Unsupervised Data Augmentation for Consistency Training (2020)
Contents
- Abstract
- Unsupervised Data Augmentation (UDA)
- UDA
- Augmentation Strategies for Different Tasks
0. Abstract
Semi-supervised learning
-
Common among recent approaches : consistency training on a large amount of unlabeled data
\(\rightarrow\) to constrain model predictions to be invariant to input noise
This paper :
-
proposes how to effectively noise unlabeled examples
-
argue that the quality of noising is important
1. Unsupervised Data Augmentation (UDA)
(1) UDA
Final Loss : (1) + (2)
- (1) ( with labeled data ) supervised CE loss
- (2) ( with unlabeled data ) unsupervised Consistency loss
\(\min _\theta \mathcal{J}(\theta)=\mathbb{E}_{x_1 \sim p_L(x)}\left[-\log p_\theta\left(f^*\left(x_1\right) \mid x_1\right)\right]+\lambda \mathbb{E}_{x_2 \sim p_U(x)} \mathbb{E}_{\hat{x} \sim q\left(\hat{x} \mid x_2\right)}\left[\operatorname{CE}\left(p_{\tilde{\theta}}\left(y \mid x_2\right) \mid \mid p_\theta(y \mid \hat{x})\right)\right]\).
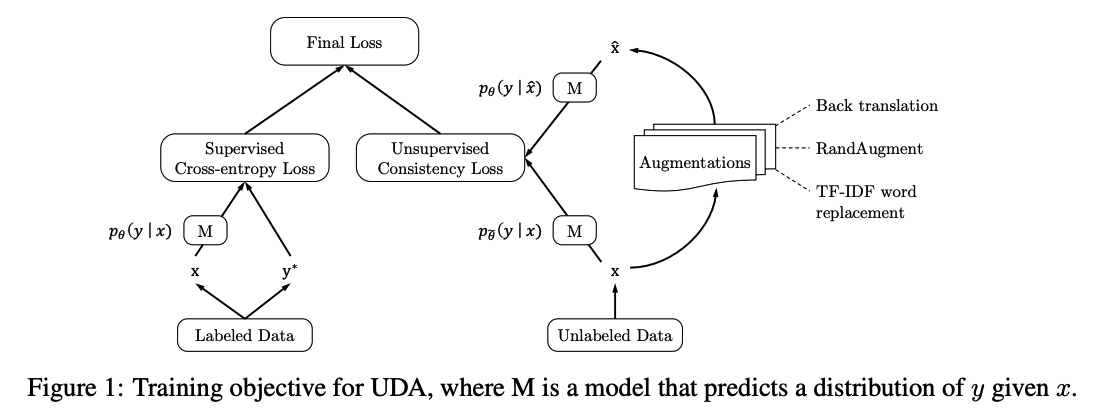
provide intuitions on how more advanced data augmentations can provide extra advantages over simple ones
(2) Augmentation Strategies for Different Tasks
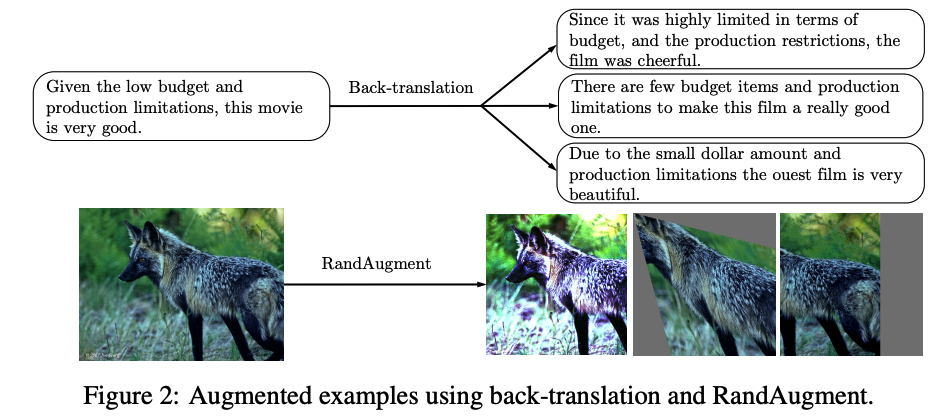
Image Classification : RandAugment
-
inspired by AutoAugment
- search method to combine all image processing transformations in the Python Image Library (PIL) to find a good augmentation
-
RandAugment
- do not use search
- but instead uniformly sample from the same set of augmentation transformations in PIL
\(\rightarrow\) simpler & requires no labeled data
Text-Classification : Back-translation
-
Translating an existing example \(x\) in language \(A\) into another language \(B\)
& translate back to \(A\) to obtain an augmented example \(\hat{x}\)