Augmenting Supervised Neural Networks with Unsupervised Objectives for Large-scale Image Classification
Contents
- Abstract
- Introduction
- Methods
- Unsupervised Loss for intermediate representations
- Network Augmentation with Autoencoders
- SAE-first
- SAE-all
- SAE-layerwise
- Ladder Network
0. Abstract
revisit the importance of Unsupervised learning
\(\rightarrow\) investigate joint supervised & unsupervised learning in a large-scale,
by augmenting existing NN with “decoding pathways for reconstruction”
1. Introduction
Key idea :
- Augment NN with decoding pathway for reconstruction
Details : AE architecture
- take a segment of classification network as ENCODER
- use the mirrored architecture as DECODING PATHWAY
- can be trained separately / together with encoder
2. Methods
-
(1) Training Objectives
-
(2) Architectures
(1) Unsupervised Loss for intermediate representations
Classifier ( Encoder )
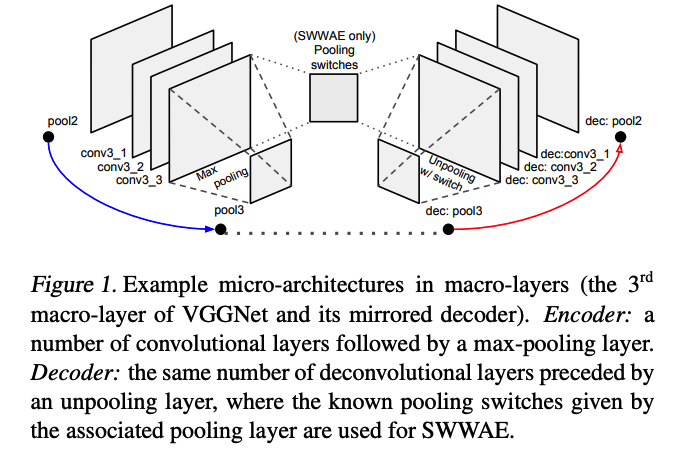
- feature extractor = group of cnn, before applying max-pooling
- macro-layer ( left half of Figure 1 )
- network of \(L\) conv-pooling macro layers :
- \(a_l=f_l\left(a_{l-1} ; \phi_l\right), \text { for } l=1,2, \ldots, L+1\).
- classification loss : \(C(x, y)=\ell\left(a_{L+1}, y\right)\)
\(\rightarrow\) trained by minimizing \(\frac{1}{N} \sum_{i=1}^N C\left(x_i, y_i\right)\)
2 limitations :
-
(1) training of lower intermediate layers might be problematic
\(\because\) gradient signals from the top layer vanishes
-
(2) fully superised objective guides the representation learning purely by the labels
Solution : auxiliary unsupervised loss to intermediate layers
- \(\frac{1}{N} \sum_{i=1}^N\left(C\left(x_i, y_i\right)+\lambda U\left(x_i\right)\right)\).
- \(U(\cdot)\) : unsupervised loss
(2) Network Augmentation with Autoencoders
generate a fuuly mirrored decoder as an auxiliary pathway of the original network
Reconstruction errors are …
- measured at network input (=first layer) : (1) SAE-first
- measured at all layers :
- (2) SAE-all
- (3) SAE-layerwise : decoding pathway = \(\hat{a}_{l-1}=f_l^{\text {dec }}\left(a_l ; \psi_l\right)\)
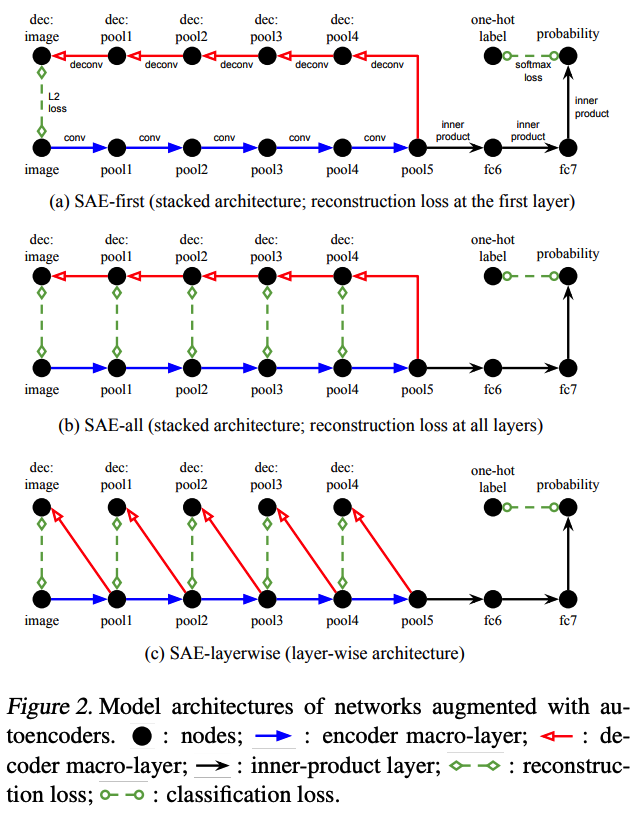
a) SAE-first
-
\(U_{\text {SAE-first }}(x)= \mid \mid \hat{x}-x \mid \mid _2^2\).
-
\(\hat{a}_L=a_L, \hat{a}_{l-1}=f_l^{\text {dec }}\left(\hat{a}_l ; \psi_l\right), \hat{x}=\hat{a}_0\).
b) SAE-all
- to allow more gradient to flow directly into the preceding macro layers
- \(U_{\mathrm{SAE}-\mathrm{all}}(x)=\sum_{l=0}^{L-1} \gamma_l \mid \mid \hat{a}_l-a_l \mid \mid _2^2\).
c) SAE-layerwise
- Layer-wise decoding architecture
a) & b) : encourages top-level conv features to preserve much info
c) : focus on inverting the clean intermediate activations from the encoder to the input of the associated macro-layer
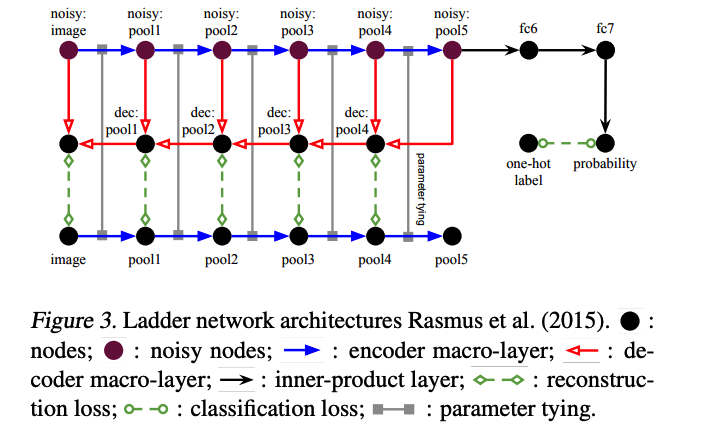
d) Ladder Network
-
more sophisticated way to augment!
-
but due to lateral connections …. noise must be added
( if not, just copy the clean activations from the encoder )
\(\rightarrow\) but the proposed method does not use this one!
\(\rightarrow\) makes the architecture more simple & standard