation, reducing the I/O cost )
-
-
Rules ( if log records are buffered )
-
Log records are output to stable storage in the order in which they are CREATED
-
Ti enters the commit state,
only when the log record <Ti commit> has been output to stable storage
-
[ write-ahead logging or WAL rule ] :
-
Before a block of data in main memory is output to the DB,
all log records pertaining to data IN THAT BLOCK must have been output to stable storage
-