
( 참고 : “FastCampus, 데이터 엔지니어링 올인원” )
[ Data Engineering ]
Data Lake & AWS S3
1. Data Lake vs Data Warehouse
| Data Lake (스키마 X) | Data Warehouse (스키마 O) | |
|---|---|---|
| data | Raw | Processed |
| purpose | 미정 | 정해짐 |
| user | 데이터 사이언티스트 | 비즈니스 전문가 |
| accessibility | High & Quick to update | Complicated & Costly |
2. ETL
(구) ETL : Extract(추출) - Transform(변형) - Load(로드)
(신) ELT : Extract(추출) - Load(로드) - Transform(변형)
“우선 Data Lake에 다 넣고 보자! 그 이후로, 상황에 맞게 재가공을 통해 가져오자”
3. Data Lake Architecture
다양한 Data from 다양한 부서 ( MKT 데이터, GA 데이터, … )
일단 Data Lake에 다 넣어 !
4. Data Pipeline
데이터를 어디서 가져와서. 어떻게 저장하고, 어떻게 처리할지 등등 전반적인 과정
-
어떻게 관리할 것인가?
-
스케줄링은 어떻게 할 것인가?
-
에러 핸들링은 어떻게 할 것인가?
-
데이터 백필은 어떻게 할 것인가?
( 에러가 생긴다면, 해당 데이터를 어떻게 다시 확보할 것인지? )
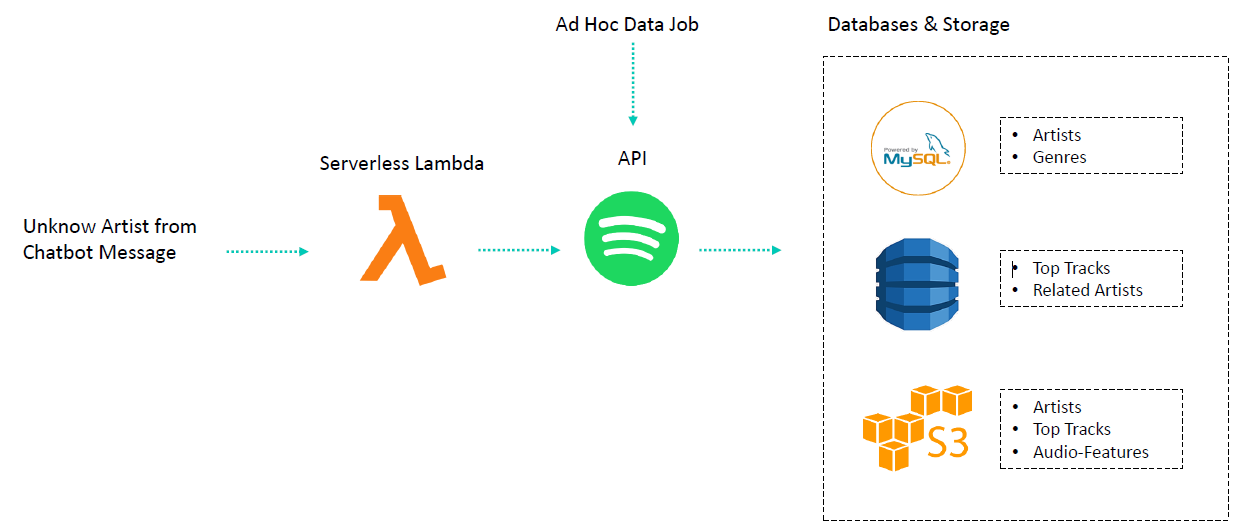
5. AWS S3로 Data Lake 구축하기
S3 = Simple Storage System
S3를 통해서 데이터를 저장하는 방법에 대해 알아볼 것이다!
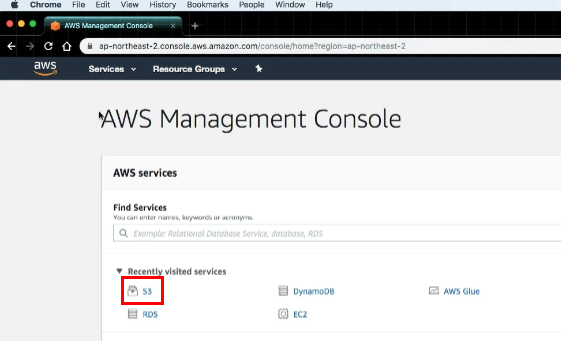
-
Bucket : S3의 “폴더” ( Bucket안에 데이터를 저장/관리한다 )
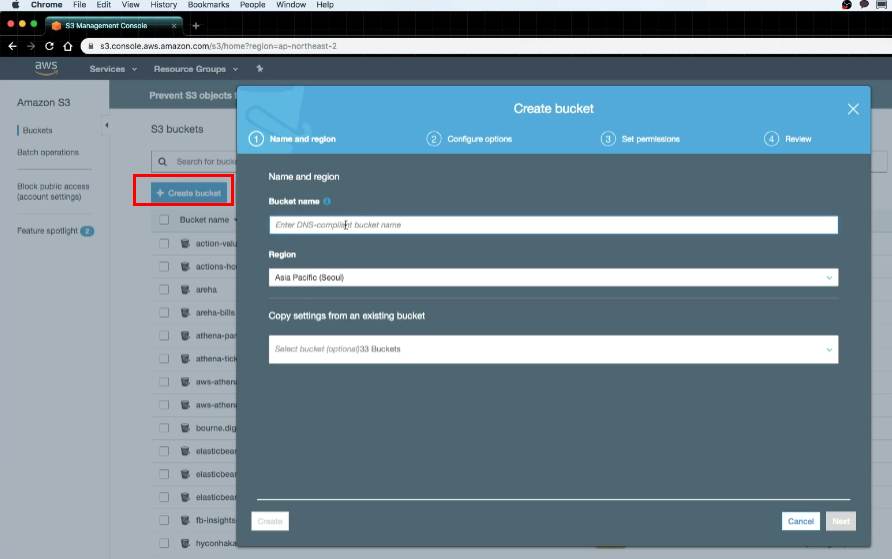
-
Bucket 생성하기
AWS Glue
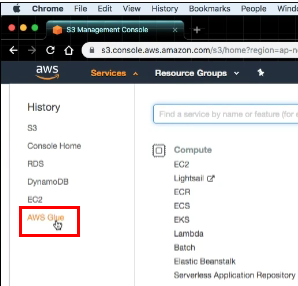
-
AWS Glue를 통해, 다양한 테이블의 스키마를 관리할 수 있다.
-
AWS Crawler
Data Lake안에서 Table을 생성하고 데이터를 저장할 것.
Crawler는 이러한 Table의 변형이 생기면 즉각 발견하고 반영한다.
그렇다면, S3에 어떠한 방식으로 데이터를 저장할 것인가!?