
Chapter 7. Adversarial Regularizer (Variational) Graph Autoencoders
( 참고 : https://www.youtube.com/watch?v=JtDgmmQ60x8&list=PLGMXrbDNfqTzqxB1IGgimuhtfAhGd8lHF )
1) Adversarial Regularizer GAE ( VGAE )
goal : 잠재 벡터 (\(Z\)) 가 최대한 continuous 한 space에 놓이게끔!
2) ARGA/ARGVA vs GAE/GVAE
GAE/GVAE
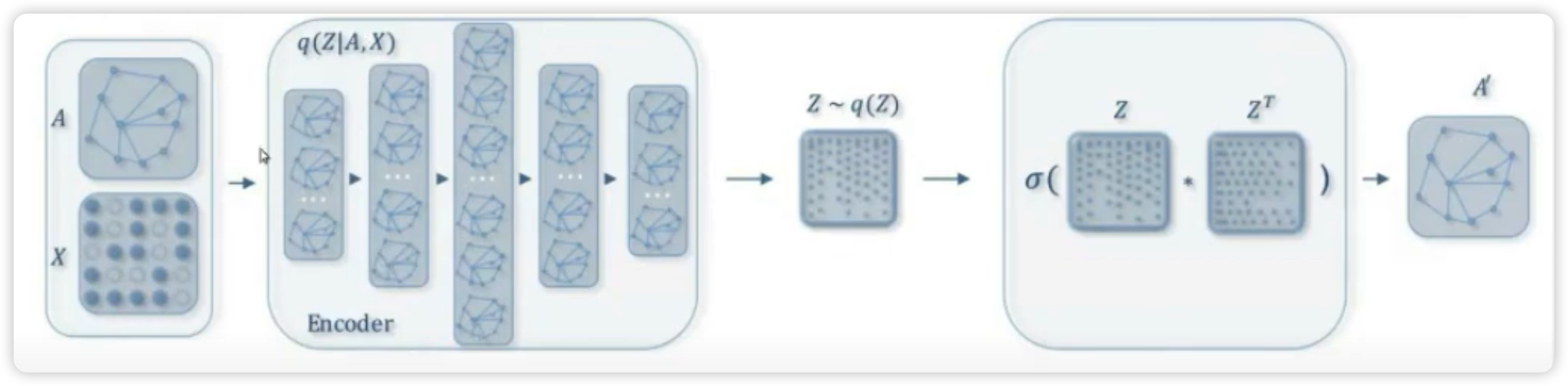
ARGA/ARGVA
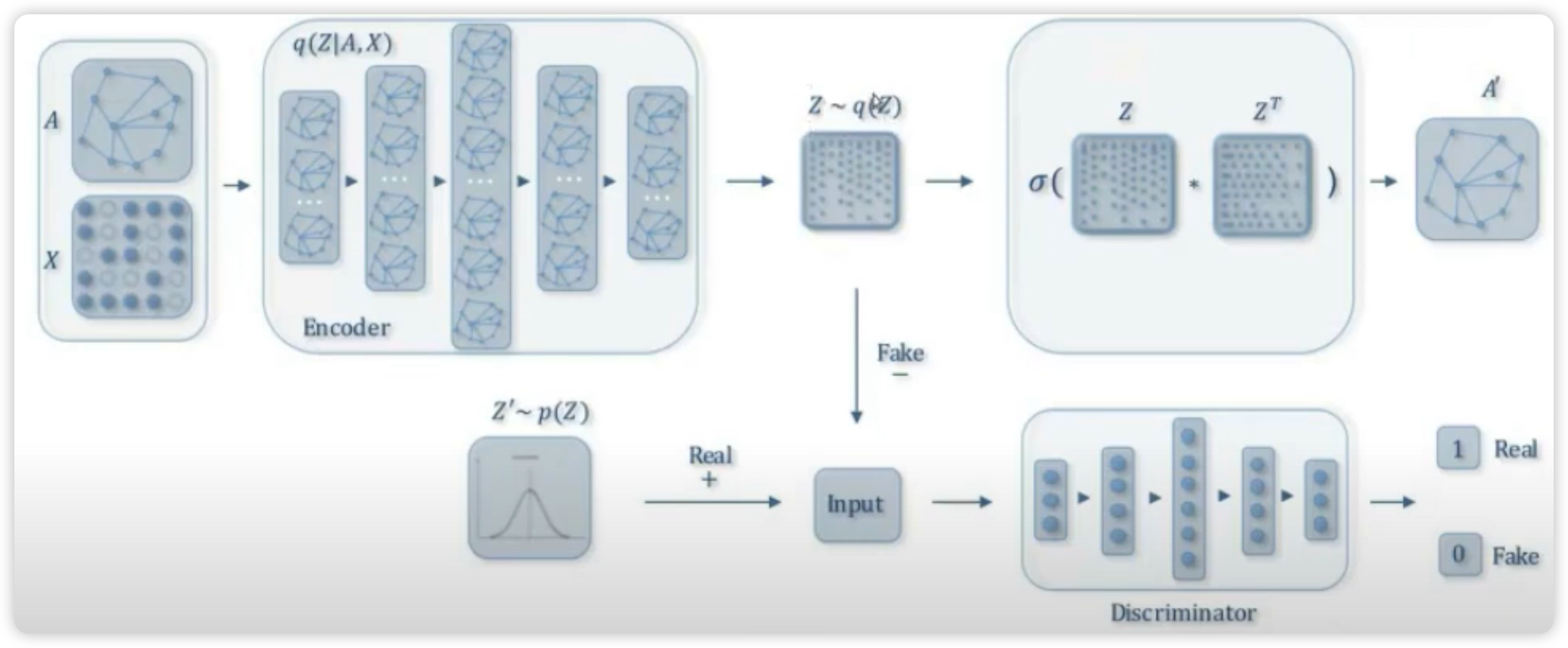
그렇다면, 무엇이 real data이고,무엇이 fake data인가?
- real data : \(Z’ \sim p(Z)\)
- 정규분포 N(0,1)에서 샘플한 데이터
- fake data : \(Z \sim q(Z)\)
- 그래프의 노드가 임베딩된 latent representation
Loss Function :
- \(\min _{\mathcal{G}} \max _{\mathcal{D}} \mathbb{E}_{\mathbf{z} \sim p_{z}}[\log \mathcal{D}(\mathbf{Z})]+\mathbb{E}_{\mathbf{x} \sim p(\mathbf{x})}[\log (1-\mathcal{D}(\mathcal{G}(\mathbf{X}, \mathbf{A})))]\).
3) Encoder ( variational ver )
( GVAE의 encoder와 동일하다 )
class VEncoder(torch.nn.Module):
def __init__(self, in_channels, out_channels):
super(VEncoder, self).__init__()
self.conv1 = GCNConv(in_channels, 2 * out_channels, cached=True)
self.conv_mu = GCNConv(2 * out_channels, out_channels, cached=True)
self.conv_logstd = GCNConv(2 * out_channels, out_channels, cached=True)
def forward(self, x, edge_index):
x = F.relu(self.conv1(x, edge_index))
return self.conv_mu(x, edge_index), self.conv_logstd(x, edge_index)
4) Discriminator
class Discriminator(torch.nn.Module):
def __init__(self, in_channels, hidden_channels, out_channels):
super(Discriminator, self).__init__()
self.lin1 = torch.nn.Linear(in_channels, hidden_channels)
self.lin2 = torch.nn.Linear(hidden_channels, hidden_channels)
self.lin3 = torch.nn.Linear(hidden_channels, out_channels)
def forward(self, x):
x = F.relu(self.lin1(x))
x = F.relu(self.lin2(x))
x = self.lin3(x)
return x
5) Modeling
모델 생성
from torch_geometric.nn.models.autoencoder import ARGVA
latent_size = 32
encoder = VEncoder(data.num_features,
out_channels=latent_size)
discriminator = Discriminator(in_channels=latent_size,
hidden_channels=64,
out_channels=1)
model = ARGVA(encoder, discriminator)
6) Train
적대적 학습 과정이 이루어진다는 차이점이 있다
def train():
model.train()
encoder_optimizer.zero_grad()
z = model.encode(data.x, data.train_pos_edge_index)
#-------------------------------------------------------#
# (1) update DISCRIMINATOR
for i in range(5):
idx = range(num_nodes)
discriminator.train()
discriminator_optimizer.zero_grad()
discriminator_loss = model.discriminator_loss(z[idx])
discriminator_loss.backward(retain_graph=True)
discriminator_optimizer.step()
#-------------------------------------------------------#
# (2) update ENCODER
loss = 0
## 1) regularizer loss
loss = loss + model.reg_loss(z)
## 2) reconstruction loss
loss = loss + model.recon_loss(z, data.train_pos_edge_index)
## 3) KL-divergence loss
loss = loss + (1 / data.num_nodes) * model.kl_loss()
loss.backward()
encoder_optimizer.step()
#-------------------------------------------------------#
return loss