
Chapter 8. Graph Generation
( 참고 : https://www.youtube.com/watch?v=JtDgmmQ60x8&list=PLGMXrbDNfqTzqxB1IGgimuhtfAhGd8lHF )
1) Learning social Graph using topologies using GANs
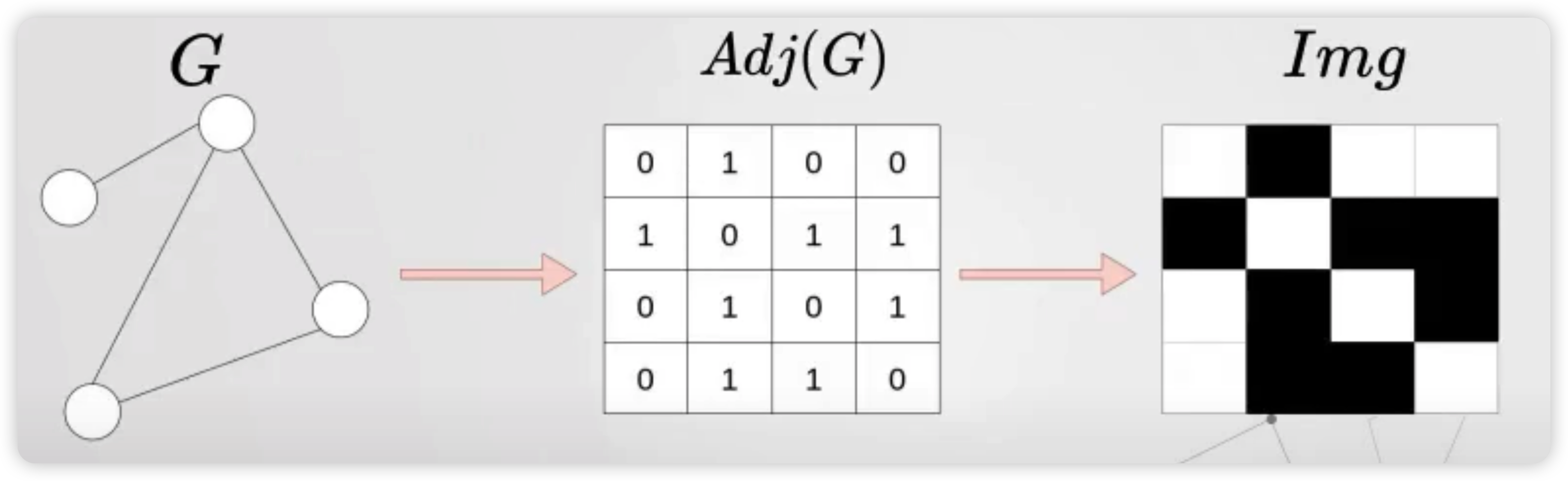
아래와 같은 그래프가 있을때, ( 왼쪽 )
-
우리는 이것을 adjacency matrix로 나타낼 수 있고 ( 가운데 )
-
이것을 마치 1/0의 흑/백 이미지로 나타낼 수 있다. ( 오른쪽 )
하지만, order invariant하지 않은 문제 때문에 이렇게 나오게 되는 이미지가 고유하지 않음을 우리는 안다.
따라서, 우리는 ( 다양한 노드 순서 조합으로 ) 여러 이미지를 생성할 수 있고, 이것을 마치 REAL image 처럼 사용한다.
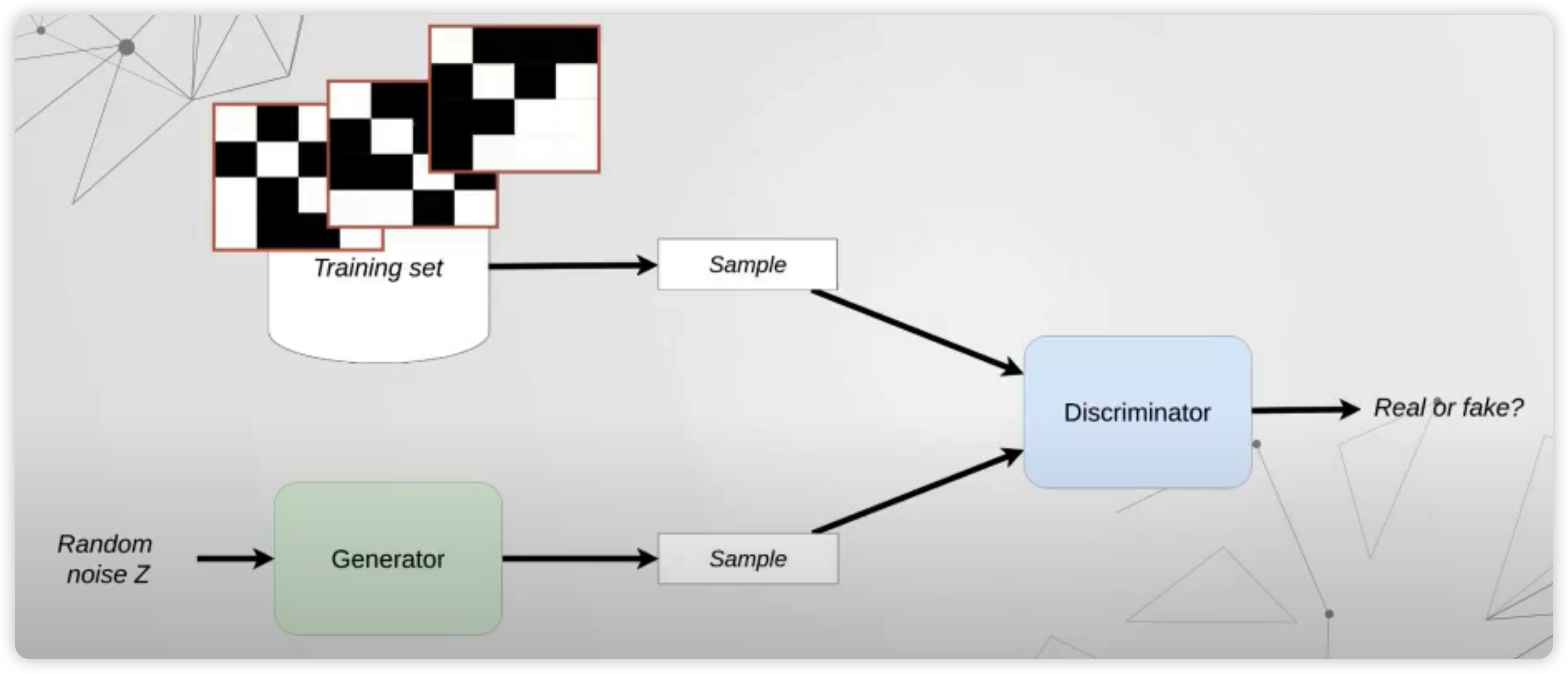
Generator
위의 그림에서, FAKE IMAGE가 어떻게 생성되는지 알기 위해, Generator를 자세히 들여다보자.
우선, (임의로 설정한) 100차원의 랜덤 벡터를 생성한다.
그런 뒤, hidden layer를 여러번 태운 뒤, 마지막에 \(N \times N\) matrix ( \(N\) : 노드의 개수 ) 를 생성하기위해, \(N\times N\) 차원의 hidden layer를 둔다. 그리고 이 마지막 layer는, sigmoid를 거친 뒤, 일정 threshold를 기준으로 1/0으로 나오게 된다.
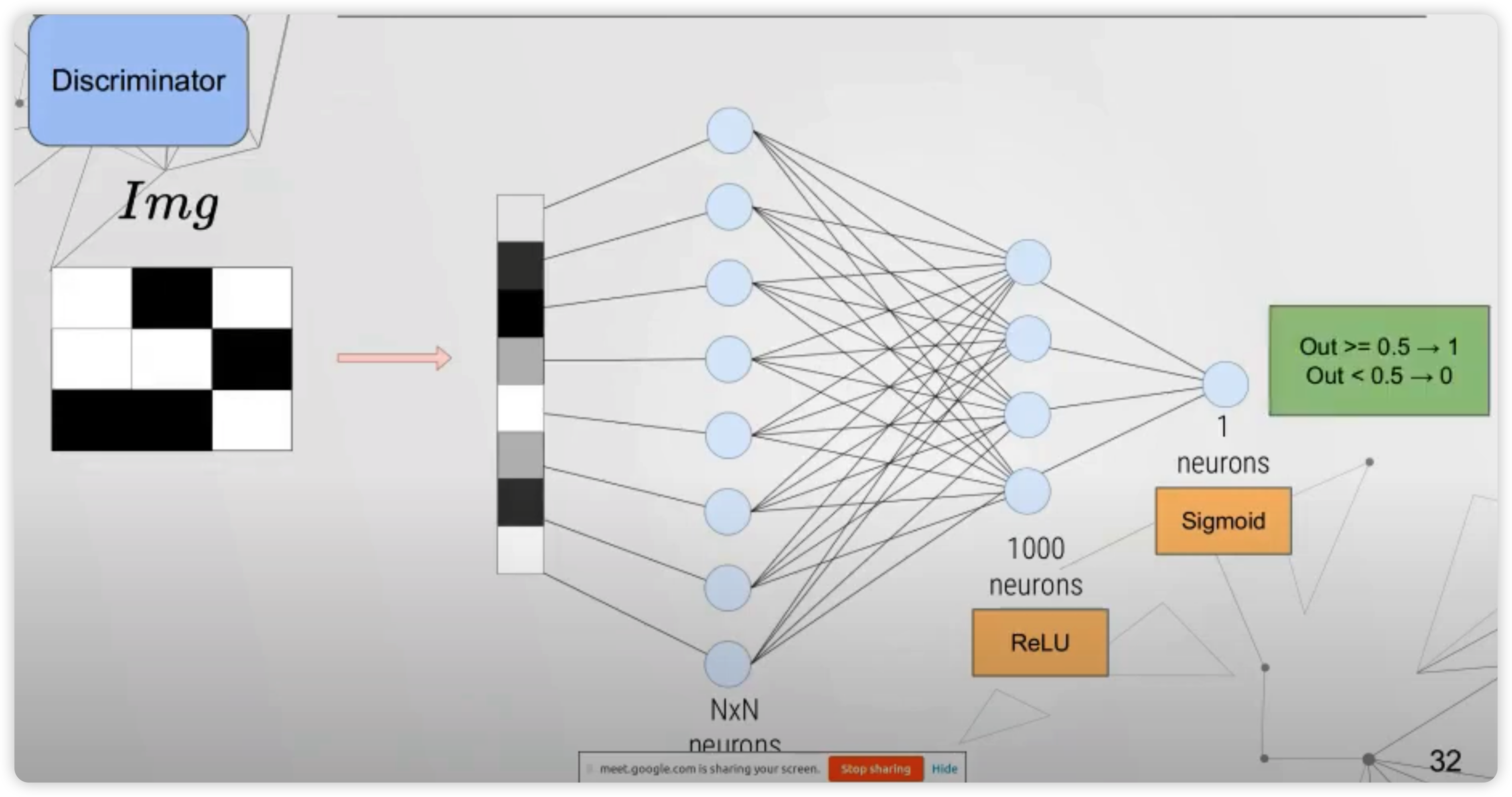
Discriminator
이번엔, real & fake 이미지를 인풋으로 받는 discriminator에 대해서 알아볼 것이다.
우선, \(N \times N\) 차원의 이미지가 인풋으로 들어온다.
이것은 \(N^2\)의 벡터로 flatten 된 뒤, 여러 hidden layer들을 거쳐서 최종적으로 1개의 scalar 값으로 나오게 된다.
이 값도 마찬가지로 일정 threshold를 기준으로, 1/0으로 판별되게 된다.
위의 설명을 통해서 유추할 수도 있겠지만, 그닥 scalable한 방법은 아닌것 같다.
노드의 개수가 매우 크면, 모델의 파라미터수도 매우 커지게 되기 때문이다 ( \(N \times N\) 차원의 hidden layer )
2) NetGAN
NetGAN 또한, graph generation을 위한 알고리즘 중 하나이다.
아래 그림은 NetGAN 을 도식화 한 것이다.
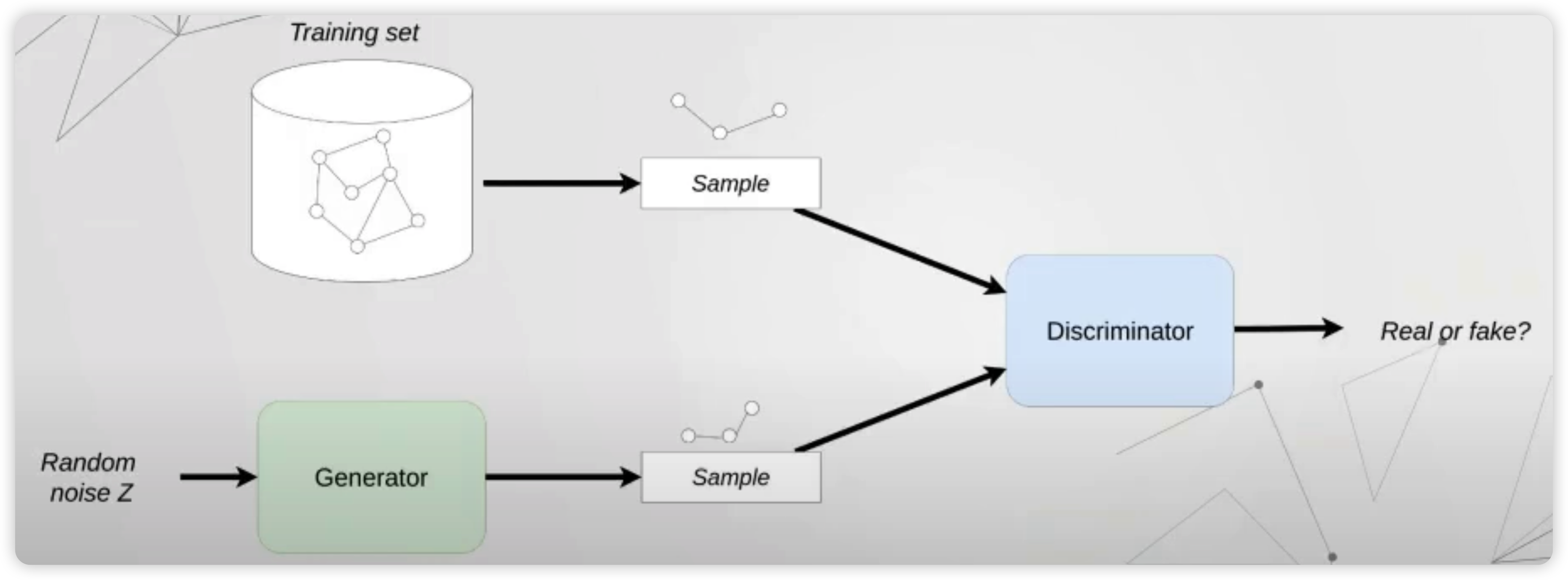
위 그림에서 보면, training set에서 일정 random walk 만큼의 샘플이 이루어진다. ( = REAL sample )
FAKE sample 또한, 이와 같은 길이만큼 random noise로부터 생성된다.
Generator
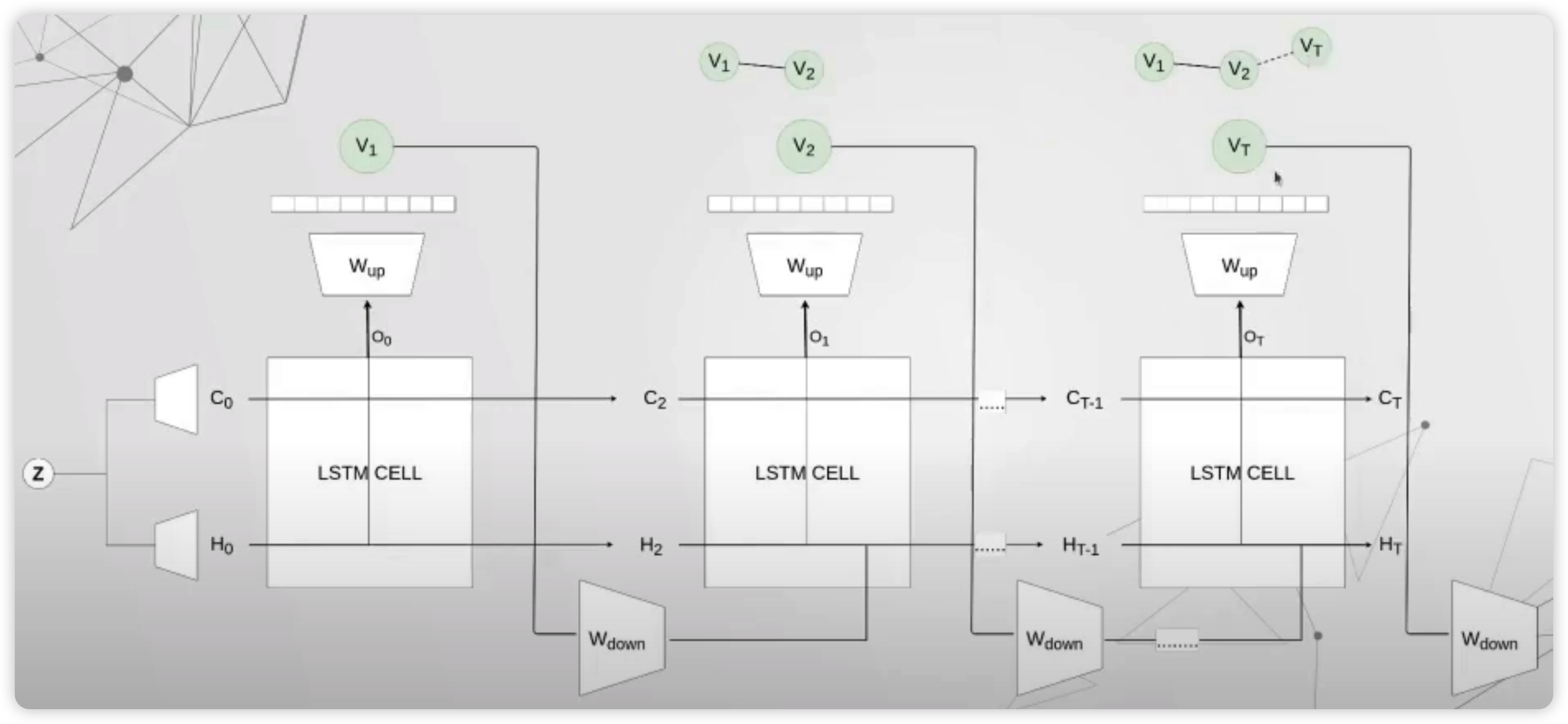
Fake sample이 어떠한 방식으로 생성되는지 들여다보자.
우선, (임의의 16차원의) 랜덤 백터를 샘플링한다. 이것은 크게 2부분으로 나뉘어서 ( 각각 LSTM의 hidden / cell state를 담당 ) 모델에 태운다.
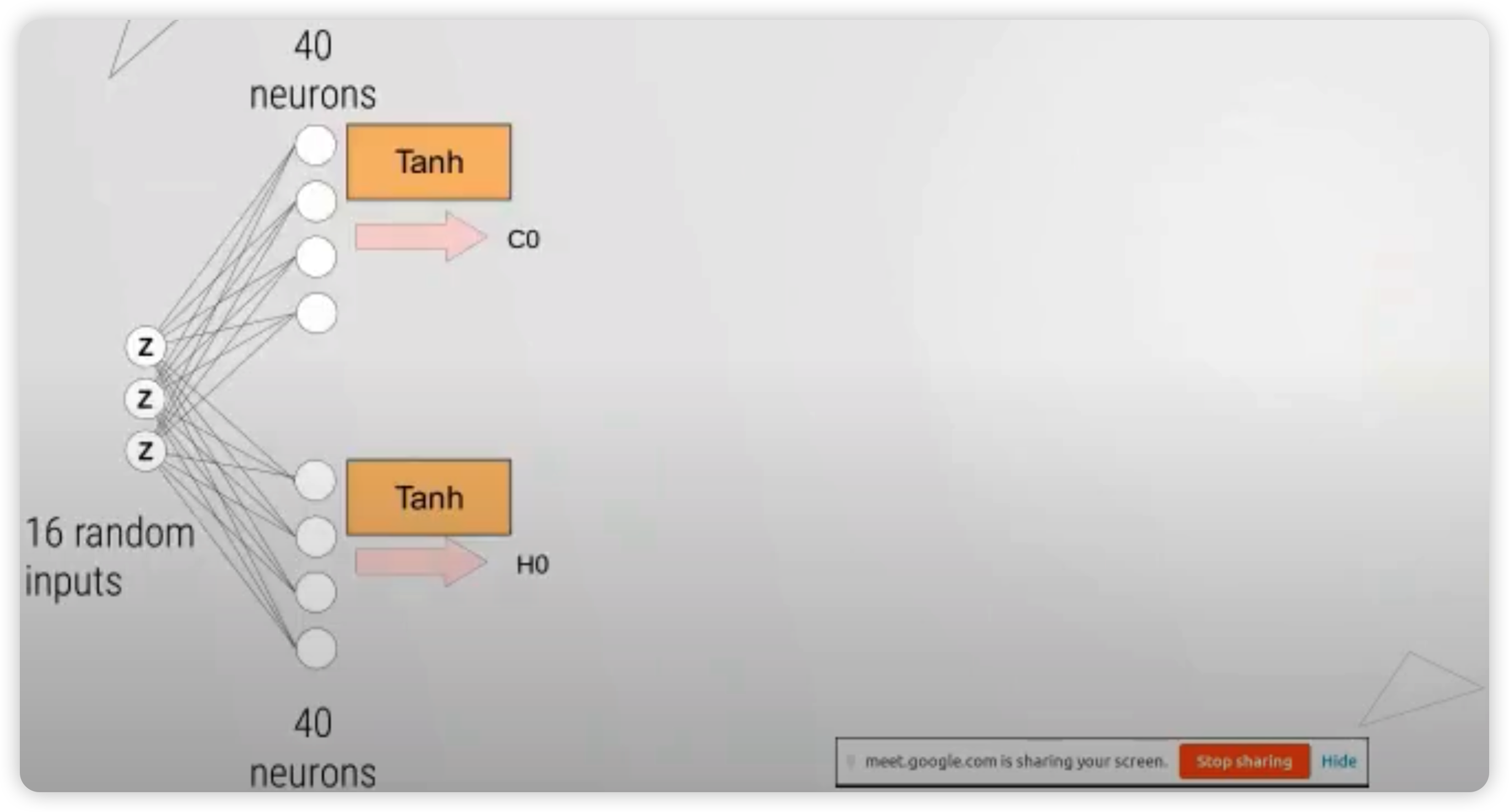
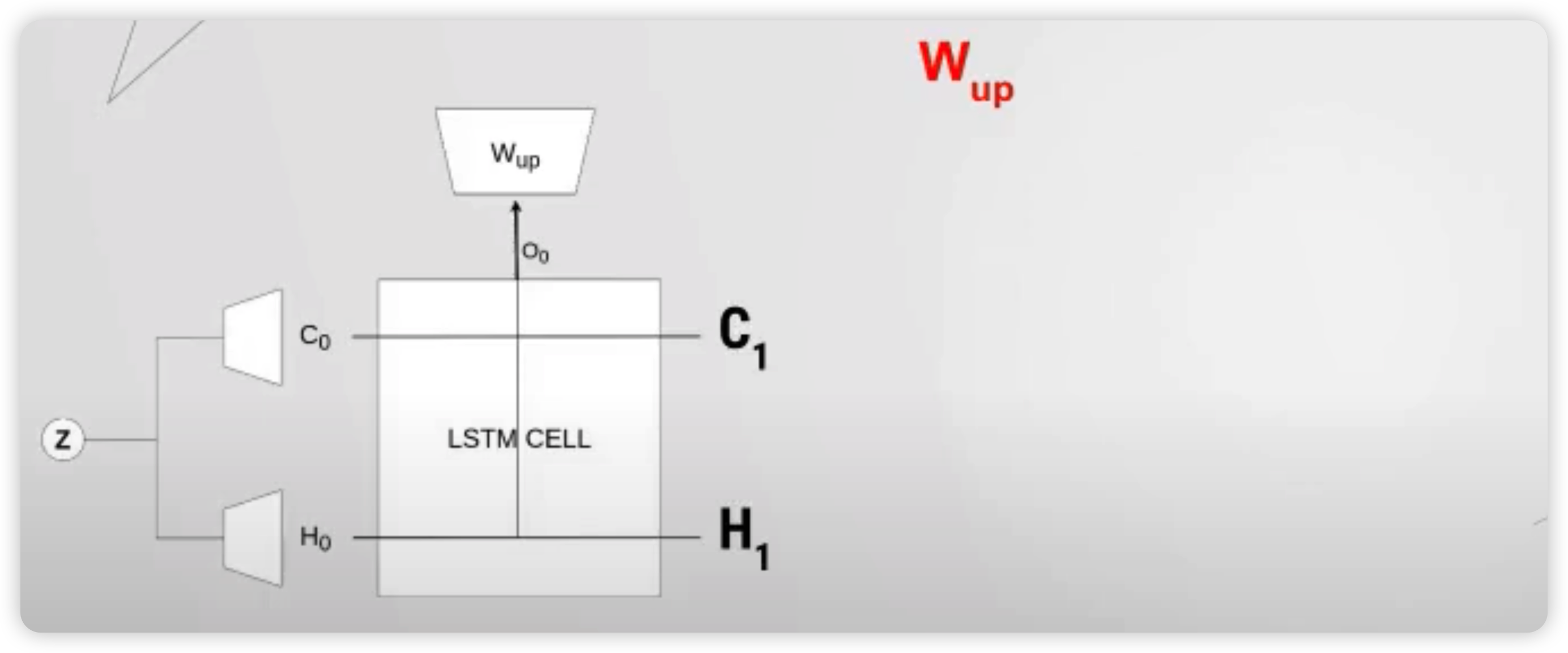
위 그림에서 알 수 있듯, 매 timestep마다 나오게되는 output은, LSTM의 output에서 바로 끝나는 것이 아니라, \(W_{up}\)이라는 추가적인 layer를 거치게된다.
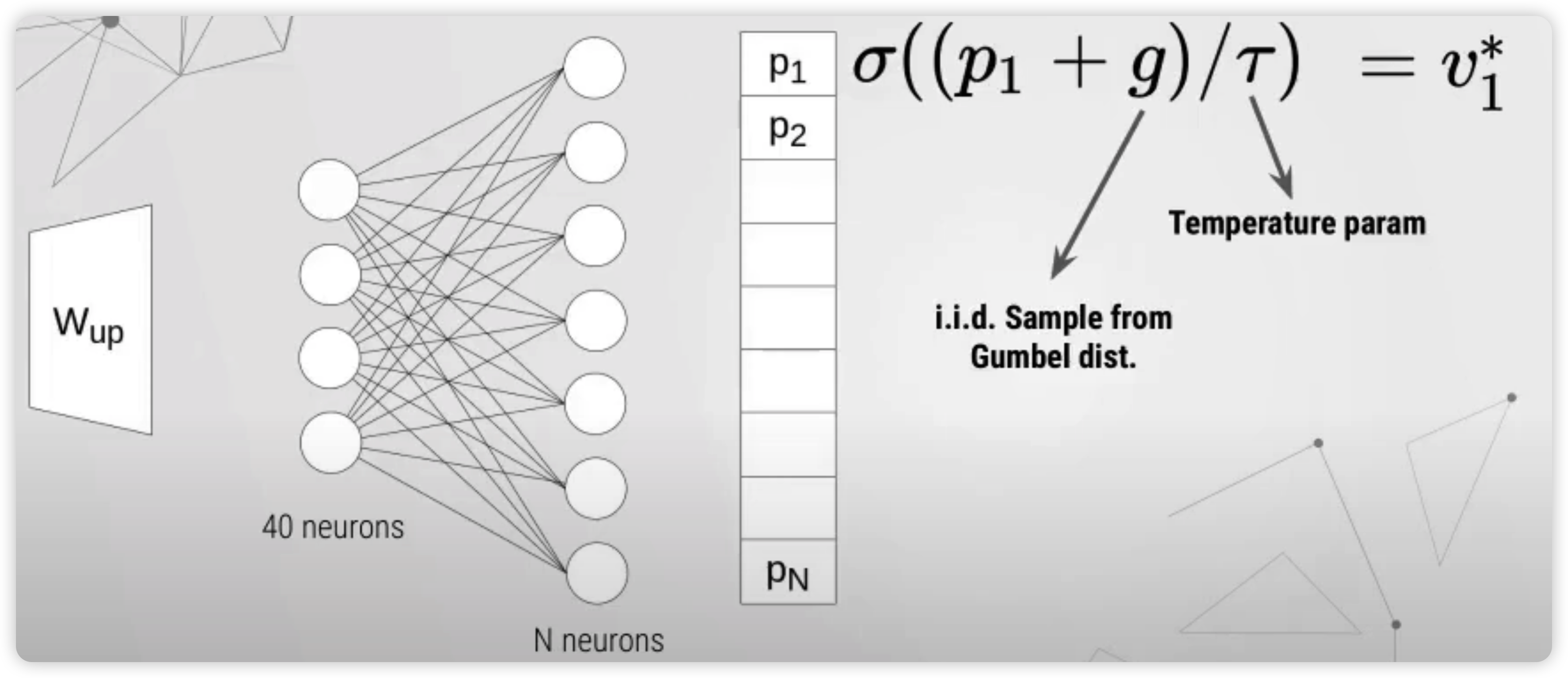
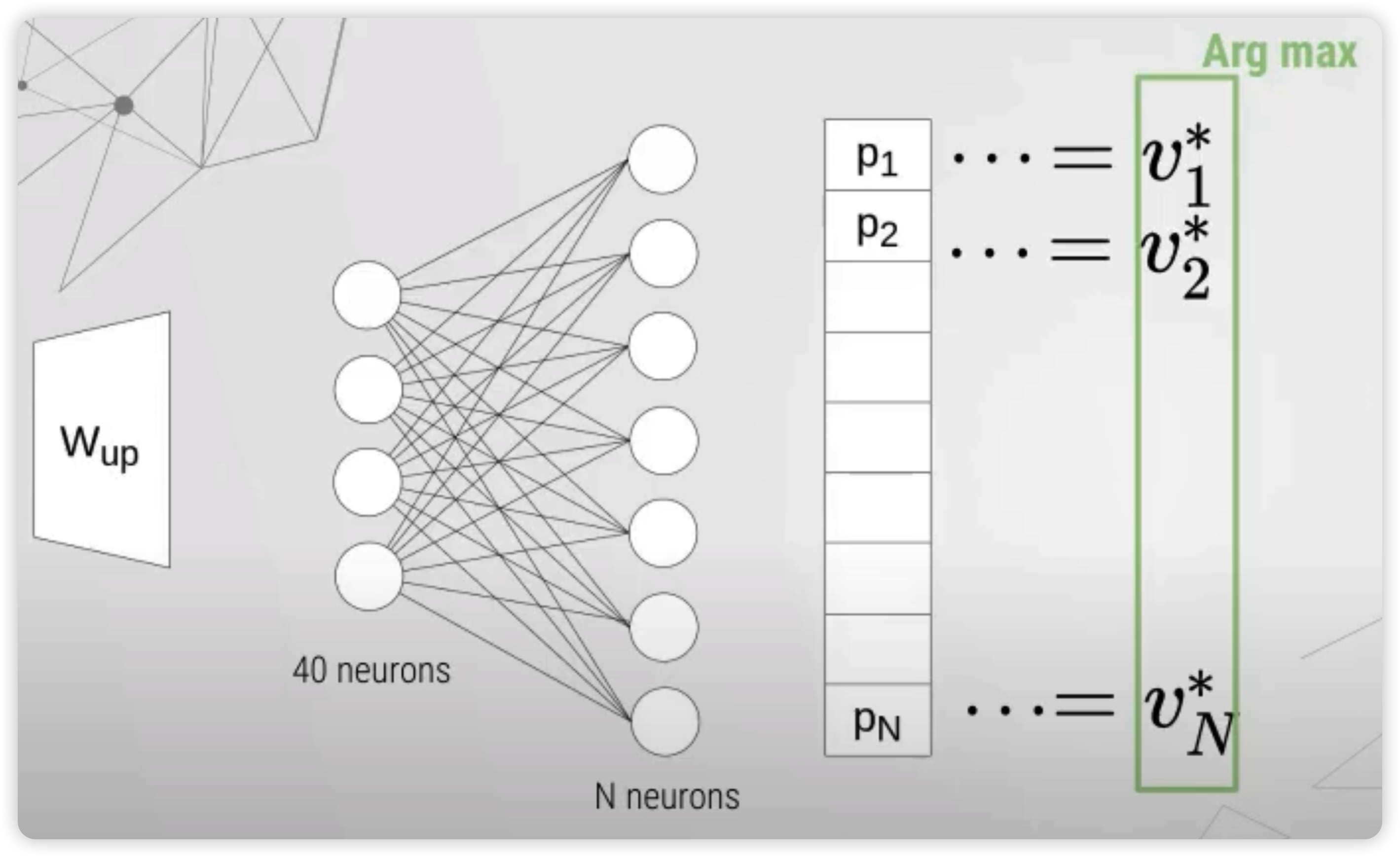
예를들어, 40차원의 output이 나오게 된다면, 이것은 linear layer를 통해 \(N\)차원의 벡터로 매핑이 되고 ( \((p_1, \cdots p_N)\) ), ( 일종의 categorical variable에 대한 확률 분포로써 생각 ), 아래의 수식에 따라 값이 \((v_1^* \cdots v_n^*)\) 로 변하게 된다. 이 \(N\) 개의 값들에 대해 argmax를 취해서, 최종적인 하나의 노드를 선택하게 되는 것이다.
위의 알고리즘에 따라, Generator를 보다 상세히 나타낸 것은 아래 그림과 같다.
( 매 timestep의 output은, \(W_{down}\) 이라는 layer를 거쳐서 hidden state에 추가적인 정보로 반영됨을 알 수 있다 )
Discriminator
이번엔, Discriminator가 어떠한 방식으로 real/fake 이미지를 판별하는지 살펴보자.
우선, discriminator 또한 LSTM 구조를 띄고 있고, 매 timestep마다의 input은 노드의 인덱스에 대한 one-hot 벡터이다.
그리고 마지막 hidden state에서, 이 random walk 데이터가 real/fake인지에 대한 판별이 이루어지게 된다.
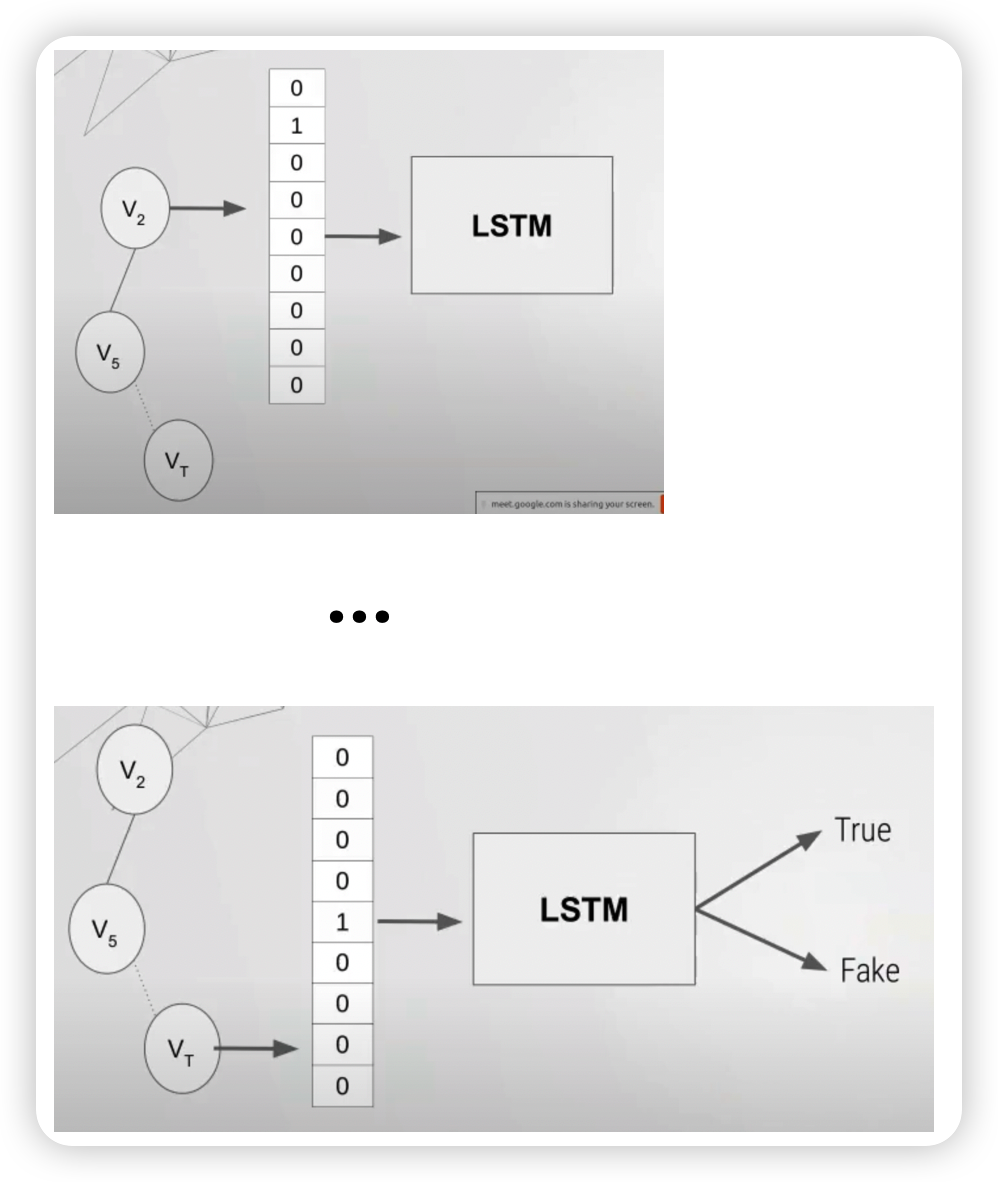
Stopping Criterion ( EO Criterion )
real sample 데이터와, fake sample 데이터의 edge가 overlap되는 순간, sequence generation은 stop하게 된다!
How to build a graph
위의 방식으로, Generator와 Discriminator가 잘 학습되었다고 해보자.
그렇다면, graph는 어떠한 방식으로 generate 되는가?
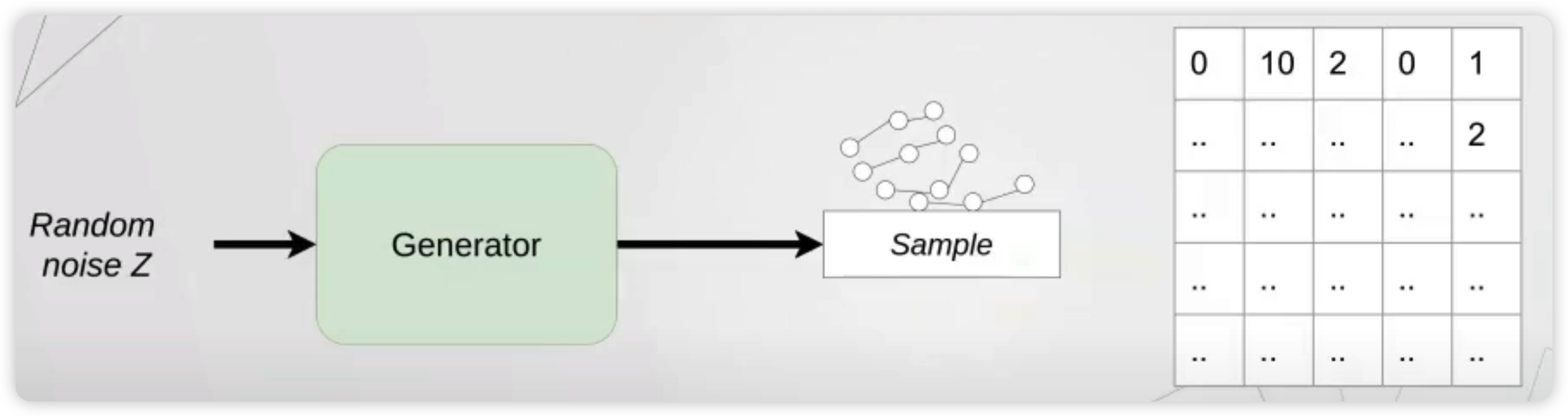

위 그림과 같이, 학습된 generator를 사용하여 많은 random walk들을 생성한다.
그러면, 우리는 이 walk들을 바탕으로, score adjacency matrix에 값을 채워나갈 수 있다.
이 matrix는, 최대값을 기준으로 symmetrize를 해주고, 모든 노드가 최소 하나 이상의 엣지를 가지도록 보장받게 한다.
이 값들을 전부 normalize한 뒤, edge에 대한 sampling probability로써 취급을 함으로써, graph를 generate하게 된다.