
( 참고 : 패스트 캠퍼스 , 한번에 끝내는 컴퓨터비전 초격차 패키지 )
mAP (Mean Average Precision)
(1) Mean Average Precision (mAP)
\(\mathrm{MAP}=\frac{\sum_{q=1}^{Q} \operatorname{AveP}(\mathrm{q})}{Q}\).
- average precision “per query”
- mean over “all query”
\(\rightarrow\) “mean” average precision!
(2) Precision ( in information retrieval )
\(\text { precision }=\frac{\mid\{\text { relevant documents }\} \cap\{\text { retrieved documents }\} \mid}{\mid\{\text { retrieved documents }\} \mid}\).
(3) Example
a) Precision
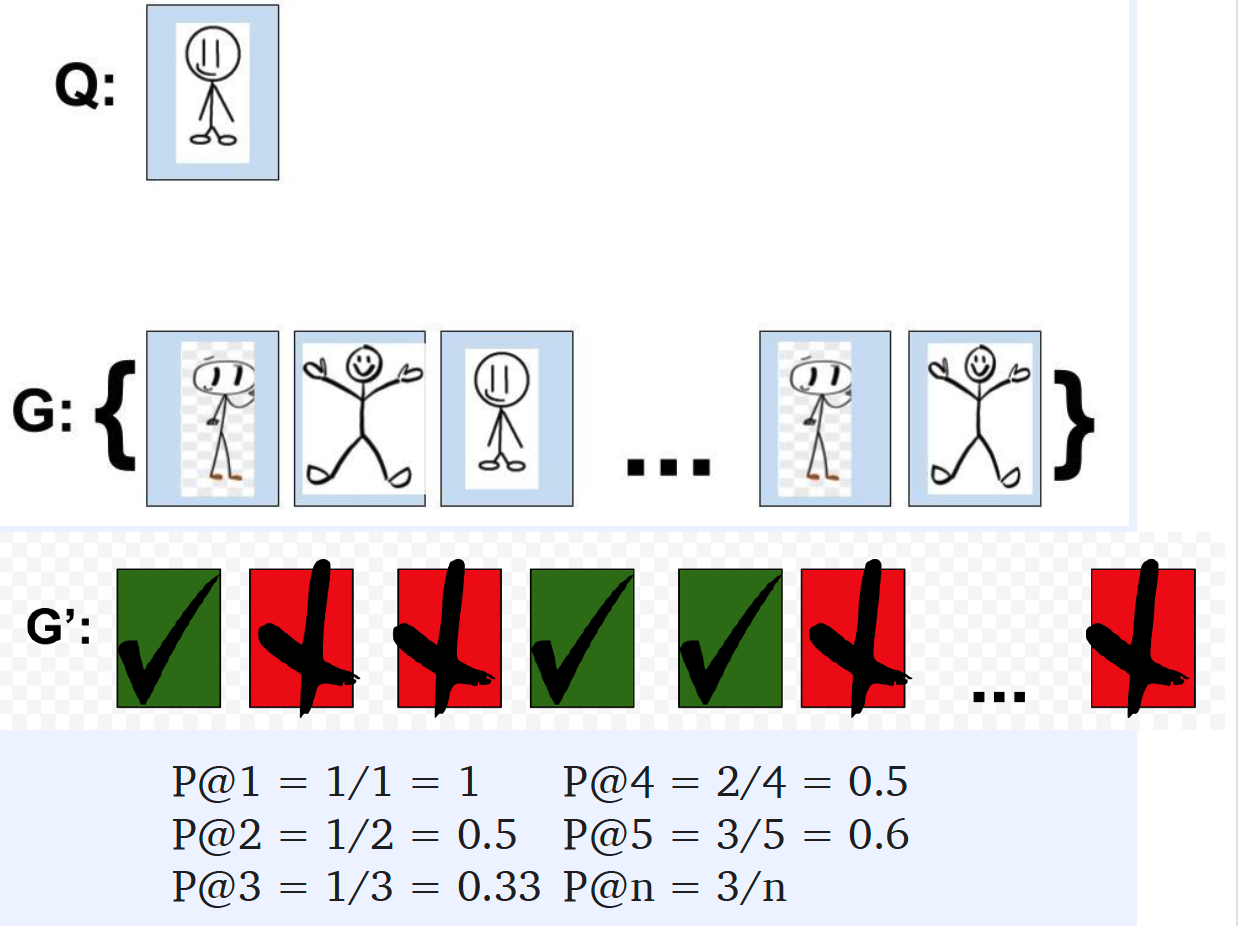
- Q : Query
- G : Guess ( high similarity in order )
Ex) out of 200 guesses, only 3 are correct
\(\rightarrow\) \(P@200 = 3/200\)
b) Average Precision
\(\mathrm{AP} @ n=\frac{1}{\mathrm{GTP}} \sum_{k}^{n} \mathrm{P} @ k \times \mathrm{rel} @ k\).
- \(P@k\) : precision
- \(rel@k\) : 1 if correct, 0 if wrong
Ex 1) Calculation of AP of query \(Q\), with GTP=3
- GTP = Ground Truth Positive
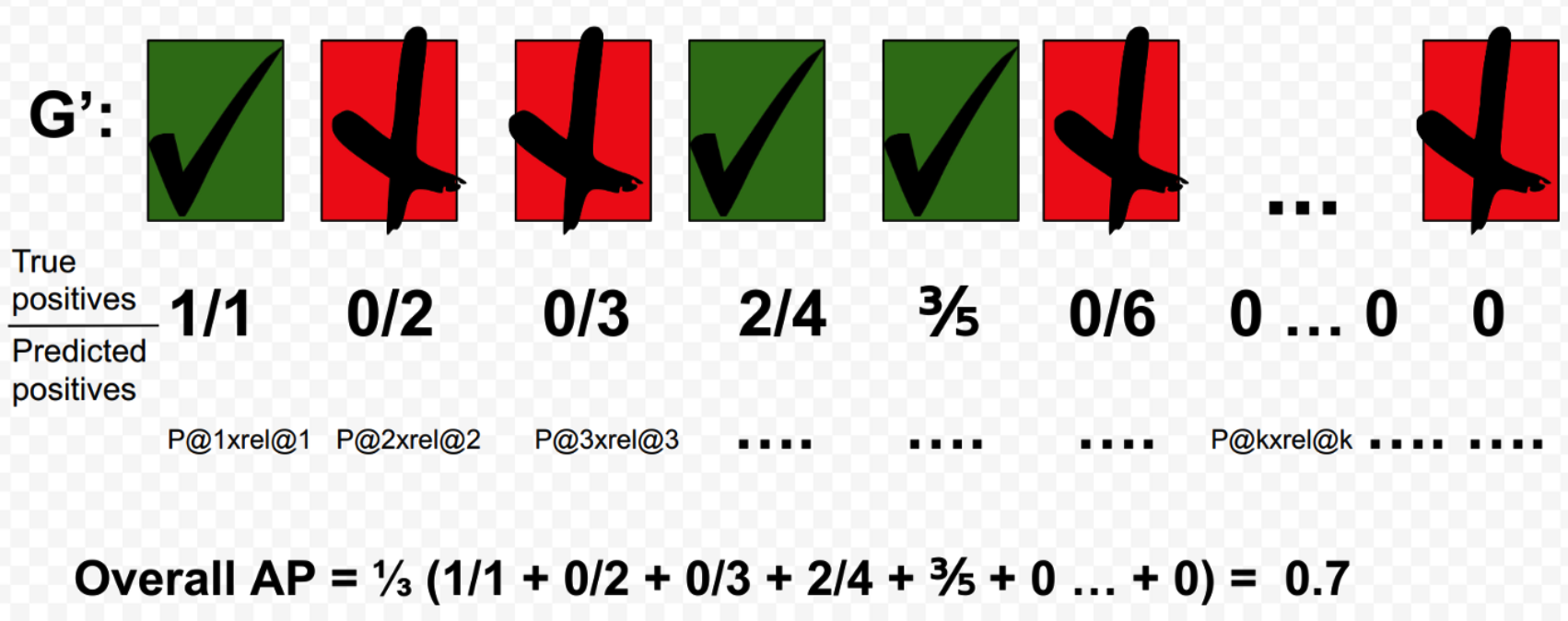
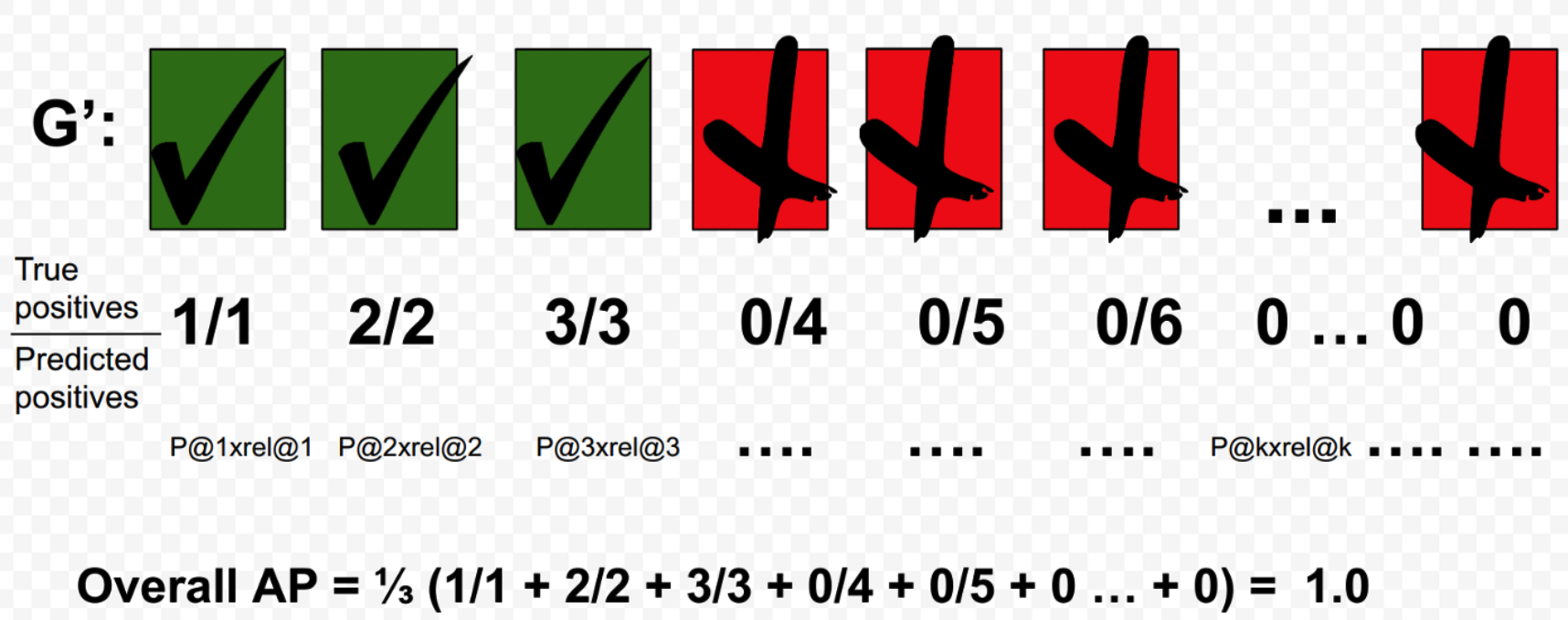
Ex 2) Calculation of perfect AP of query \(Q\), with GTP=3
c) MEAN Average Precision
if \(N\) queries…
\(\mathrm{mAP}=\frac{1}{N} \sum_{i=1}^{N} \mathrm{AP}_{i}\).
(4) Why not DIRECTLY OPTIMIZE mAP?
( Learning with Average Precision : Training Image Retrieval with a Listwise Loss, Revaud et al., ICCV 2019 )
-
key point in Image Retrieval
\(\rightarrow\) guess the RANKING of DB images similar to query image!
-
propose Average Precision Loss ( = Listwise AP Loss )

Average precision Loss
(1) Average Precision
- \(\mathrm{AP}_{\mathrm{Q}}\left(S^{q}, Y^{q}\right)=\sum_{m=1}^{M} \hat{P}_{m}\left(S^{q}, Y^{q}\right) \Delta \hat{r}_{m}\left(S^{q}, Y^{q}\right)\).
(2) Mean Average Precision ( of \(B\) queries ( = # of batches ) )
- \(\operatorname{mAP}_{\mathrm{Q}}(D, Y)=\frac{1}{B} \sum_{i=1}^{B} \mathrm{AP}_{\mathrm{Q}}\left(d_{i}^{\top} D, Y_{i}\right)\).
(3) Loss Function ( = Listwise AP Loss )
- \(L(D, Y)=1-\operatorname{mAP}_{\mathrm{Q}}(D, Y)\).
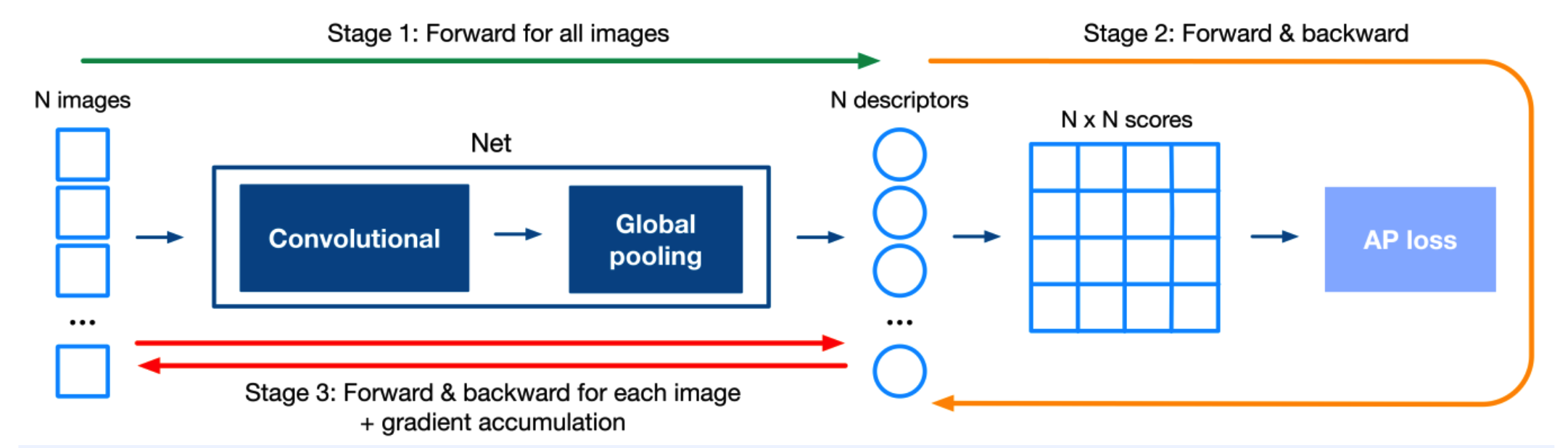
(5) Training procedure of AP Loss
( Listwise AP Loss )

- Fast convergence & Fast training
-
Less hyperparameters
-
need LARGE batch sampling
\(\rightarrow\) use Gradient Accumulation
(6) Code
- https://github.com/naver/deep-image-retrieval/blob/master/dirtorch/loss.py