
( 출처 : 연세대학교 데이터베이스 시스템 수업 (CSI6541) 강의자료 )
Chapter 8. Storage and File Structure
Contents
- Classification of Physical Storage Media
- Flash Storage
- File Organization
- Organization of Records in Files
- Data Dictionary Storage
(0) 개념 정리
- 참고 : https://chartworld.tistory.com/17
-
Field : 고정/가변 길이의 순차적 바이트 ( = column을 표현하는데에 사용 )
-
Record : Field들의 모음 ( = Tuple, Object 등 )
-
record는 “물리적 block”에 저장되어야
-
record가 변경되는 경우라면, “가변 데이터 구조”가 유용
-
-
Block : Record들의 모음
-
File : Block들의 모음
- 효율적인 querying / modifcation을 위해, File에 인덱스 (index) 부여
(1) Classification of Physical Storage Media
Criteria
- (1) speed
- speed with which data can be accessed
- (2) cost
- cost per unit of data
- (3) reliability
- data loss on power failure / system crash
- physical failure of storage device
- (4) volatility
- (4-1) volatile storage
- switch off \(\rightarrow\) lose contents
- (4-2) non-volatie storage
- switch off \(\rightarrow\) contents persists
- Ex) secondary and tertiary storage, battery backed-up main memory
- (4-1) volatile storage
a) Storage Hierarchcy
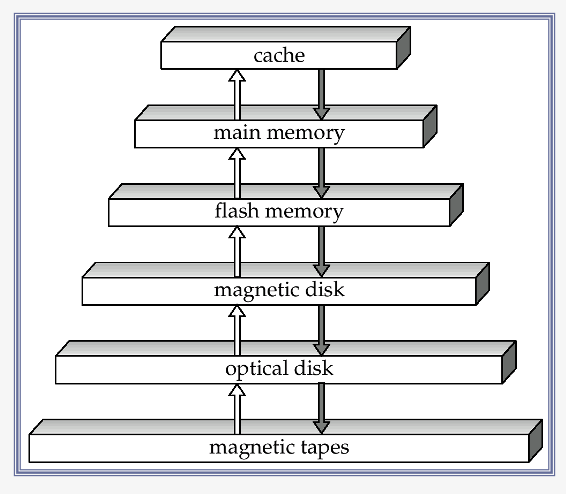
- Primary Storage
- Fastest / Volatile
- ex) cache, main memory
- Secondary Storage
- Non-volatile / Moderately fast
- called on-line storage
- ex) flash memory, magnetic disks
- Tertiary Storage
- Non-volatile / Slow
- called off-line storage
- ex) optical disk, magnetic tape
Magnetic Hard Disk Mechanism
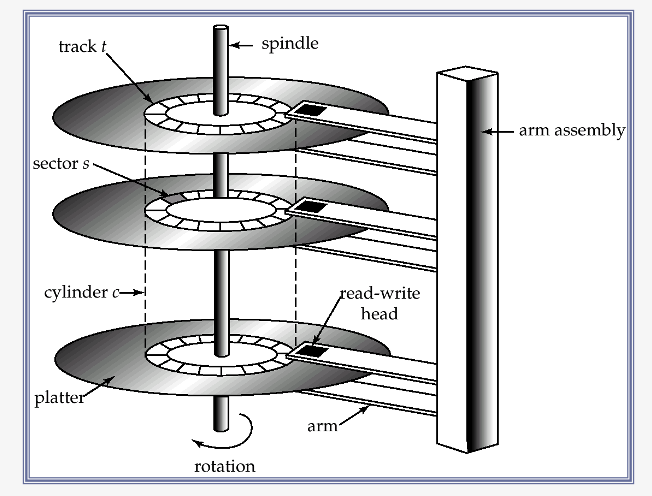
b) Optimization of Disk-Block Access
Block
- a contiguous sequence of sectors from a single track
- data is transferred between “disk” & “main memory” in blocks
- size : 512 bytes ~ XXX kilobytes
Disk-arm scheduling algorithms
- order pending access to tracks, so that disk arm movement is minimized
Details
-
to reduce block-access time,
we can organize blocks on disks in a way that corresponds to how data will be accessed
-
ex) store related info in same / nearby cylinders
-
however…
- FRAGMENTATION : blocks may be get scattered all over the disk, by insertion/deletion
- DE-FRAGMENTATION : some systems have utilities for de-fragmentation
(2) Flash Storage
2 types of flash memory
- (1) NAND
- (2) NOR
Details :
-
NAND : much higher storage capacity ( for a given cost )
-
widely used for data storage, in camera, music players, cell phones…
-
lower cost per byte ( than main memory )
-
non-volatile
-
requires page-at-a-time read
- page : 512 bytes ~ 4kB
-
transfer rate : 20 mb/ sec
-
solid state disks : use multiple flash storage devices, to provide higher transfer rate
( 100 ~ 200 mb / sec)
-
once written, flash page cannot be directly overwritten
( has been erased & rewritten subsequently )
-
Erase opration :
- performed on number of pages, called erase blocks
-
there is a limit to how many times a flash page can be erased
( 100,000 ~ 1,000,000 times … wear leveling )
-
flash memory system :
- reduces the impact of these problems, using a software layer called FTL (Flash Translation Layer)
(3) File Organization
DB : stored as a collection of files
- File : organized logically as a sequence of records
Each file : logically partitioned into fixed-length storage units ( = blocks )
- blocks = units of both storage allocation & data transfer
One approach :
- assume record size is fixed
- each file has records of one particular type only
- different files for different relations
\(\rightarrow\) easiest to implement!
( later….will deal with variable length records )
a) Fixed-Length records
Simple approach
- store record \(i\), starting from byte \(n*i\)
- \(n\) = size of each record
- record access is simple ….. but records may cross blocks
example)
CREATE TABLE MovieStar (
name CHAR(30) PRIMARY KEY,
address VARCHAR(255),
gender CHAR(1),
birthdate DATE );
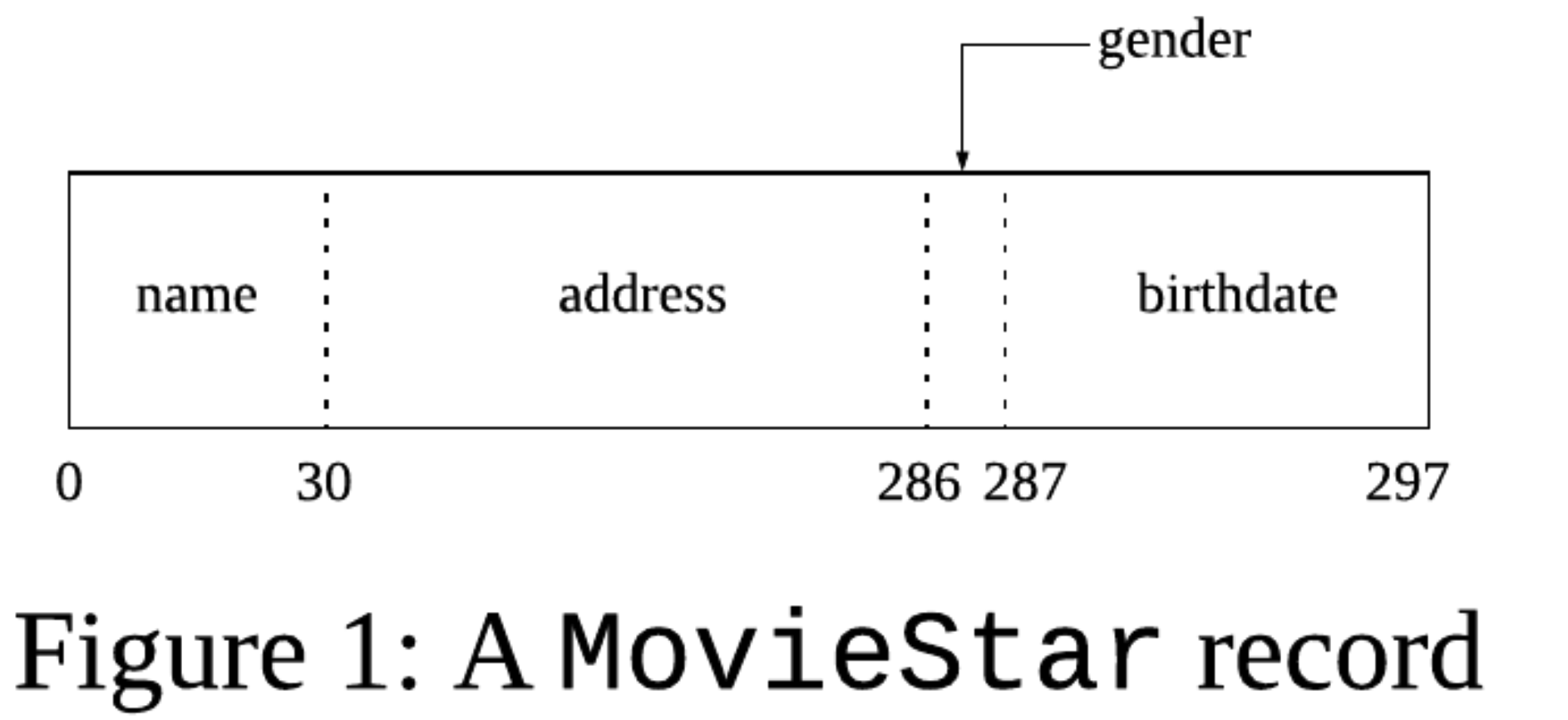
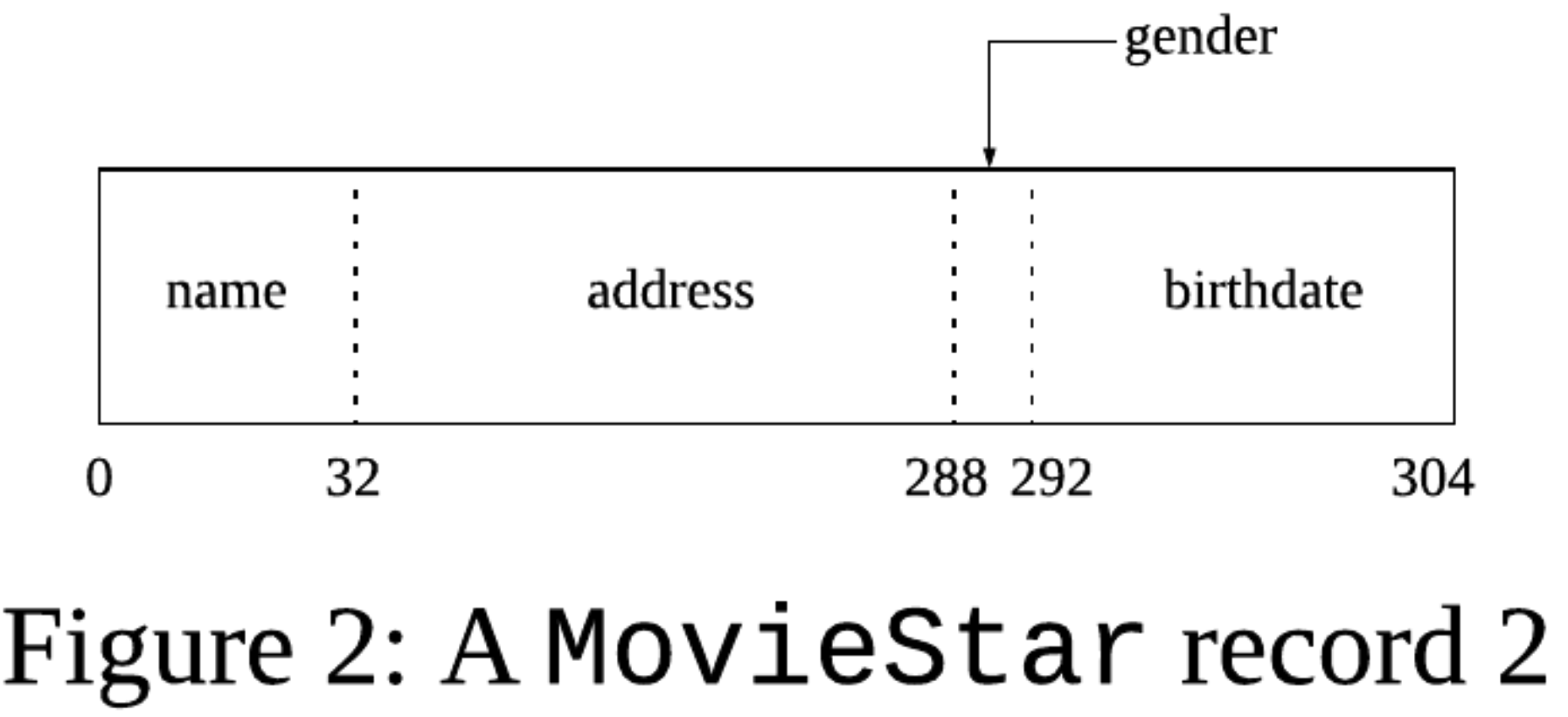
- 32-bit porcessor ( 4의 배수 )
- 64-bit porcessor ( 8의 배수 )
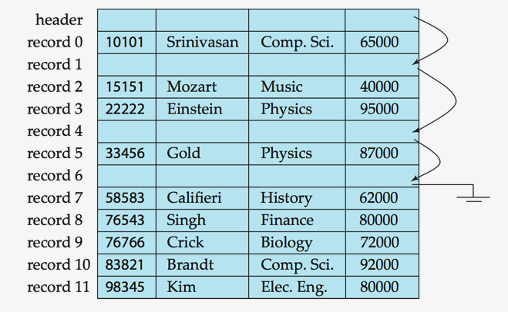
Deletion of record \(i\) : alternatives
- (1) move records
- (from) \(i+1, \cdots m\)
- (to) \(i, \cdots m-1\)
- (2) do not move records, but link all free records on a free list
Free List :
-
store the address of the first deleted record in the file header
- use this first record to store the address of the second deleted record
- can think of these stored addresses as pointers
- More space efficient representation:
- reuse space for normal attributes of free records to store pointers
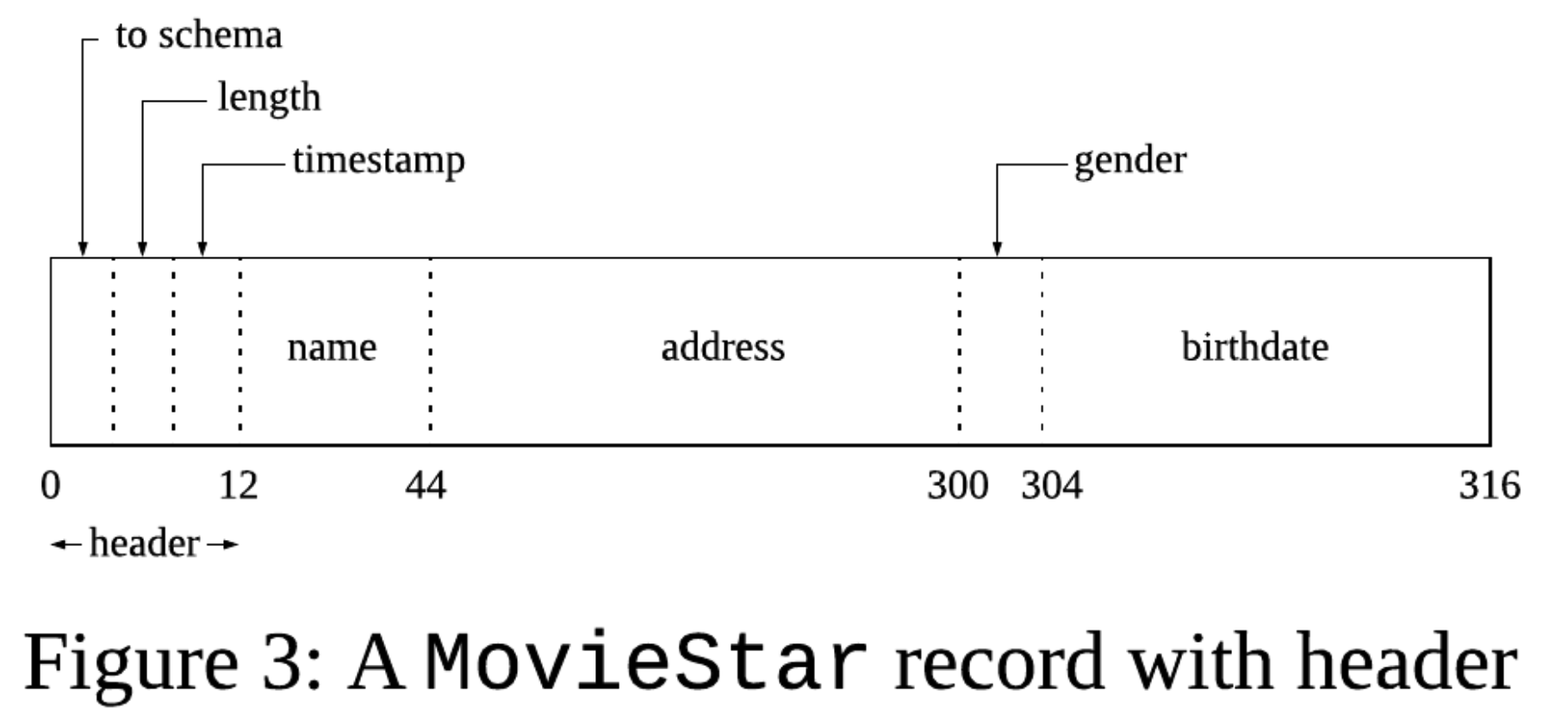
Record Headers : record가 가지고 있어야하는 (필드의 값이 아닌) 정보
- (1) record의 스키마 ( or, 스키마를 저장하는 장소에 대한 포인터 )
- (2) record의 길이
- (3) 가장 최근 수정/읽은 시간 (timestamps)
DB system은, CREATE TABLE 시 “schema information”를 header에 유지함
-
Schema Information
- columns
- types
- tuple에 등장하는 col 순서
- Constraints 등…
-
이 모든 정보를 header에 담기에는… ㅠㅠ
\(\rightarrow\) “해당 정보들이 저장되어 있는 곳을 가리키는 pointer“만 있으면 됨!
b) Variable-Length Records
Variable-Length Records arise in DB in several ways :
- storage of multiple record types in a file
- record types, that allow…
- variable lengths for one or more fields
- repeating fields
Byte-string representation
-
store each record as a string of consecutive bytes
-
attach. an end-of-record (ㅗ) control character, to the end of each record
-
Not easy to reuse space occupied formerly by a deleted record
-
no space, in general, for records to grow longer
\(\rightarrow\) not usually used for implementing variable-length records
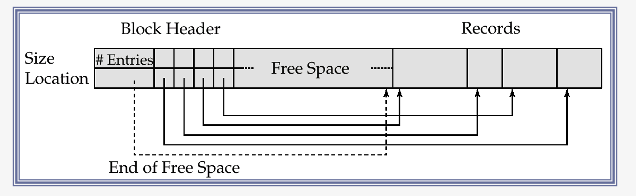
c) Slotted Page Structure
structure for “variable-length records”
Slotted page header contains…
- (1) # of record entries
- (2) end of free space in the block
- (3) location & size of each record
Records can be moved around within a page to keep them contiguous with no empty space between them
\(\rightarrow\) entry in the header must be updated
Pointers should not point directly to record
\(\rightarrow\) instead, point to the “entry” for the record in header
(4) Organization of Records in FIles
have studied how records are represented in a file structure
next question : how to organize them in a file?
-
(1) Heap
-
record can be placed anywhere in the file,
where there is a space
-
-
(2) Sequential
-
store records in a sequential order,
based on the value of the search key of each record
-
-
(3) Hashing
- computed on some attribute of each record
- result. specifies in which block of the file the record should be placed
Records of each relation may be stored in a separate file
- “multitable clustering file organization” records of several different relations can be stored in the same file
a) Sequential File Organization
-
Suitable for applications that require sequential processing of the ENTIRE file
-
records in the file are ordered by a search-key
- search key : any attribute ( not need to be primary/super key )
-
to permit fast retrieval of records in search-key order…
\(\rightarrow\) we chain together records by pointers
-
Deletion & Insertion
-
Deletion : use pointer chains
-
Insertion : locate the position, where the record is to be inserted
- if free space O : insert there
- if free space X : record in an overflow block
( in either case, pointer chain must be updated )
-
need to reorganize the file from time to time, to restore sequential order
-
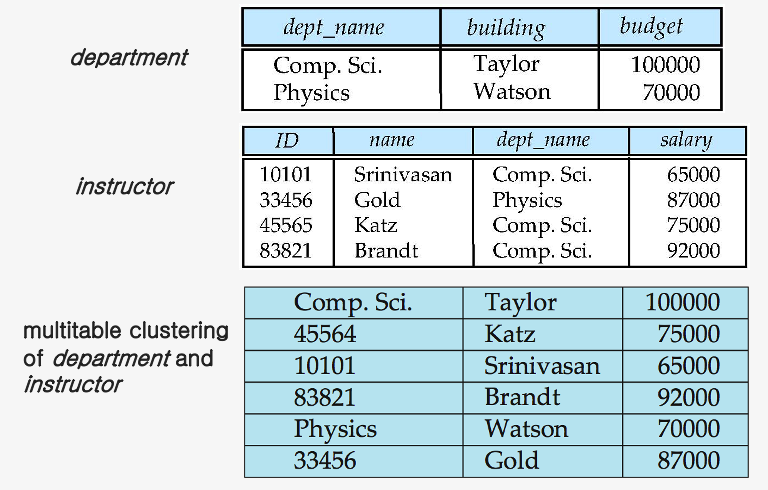
b) Multitable Clustering File Organization
simple file structure : stores each relation in a separate file
\(\leftrightarrow\) store several relations in one file, using “MULTITABLE clustering” file organization
Example) Multitable clustering organization of department and instructor:
- GOOD for queries joining department and instructor relations
- BAD for queries involving only department
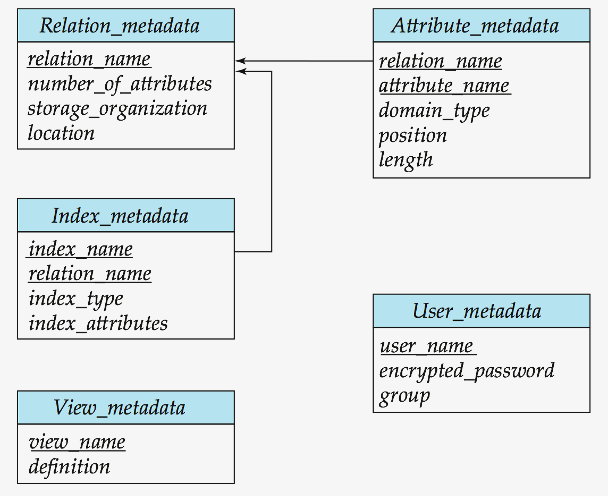
(5) Data Dictionary Storage
Data dictionary ( = system catalog ) : stores metadata
Meta data ( = data about data )
examples :
- Information about relations
- Names of relations
- Names and types of attributes of each relation
- Names and definitions of views
- Integrity constraints
- User and accounting information,
- ex) passwords
- Statistical and descriptive data
- ex) Number of tuples in each relation
- Physical file organization information
- How relation is stored (sequential/hash/…)
- Physical location of relation
- Information about indices
(6) Summary
참고 자료 : https://velog.io/@gwak2837/%EB%8D%B0%EC%9D%B4%ED%84%B0%EB%B2%A0%EC%9D%B4%EC%8A%A4-%ED%8C%8C%EC%9D%BC-%EA%B5%AC%EC%A1%B0
a) 힙 (Heap)
- 의미 = 더미
- 레코드가 파일의 빈 공간에 아무런 순서 없이 저장된 구조
-
보통 레코드가 한번 저장되면 위치가 변하지 않기 때문에, 어느 파일에 어느 정도의 빈 공간이 있는지 확인할 수 있도록 빈 공간에 대한 정보를 따로 관리하기도 함
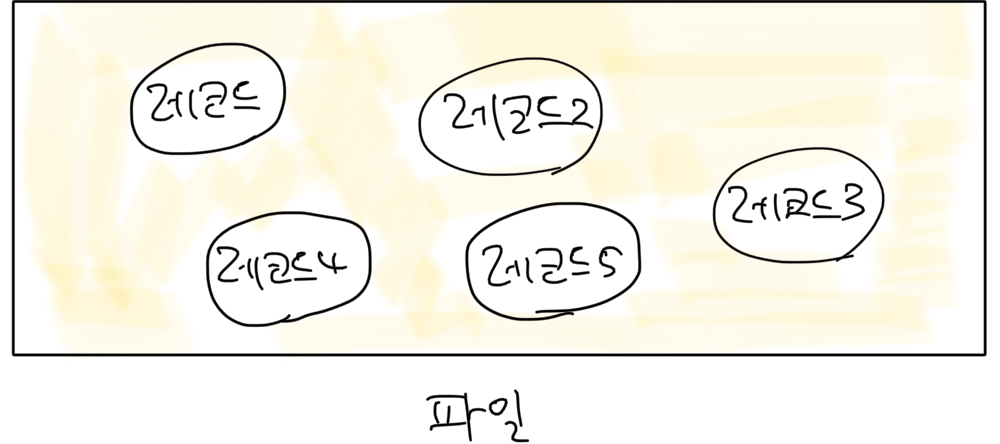
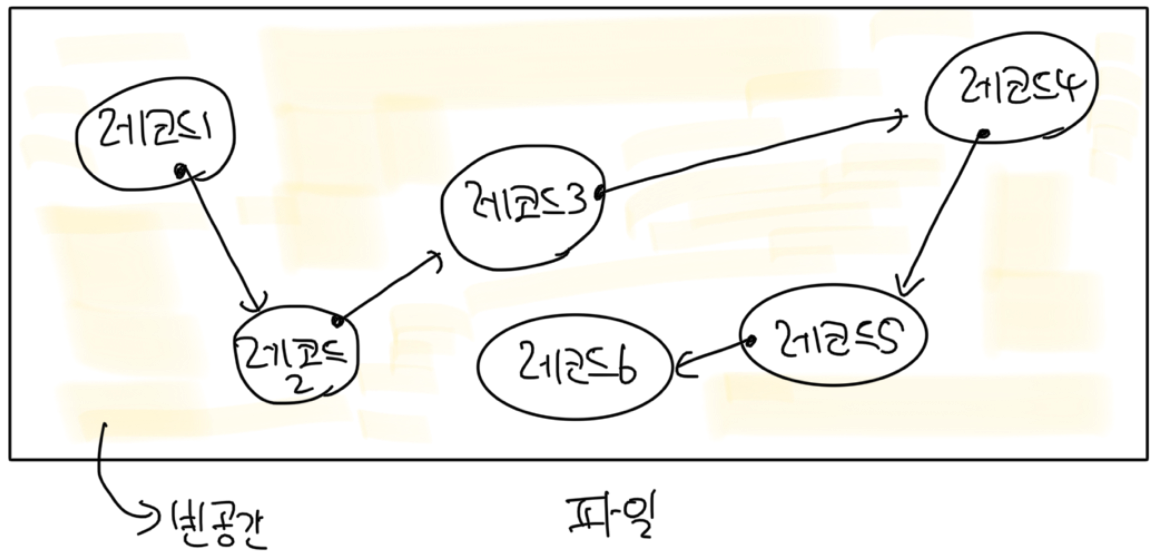
b) 순차 접근 (Sequential)
-
특정 컬럼을 기준으로 레코드가 정렬되어 저장된 구조
-
각 레코드는 포인터로 연결돼서 연결 리스트처럼 관리
( 장단점은 연결 리스트의 장단점이랑 비슷 )
- 장점 : 항상 레코드에 순차적으로 접근해야 하기 때문에 모든 레코드에 접근할 땐 유리
- 단점 : 특정 레코드만 검색하고 싶을 땐 불리
-
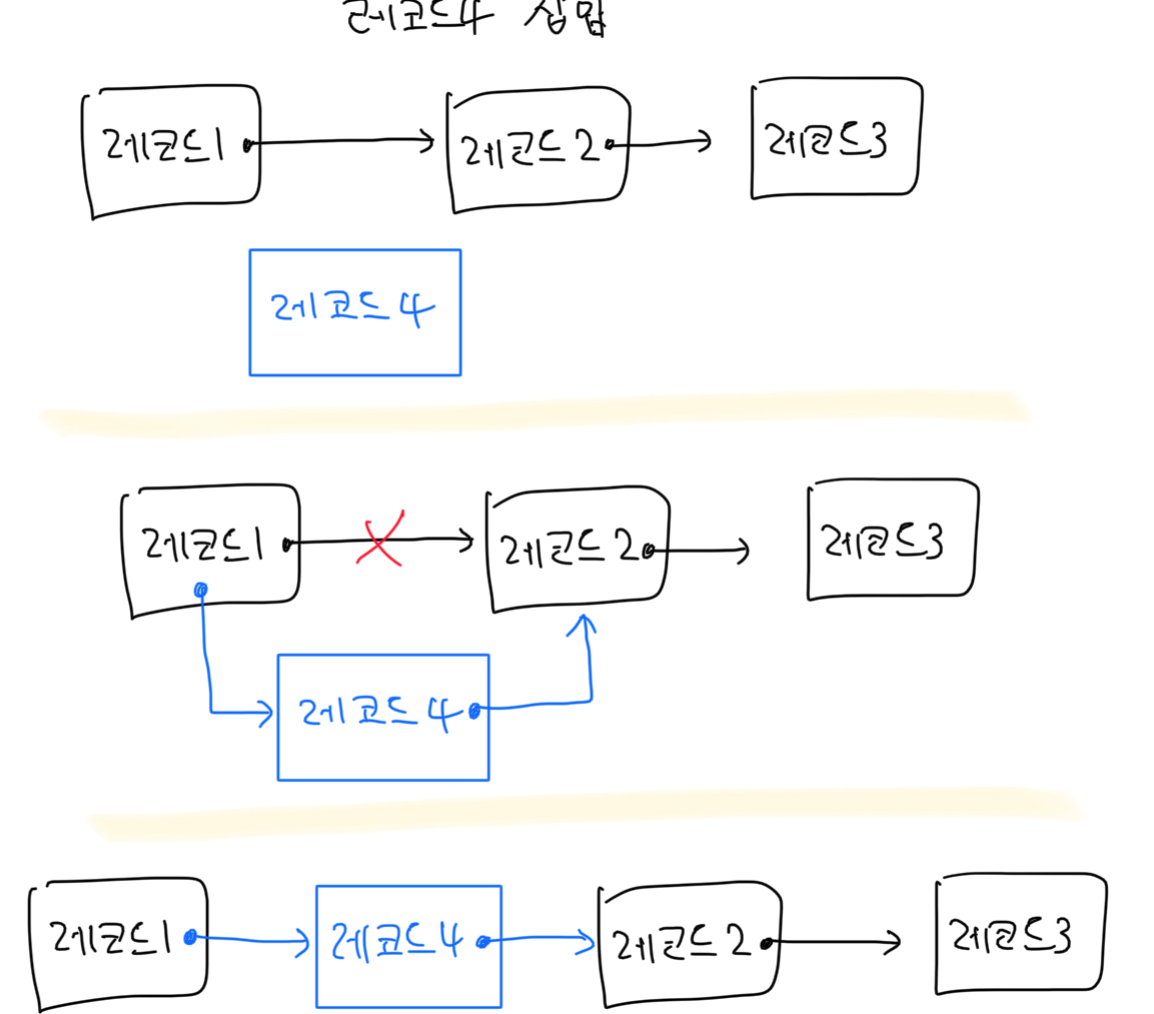
-
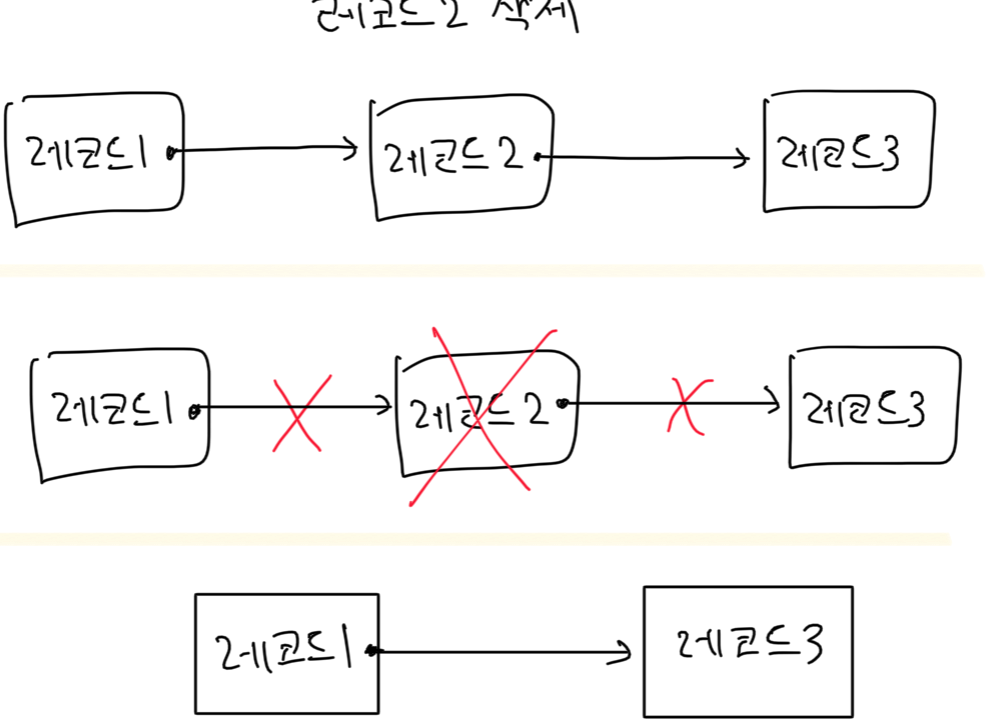
레코드 삽입·삭제 : ( 기존 단방향 연결 리스트와 동일 )
-
삽입 : 만약 파일이 저장된 블록에 자리가 없다면 다른 블록(overflow block)에 저장하고 레코드끼리 포인터로 연결합니다
-
여러 번의 삽입·삭제가 이뤄지면서 다른 블록(overflow block)에도 레코드가 저장되면 나면 블록 빈 공간 사용 효율이 떨어짐
\(\rightarrow\) 주기적으로 파일 구조를 재구성해줘야 하는 단점
-
c) 다중 테이블 클러스터링 ( Multitable Clustering )
-
여러 테이블의 레코드를 한 파일에 저장하는 구조
-
논리적으로 밀접한 테이블들을 하나의 테이블에 저장하면,
각 테이블에 접근할 때마다 발생하던 디스크 I/O 횟수를 줄일 수 있음
-
example ) join 연산
- 대상 테이블의 모든 레코드가 동일한 블록 내에 있으면 1번의 블록 I/O를 통해 결과를 얻을 수 O
-
example) 외래키 필드와 해당 필드가 가리키는 레코드
- 두 개를 한 파일에 모아두면, 레코드가 한 파일에 모여있기 때문에 외래키 join 검색에 유리