CMKD: CNN/Transformer-Based Cross-Model Knowledge Distillation for Audio Classification (arxiv 2022)
https://arxiv.org/pdf/2203.06760.pdf
Contents
- Abstract
- Introduction
- Cross-Model Knowledge Distillation (CMKD)
- CNNs
- ASTs
- Difference btw CNN and AST
- Knowledge Distillation
- Experiment Settings
- Datasets
- Training Settings
- FSD50K experiments
- Audioset and ESC-50 experiments
Abstract
Audio classification
- CNNs : have been the de-facto standard building block for end-to-end audio classification models
- Self-attention mechanisms : have been shown to outperform CNNs
- ex) Audio Spectrogram Transformer (AST)
Cross-Model Knowledge Distillation (CMKD)
This paper, we find an intriguing interaction between the two very different models
\(\rightarrow\) CNN and AST models are good teachers for each other … via knowledge distillation (KD)
Experiments with this CNN/Transformer Cross-Model Knowledge Distillation (CMKD)
- achieve new SOTA performance on FSD50K, AudioSet, and ESC-50.
1. Introduction
(1) Audio classification
History
- (1) hand-crafted features & hidden Markov models (HMMs)
-
(2) CNNs : aim to learn a direct mapping from audio waveforms or spectrograms to corresponding labels
- (3) Self-attention : outperform CNN
CNN vs. Transformer
- CNN :
- built-in inductive biases
- ex) spatial locality and translation equivariance
- well suited to spectrogram based end-to-end audio classification.
- built-in inductive biases
- Transformer :
- do not have such built-in inductive biases
- learn in a more data-driven manner, making them more flexible.
- perform better but less computationally efficient than CNN models on long audio input due to their \(O(n^2)\) complexity.
Intriguing interaction between the two very different models
\(\rightarrow\) CNN and AST models are good teachers for each other.
- via knowledge distillation (KD)
- performance of the student model improves & is better than the teacher model
Cross-Model Knowledge Distillation (CMKD)
-
knowledge distillation framework between a CNN and a Transformer model
-
(1) Distillation works bi-directionally
-
(a) CNN→Transformer & (b) Transformer→ CNN
-
( in general ) in KD, the teacher needs to be stronger than the student
\(\rightarrow\) but for CMKD, a weak teacher can still improve a student’s performance
-
-
(2) Student outperforms the teacher after knowledge distillation
- even when the teacher is originally stronger!
-
(3) KD between two models of the same class leads to a much smaller or no performance improvement
-
(4) Simple EfficientNet KD-CNN model with mean pooling outperforms the much larger AST model
- on FSD50K and ESC50 dataset.
Contribution
- first to explore bidirectional knowledge distillation between CNN and Transformer models
- conduct extensive experiments on standard audio classification datasets & find the optimal knowledge distillation setting
- Small and efficient CNN models match or outperform previous SOTA
2. Cross-Model Knowledge Distillation
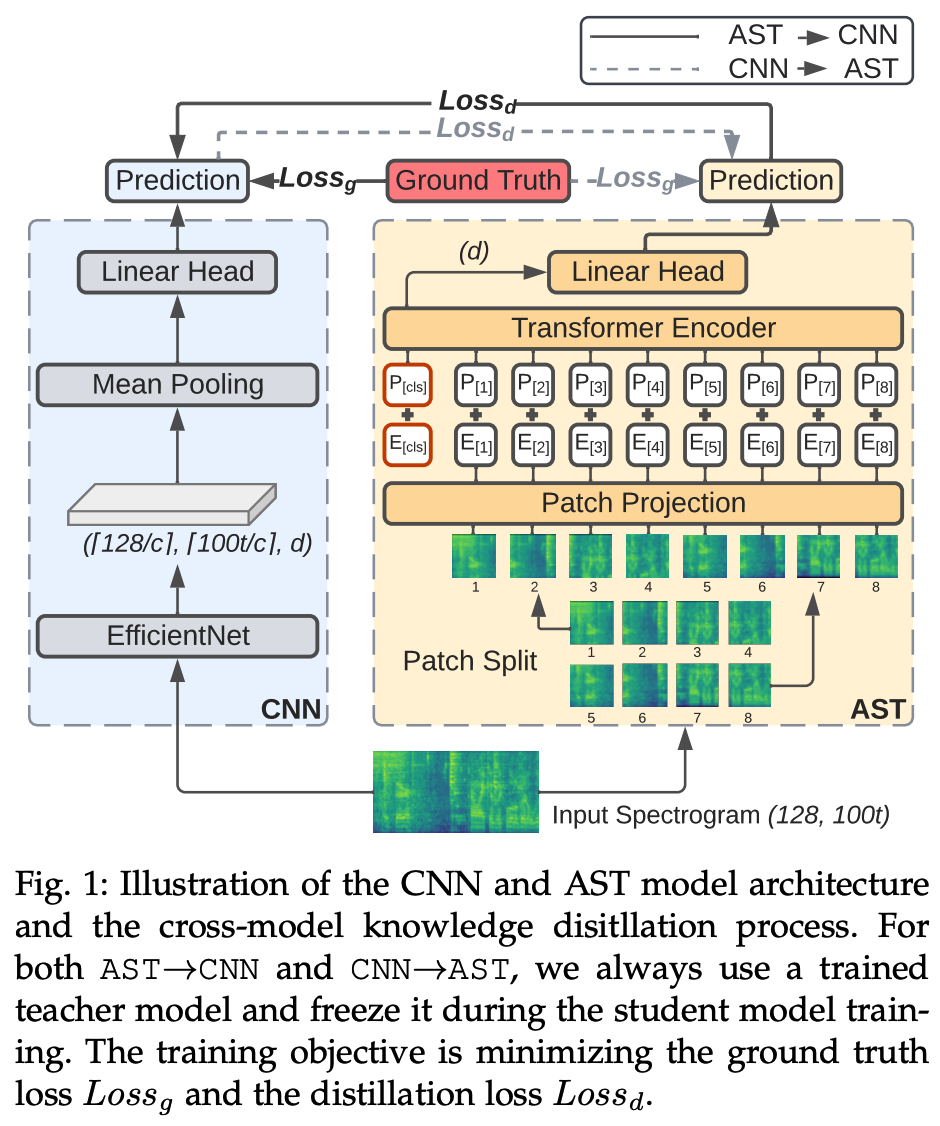
( Architecture of CNN and AST models )
2-1. CNNs
2-2. AST
2-3. Main difference between these two classes of models
2-4. Knowledge distillation setting and notation
(1) CNNs
CNN model without attention module [20]
- best CNN model on the audio classification task
Procedures
- [ Input ] input audio waveform of \(t\) seconds is converted into a sequence of 128 dim log Mel filterbank (fbank) features computed with a \(25 \mathrm{~ms}\) Hanning window every \(10 \mathrm{~ms}\).
- result : \(128 \times 100 t\) spectrogram ( = input to CNN )
- [ Output ] output of the penultimate layer = size \((\lceil 128 / c\rceil,\lceil 100 t / c\rceil, d)\) in frequency, time, and embedding dimension,
- mainly use EfficientNet-B2 [21]
- where \(c\) is the feature downsampling factor of the CNN
- [ Mean pooling ] time and frequency mean pooling
- produce \(d\) dim spectrogram-level representation
- [ Final result ] via linear layer
- sigmoid (for multi-label classification)
- softmax (for single-label classification)
(2) Audio Spectrogram Transformers
Original AST model proposed in [11]
- has the best performance on the audio classification task.
Procedures
-
[ Input ] same as CCN
- converted to a \(128 \times 100 t\) spectrogram in the same way as the CNN model.
-
[ Patching ] split the spectrogram
- into a sequence of \(N\) patches of size \(16 \times 16\)
- with an overlap of 6 in both time and frequency dimension
- number of patches : \(N=12\lceil(100 t-16) / 10\rceil\)
- into a sequence of \(N\) patches of size \(16 \times 16\)
-
[ Flatten ] flatten each \(16 \times 16\) patch to a \(1 \mathrm{D}\) patch embedding of size \(d\)
- via a linear projection layer ( = patch embedding layer )
-
[ POS ] add a trainable positional embedding (also of size \(d\) ) to each patch embedding
-
[ CLS token ] append a [CLS ] token at the beginning of the sequence
The resulting sequence is then input to a standard Transformer encoder
- [ Output of the [CLS] token ]
- serves as the audio spectrogram representation
- [ Final result ] via a linear layer
- sigmoid (for multilabel classification)
- softmax (for single-label classification)
Pretrained weight
For both CNN and AST models , use ImageNet pretraining
- from public model checkpoints
CNN weight: Channel difference
-
image : 3-channel \(\leftrightarrow\) audio : 1-d spectrogram
-
solution : average the weights corresponding to each of the 3 input channels of the vision model checkpoints
( = equivalent to expanding a 1-channel spectrogram to 3-channels with the same content, but is computationally more efficient )
(3) Difference between CNN and AST
see Introduction
(4) Knowledge distillation
Original knowledge distillation setup [28] with consistent teaching [29]
- this simple setup works better than the more complex attention distillation strategy [17] for the audio classification task.
Procedure
- step 1) Train the teacher model
- step 2) During the student model training, feed the input audio spectrogram with the exact same augmentations to teacher and student models (consistent teaching)
Loss for the student model training:
- \(\operatorname{Loss}=\lambda \operatorname{Loss}_g\left(\psi\left(Z_s\right), y\right)+(1-\lambda) \operatorname{Loss}_d\left(\psi\left(Z_s\right), \psi\left(Z_t / \tau\right)\right)\).
- Loss \(_g\) = ground truth loss
- Loss \(_d\) = distillation loss
Details
-
teacher model is frozen during the student model training.
- for Loss \(_d\), use the Kullback-Leibler divergence as \(L_{o s s_d}\).
- only apply \(\tau\) on the teacher logits
- fix \(\lambda=0.5\) and do not scale it with \(\tau\).
- Loss functions :
- CE loss & softmax : for single-label classification tasks such as ESC-50
- BCE loss & sigmoid : for multi-label classification tasks such as FSD50K and AudioSet.
3. Experiment Settings
(1) Datasets
3 widely-used audio classification datasets
- FSD50K [32], AudioSet [33], and ESC-50 [34]
FSD50K dataset [32]
- collection of sound event audio clips with 200 classes
- ( train, val, eval ) = ( 373134, 4170, 10231 )
- variable length from 0.3 to 30 s with an average of 7.6s.
- sample audio at \(16 \mathrm{kHz}\) and trim all clips to 10s.
We use the FSD50K dataset for the majority of our experiments in this paper (Section 4) for three reasons.
- (1) allows more rigorous experiments, since it has an official training, validation, and evaluation split
- (2) publicly available dataset, thus easy to reproduce
- (3) moderate size (50K samples)
- AudioSet (2M samples) and ESC-50 (2K samples)
- allows us to conduct extensive experiments with our computational resources
AudioSet [33]
- collection of over 2 million 10-second audio clips excised from YouTube videos
- labeled with the sounds that the clip contains from a set of 527 labels.
- ( balanced training, full training, and evaluation ) = ( 22k, 2M, 20k )
- use AudioSet to study the generalization ability of the proposed method on larger datasets.
ESC-50 [34]
- consists of 2,000 5-second environmental audio recordings organized into 50 classes.
- use ESC-50 to study the transferability of models trained with the proposed knowledge distillation method
(2) Training Settings
4. FSD50K experiments
(1) Which model is a good teacher?
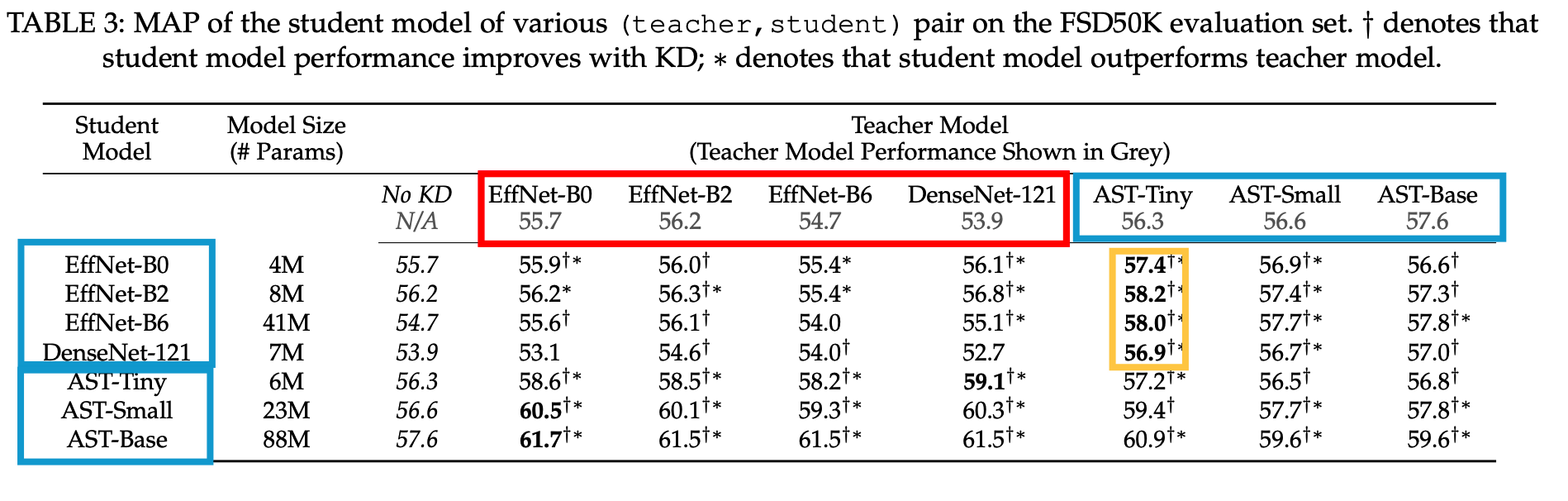
- Red : CNN
- Blue : AST
Findings 1) CNNs and ASTs are good teachers for each other
- While KD improves the student model performance in almost all settings, we find that models always prefer a different teacher
Findings 2) For both directions, the student model matches or outperforms its teacher
- ∗ denotes that student model outperforms teacher model
Findings 3) The strongest teacher is not the best teacher
- both CNN and AST perform better with a smaller (and weaker) teacher
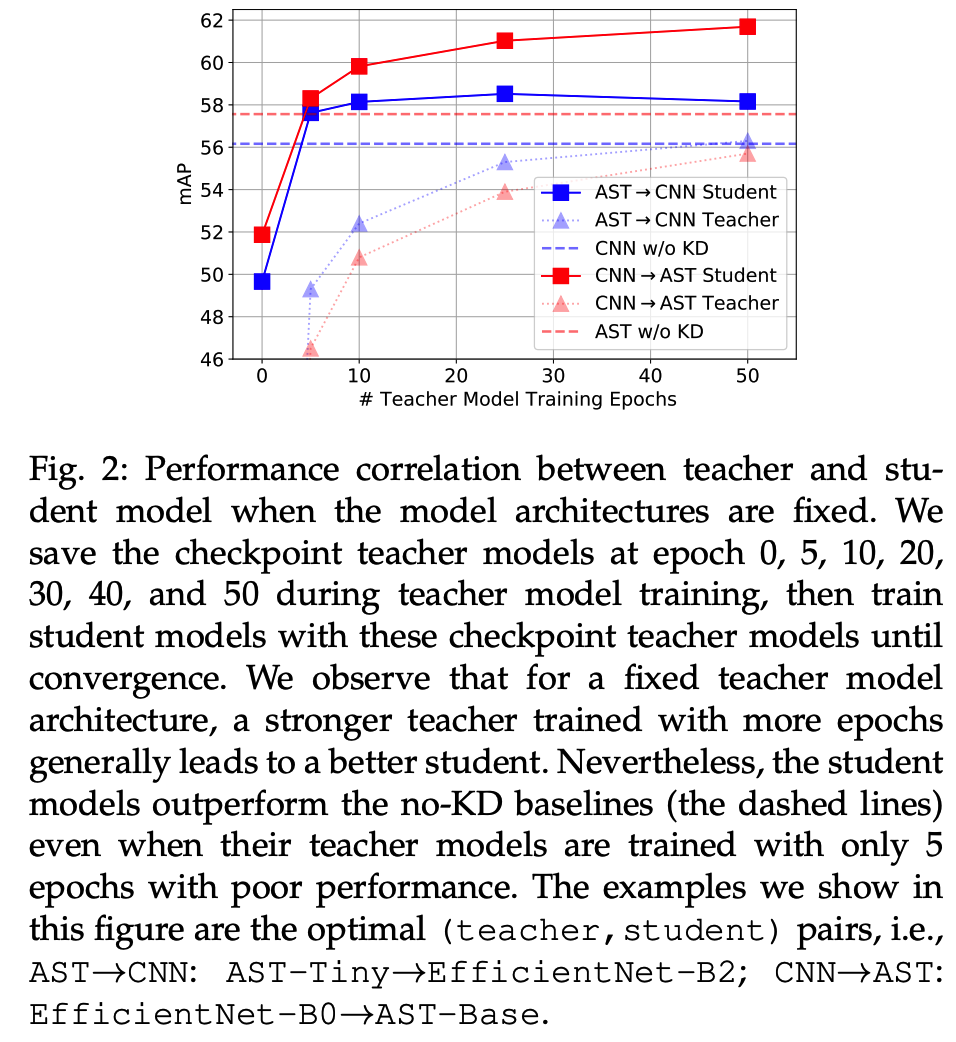
Finding 4) Self-KD leads to smaller or no improvement
Finding 5) Iterative knowledge distillation does not further improve model performance
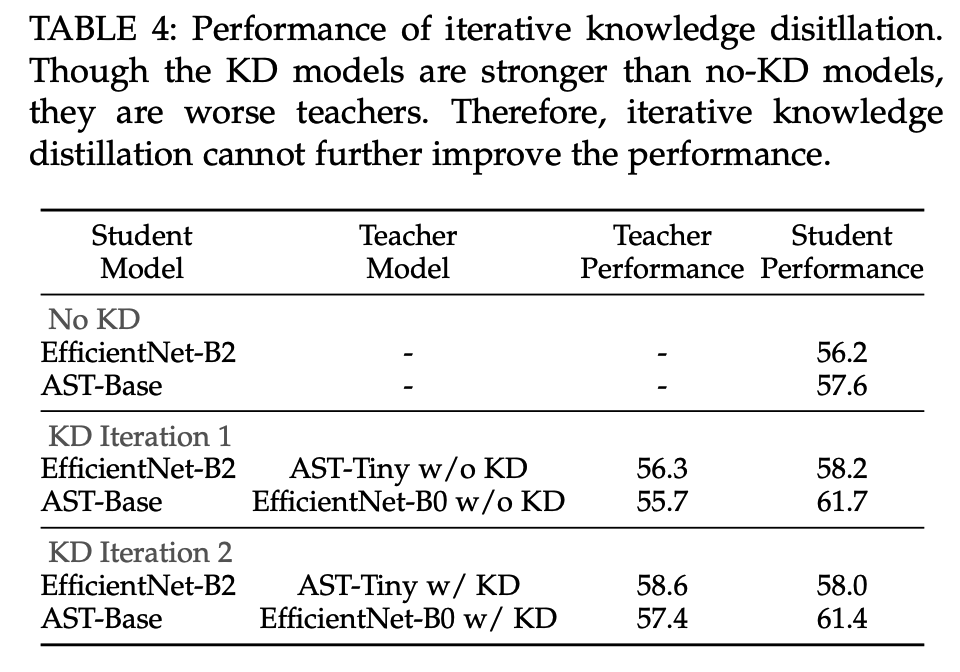
5. AudioSet and ESC-50 Experiments
(1) AudioSet Experiments
To study the impact of training data size…
\(\rightarrow\) conduct experiments on both the (1) balanced and (2) full training set
Goal : study the generalization of the proposed method
\(\rightarrow\) thus do not search the KD hyperparameters with AudioSet
( just re-use the optimal KD setting found with the FSD50K dataset )
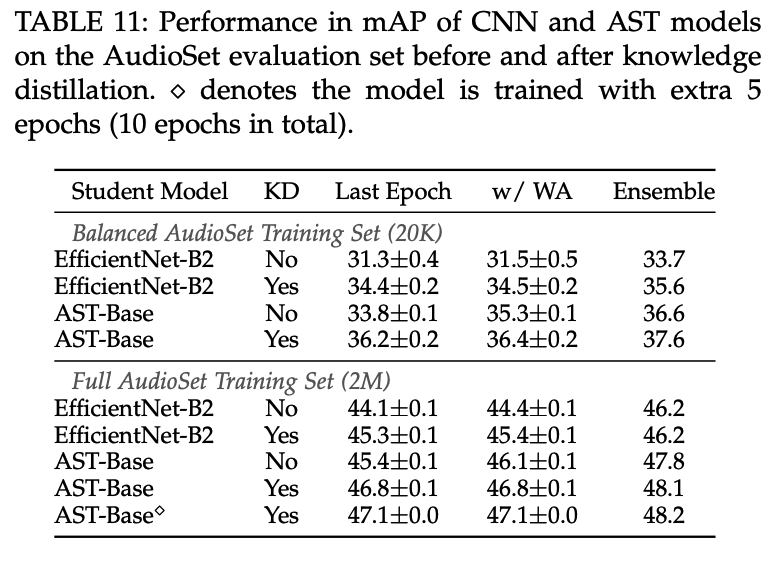
Findings 1) CMKD works out-of-the-box
-
KD works well on AudioSet for both CNN→AST and AST→CNN, demonstrating the proposed cross-model knowledge generalizes for audio classification tasks
-
training KD models with more epochs can lead to further performance improvement
( consistent with our finding that KD models are less prone to overfitting )
Findings 2) KD leads to larger improvement on smaller dataset
-
KD is more effective when the model is trained with the smaller balanced training set
( \(\because\) AST and CNN models get closer with more training data and cross-model knowledge distillation thus plays a smaller role )
Findings 3) The advantage of KD narrows after weight averaging and ensemble
Comparison with SOTA
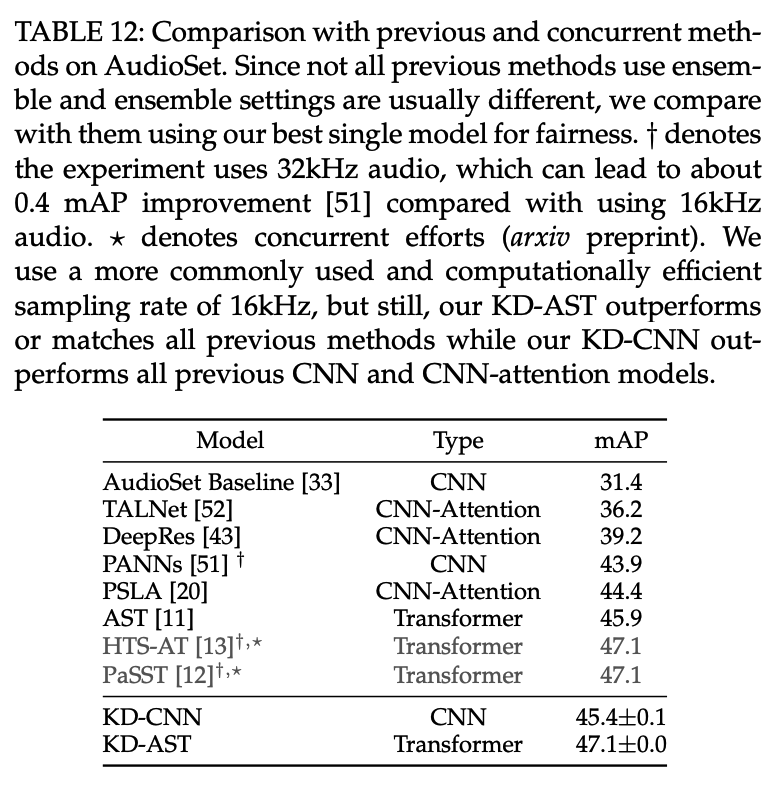
(2) ESC-50 Experiments