
MLOps : ML의 지속적 배포 & 자동화 파이프라인
https://cloud.google.com/architecture/mlops-continuous-delivery-and-automation-pipelines-in-machine-learning 를 정리한 포스트
Contents
-
MLOps의 필요성
- Introduction
- DevOps vs MLOps
- ML을 위한 데이터 과학의 단계
- MLOps 수준 0 : 수동 프로세스
- MLOps 수준 1 : ML 파이프라인 자동화
- MLOps 수준 2 : CI/CD 파이프라인 자동화
0. MLOps의 필요성
아래의 사진 한장으로 끝!
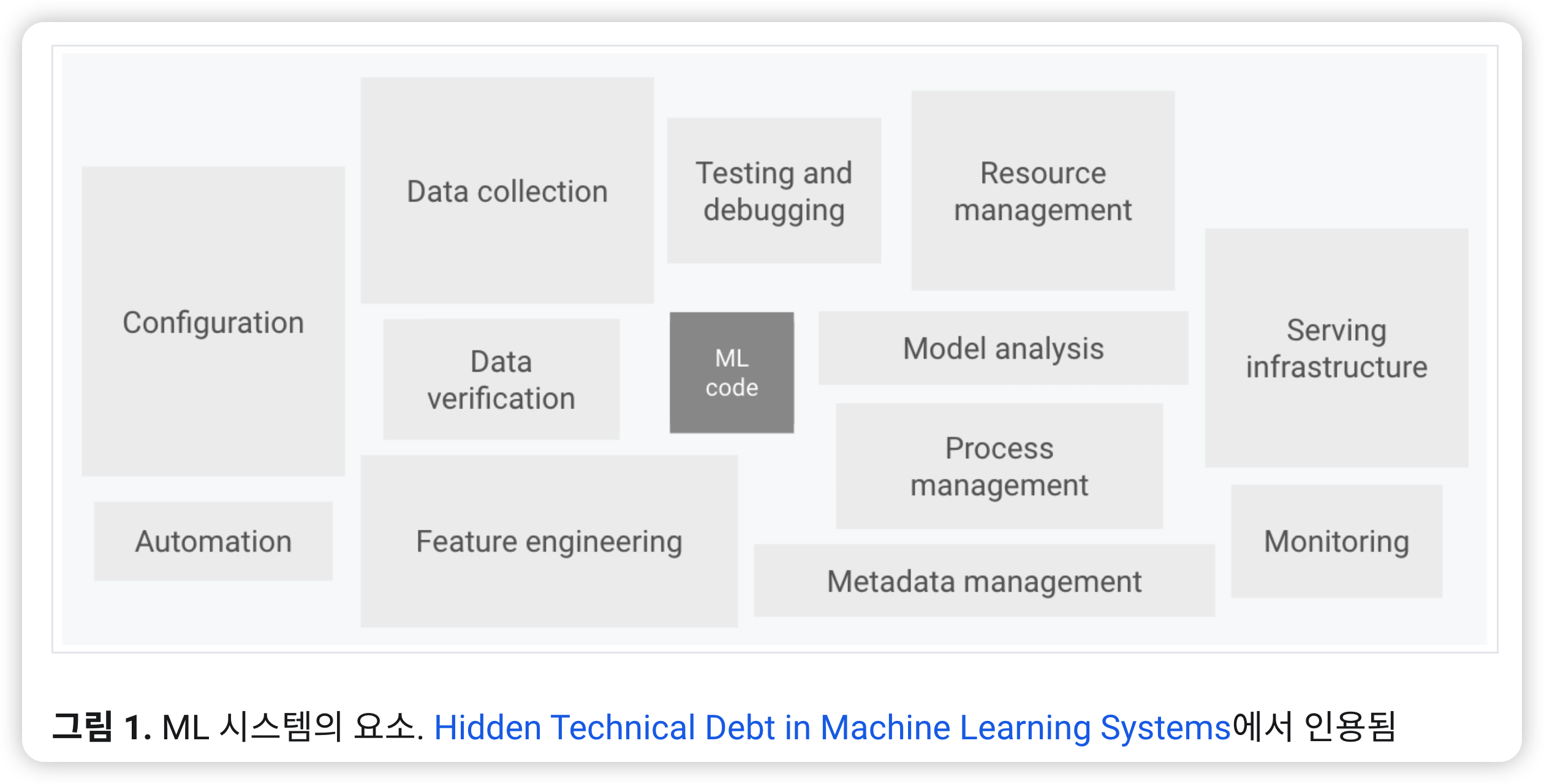
1. Introduction
좋은 ML 시스템을 위해, 아래의 3가지를 구현해야!
- (1) CI (Continuous Integration, 지속적 통합)
- (2) CD (Continuous Deployment, 지속적 배포)
- (3) CT (Continuous Training, 지속적 학습)
이 셋을 자동화하는 기술이 필요하다!
ML 사용 목적 : 현실의 문제를 잘 해결하기 위해!
그러기 위해, 필요한 ML의 요소들 :
- (1) 대규모 데이터셋
- (2) 저렴한 컴퓨팅 리소스
- (3) ML을 위한 전문 가속기
- (4) ML 연구의 발전
MLOps = (a) + (b)
- (a) ML 시스템 개발 ( = Dev/ML )
- (b) ML 시스템 운영 ( = Ops )
통합, 테스트, 출시, 배포, 인프라 관리 등 모든 단계의 자동화/모니터링을 지원!
2. MLOps vs DevOps
(1) DevOps
- 대규모 소프트웨어 시스템을 개발하기 위해!
- 개발 + 운영을 통합한 개념
- 장점
- 개발 주기 단축
- 배포 속도 증가
- 안정적인 출시
- 이를 위해 필요한 2가지 개념 :
- (1) CI (Continuous Integration, 지속적 통합)
- (2) CD (Continuous Deployment, 지속적 배포)
(2) MLOps
기존의 DevOps에, 아래와 같은 차이점들이 있음
[ 차이점 1 ] 팀 기술
- EDA / 모델 개발 / 실험을 수행할 data scientists 필요
[ 차이점 2 ] 개발
- ML에는 많은 실험이 들어감 ( 피쳐, 모델링, 하이퍼파라마터 튜닝 등 )
- 때문에, 수행한 실험에 대한 추적 중요 & 코드 재사용성/재현성 중시
[ 차이점 3 ] 테스트
-
(DevOps에서의) 일반적인 단위/통합 테스트 외에도,
데이터 검증, 모델 품질 평가, 모델 검증 등의 테스트도 추가적으로 필요함!
[ 차이점 4 ] 배포
- 간단하지 않다!
- 오프라인으로 학습된 ML 모델을 예측 서비스로 배포하고 끝나는게 아니다!
- 새롭게 들어오는 데이터를 가지고, 자동으로 모델을 재학습할 수 있어야
[ 차이점 5 ] 프로덕션
-
최적화의 문제만으로 모델이 decay되는 것은 아니다.
진화하는 데이터 프로필로 인해서 성능이 저하될 수도!
-
따라서, 모델의 온라인 성능을 지속적으로 모니터링하여 관리할 수 있어야!
(3) MLOps의 CI / CD / CT
- CI ( 지속적 통합 )
- (DevOps) 코드 및 구송요소 테스트 & 검증
- (MLOps) = (DevOps) + 데이터, 데이터 스키마, 모델의 검증 & 테스트
- CD ( 지속적 배포 )
- (DevOps) 소프트웨어 패키지/서비스 배포
- (MLOps) = (DevOps) + 모델 예측 서비스를 자동으로 배포하는 ML학습 파이프라인
- CT ( 지속적 학습 )
- (MLOps) 모델을 자동으로 재학습
3. ML을 위한 데이터 과학의 단계
ML 프로젝트의 단계
- 데이터 추출
- 데이터 분석 ( EDA )
- 데이터 준비 ( 데이터 정리, 변환 및 분할 )
- 모델 학습
- 모델 평가 ( K-fold CV )
- 모델 검증
- 모델 제공
- 모델 모니터링
ML process의 성숙도 = 위의 8단계의 자동화 정도
(0) 자동화 X ~ (1) CI/CD 파이프라인 모두 자동화
4. MLOps 수준 0 : 수동 프로세스
(1) 목표
-
MLOps 수준 0 = 기본 수준
-
”ML 모델 빌드 & 배포”는 수동으로
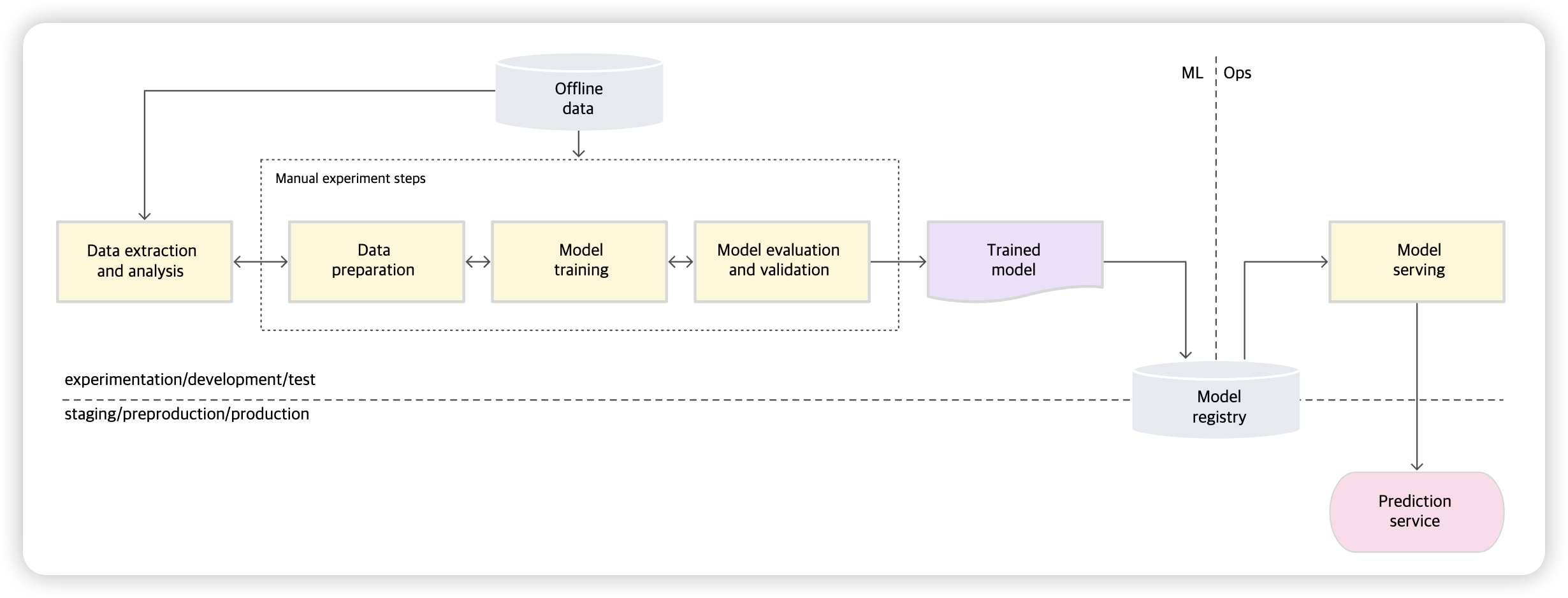
(2) 세부적 특징
-
수동, 스크립트 기반, 양방향 프로세스
- 데이터 분석, 데이터 준비, 모델 학습, 모델 검증 = 전부 수동
-
ML & 작업의 분리
-
데이터 과학자 & 엔지니어의 분리
- 데이터 과학자 : 모델을 개발
- 엔지니어 : 예측서비스로 제공
-
데이터 과학자는, 엔지니어에게 학습된 모델을 아티백트로 전달하여 API인프라에 배포
-
엔지니어는, 이를 전달받은 뒤, 프로덕션 단계에서 사용될 수 있도록 해줘야
-> 이 과정에서 학습 제공 편항이 발생
- 모델 학습 & 모델 서빙 단계에서의 성능 차이
-
-
간헐적인 출시 반복
-
자주 변경되지 않는 모델을 관리
( 1년에 2,3번 정도 모델 버전 변경 )
-
-
CI가 없다
- 구현 변경 사항이 거의 없으므로!
-
CD가 없다
- 모델 버전이 자주 변경되지 않으므로!
-
배포 = 예측 서비스
- 전체 ML시스템이라고 할게 딱히 없음.
- 그냥, 예측 서비스로 학습된 모델을 배포하는 것!
-
활성 성능 모티러닝 부족
- 모델 버전을 자주 변경하지 않으므로, data/concept drift 크게 고려 X
(3) 도전 과제
문제점 : 환경/데이터의 변화에 빠르게 적응 X
프로덕션 단계에서, 모델의 정확성을 잘 유지하기 위해선…
- (1) 모델 품질 모니터링
- 모니터링을 통한 성능 저하를 파악해야!
- 새로운 데이터에 대한 새로운 실험/재학습의 단서
- (2) 프로덕션 모델 자주 재학습
- 새로운패턴 포착 시, 새 데이터로 재학습해야
- (3) 새로운 구현을 지속절으로 실험
- 새로운 특성 / 모델 아키텍처 / 하이퍼파라미터 등으로 새로운 구현 시도!
\(\rightarrow\) CI/CD 및 CT용 MLOps 방식
5. MLOps 수준 1 : ML 파이프라인 자동화
(1) 목표
-
“ML 파이프라인 자동화”하여 모델을 지속적으로 재학습
-
새 데이터에 맞는 재학습하는 과정을 자동화
- (1) 파이프라인 트리거 및 메타데이터 관리
- (2) 자동화된 데이터 & 모델 검증 단계
가 필요하다!
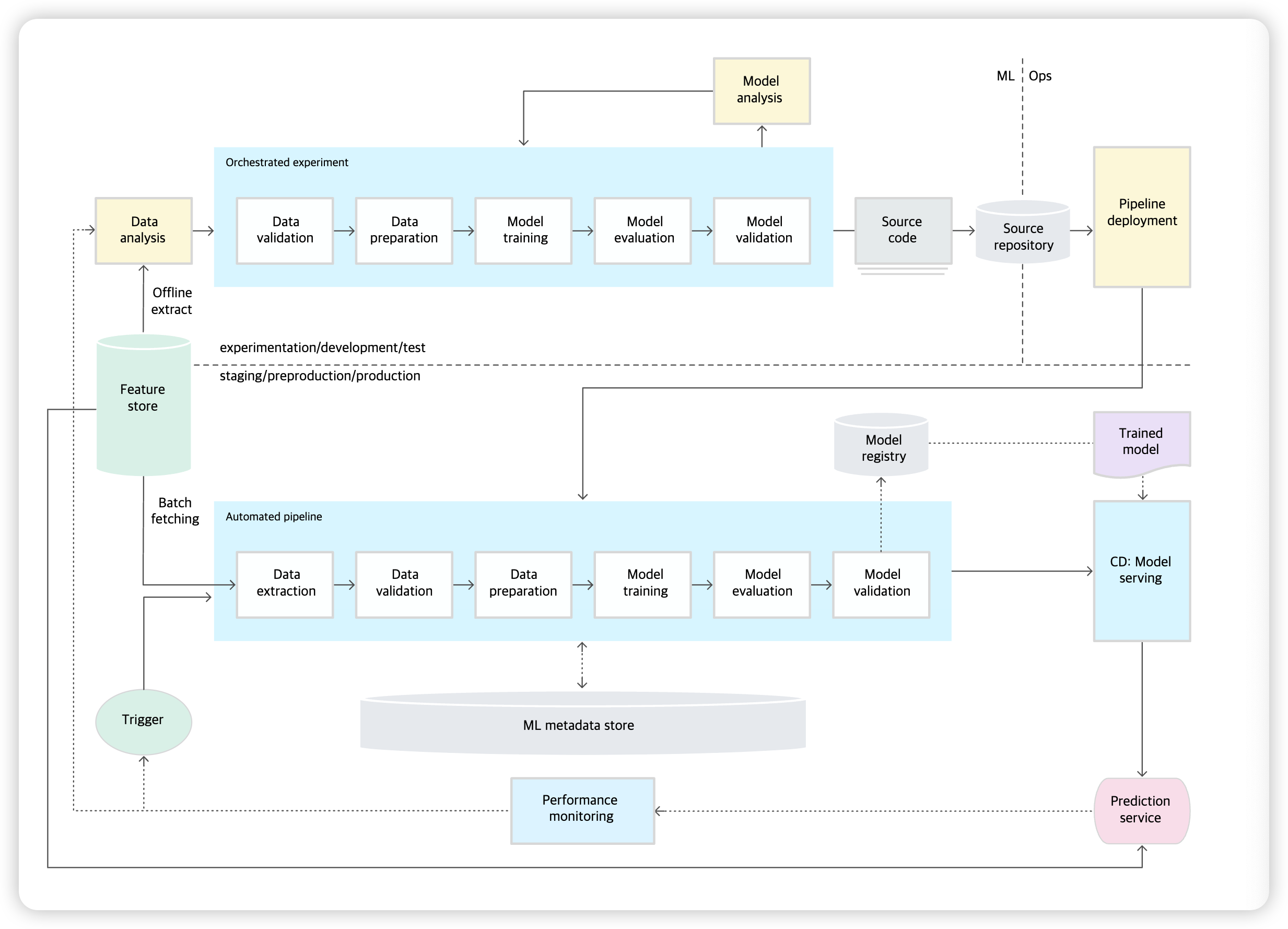
(2) 세부적 특징
-
빠른 실험
- 실험을 빠르게 반복 & 프로덕션 단계로 빠르게 이동
-
프로덕션 단계에서 모델의 CT
- 실시간 파이프라인 트리거를 기반으로,
- 새로운 데이터를 사용하여,
- 모델이 프로덕션단계에서 자동으로 재학습
-
실험-운영 균형
-
“개발/실험 환경”에서 사용하는 파이프라인은,
“프로덕션 환경”에서도 사용됨.
-
-
모듈화된 코드
- ML 파이프라인 구성할 때, 구성 요소를 재사용/공유할 수 있어야!
- 따라서..
- (1) 소스코드를 모듈화 해야!
- (2) 구성요소를 컨테이너화 해야!
-
모델의 지속적 배포
- 새 데이터로 학습된 새 모델을, 예측서비스에 지속적으로 배포해야
- 이 과정을 자동화 할 수 있어야!
-
파이프라인 배포
- (수준0) ”학습된 모델“”을, 프로덕션에서 예측 서비스로 배포
- (수준1) “자동으로 반복 실행되는 전체 학습 파이프라인“을 배포합니다.
- 프로덕션 단계에서 CT가 이루어지므로!
(3) 추가 구성 요소
ML의 CT를 위한 구성요소
a) 데이터 & 모델 유효성 검사
ML 파이프라인 트리거로 인해, 파이프라인이 실행됨
- 새 데이터 / 새 모델 버전으로 재학습이 이루어질것.
프로덕션 파이프라인은, 아래의 자동화된 “데이터 검증 & 모델 검증”이 필요!
-
데이터 검증
- 모델을 재학습할지, 파이프라인 실행을 중지할지 결정하는데에 필요
- 2가지 경우
- 데이터 스키마 편항
- 의미 : 입력 데이터의 이상 ( ex. 더 이상 xx 칼럼 확보 불가! )
- 결론 : 파이프라인 중지
- 데이터 값 편향
- 의미 : 편향으로 인해, 데이터의 통계적 속성에 변화 ( 패턴이 변화 )
- 결론 : 모델 재학습
- 데이터 스키마 편항
-
모델 검증
-
( = 오프라인 모델 검증 )
- 새 데이터를 바탕으로 모델을 “재학습 한 이후” 수행 ( 모델을 프로덕션으로 옮기기 전에 )
- 검증하는 사항들 :
- 현재 모델보다 나은지!
- 데이터의 다양한 세그멘트에서 일관성 있는지
- 새로 배포된 모델은, 예측을 제공하기 이전에 카나리 배포, A/B테스트 등에서 온라인 모델 검증을 거침
-
b) 특성 저장소
- pass
c) 메타 데이터 관리
- ML파이프라인의 각 실행에 대한 정보
- 재현성, 비교, 오류 디버깅 등을 위해 필요!
- 기록하는 메타 데이터 종류들 :
- 실행된 파이프라인 구성요소 & 버전
- 날짜 & 수행 시간 정보
- 파이프라인 실행자
- 파이프라인 매개변수
- 파이프라인의 각 단계에서 생성된 아티팩트에 대한 포인터
- 학습/테스트 데이터셋에 대한 모델 평가 측정 항목
d) ML 파이프라인 트리거
새로운 데이터로 새로운 모델 재학습 case
- (1) 요청 시 ( 임시 수동 실행 )
- (2) 일정 기준
- (3) 새 학습 데이터의 가용성 기준
- (4) 모델 성능 저하 시
- (5) 데이터 분포의 변화 시 ( concept drift )
(4) 도전 과제
-
파이프라인 자체의 새로운 구현이 자주 배포되진 않음 ( 몇 개의 파이프라인만 관리 )
-
파이프라인 & 구성요소를 수동으로 test ( + 새로운 파이프라인 배포도 수동으로! )
-
BUT, 새로운 아이디어 시도해야하는 경우 + 프로덕션 단계에서 많은 ML 파이프라인을 관리하는 경우?
\(\rightarrow\) ML 파이프라인의 빌드 / 테스트 / 배포를 자동화하기 위한 CI/CD설정 필요!
6. MLOps 수준 2 : CI/CD 파이프라인 자동화
(1) 목표
프로덕션 단계에서 파이프라인을 빠르고 안정적으로 업데이트하기 위해!
\(\rightarrow\) 자동화된 CI/CD 시스템 필요
- 새 파이프 라인을 자동으로 빌드 / 테스트 / 배포
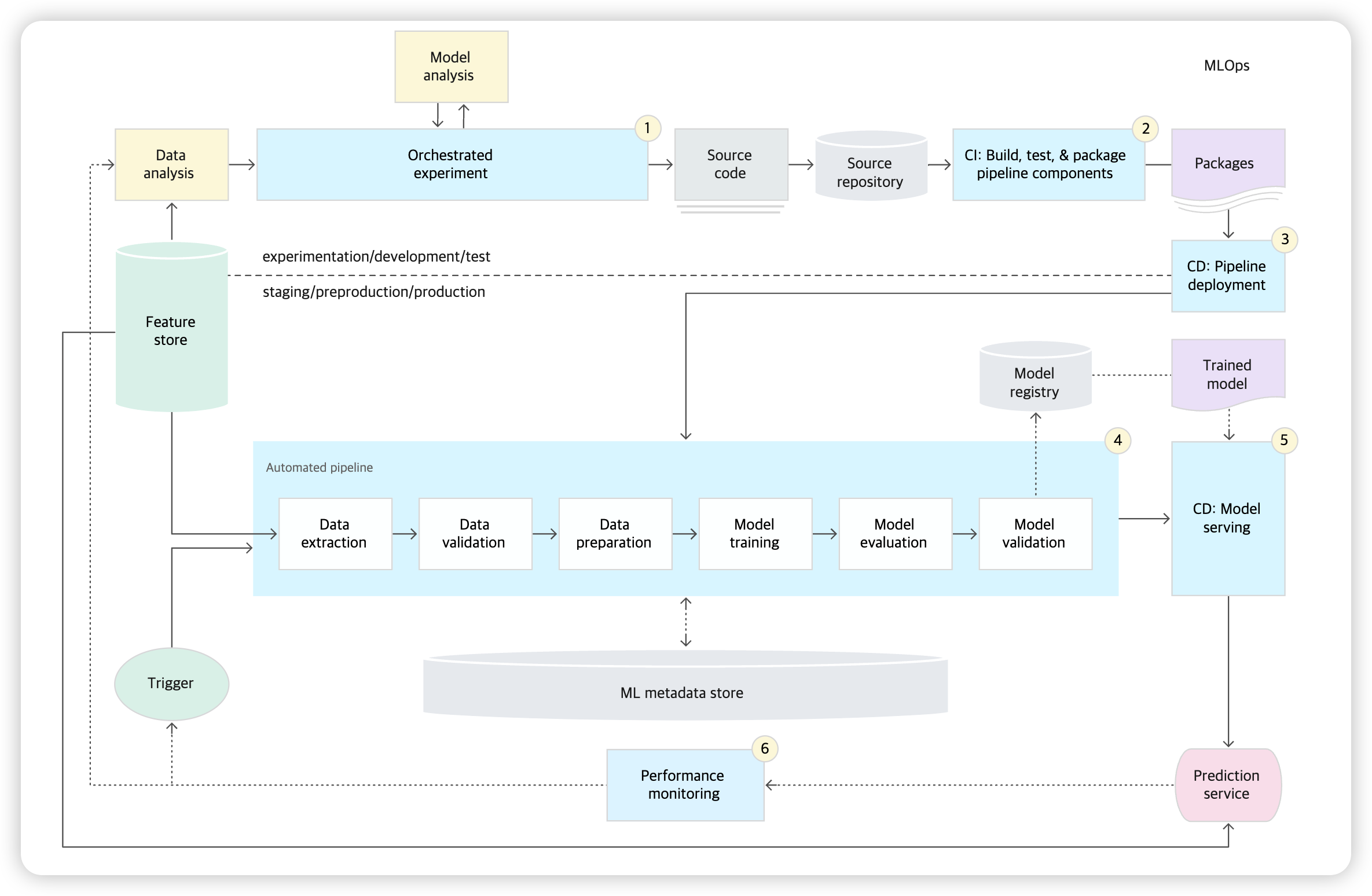
(2) MLOps 구성요소
- 소스 제어
- 서비스 테스트 & 빌드
- 배포 서비스
- 모델 레지스트리
- 특성 저장소
- ML 메타데이터 저장소
- ML 파이프라인 조정자
(3) CI / CD 자동화 파이프라인 단계
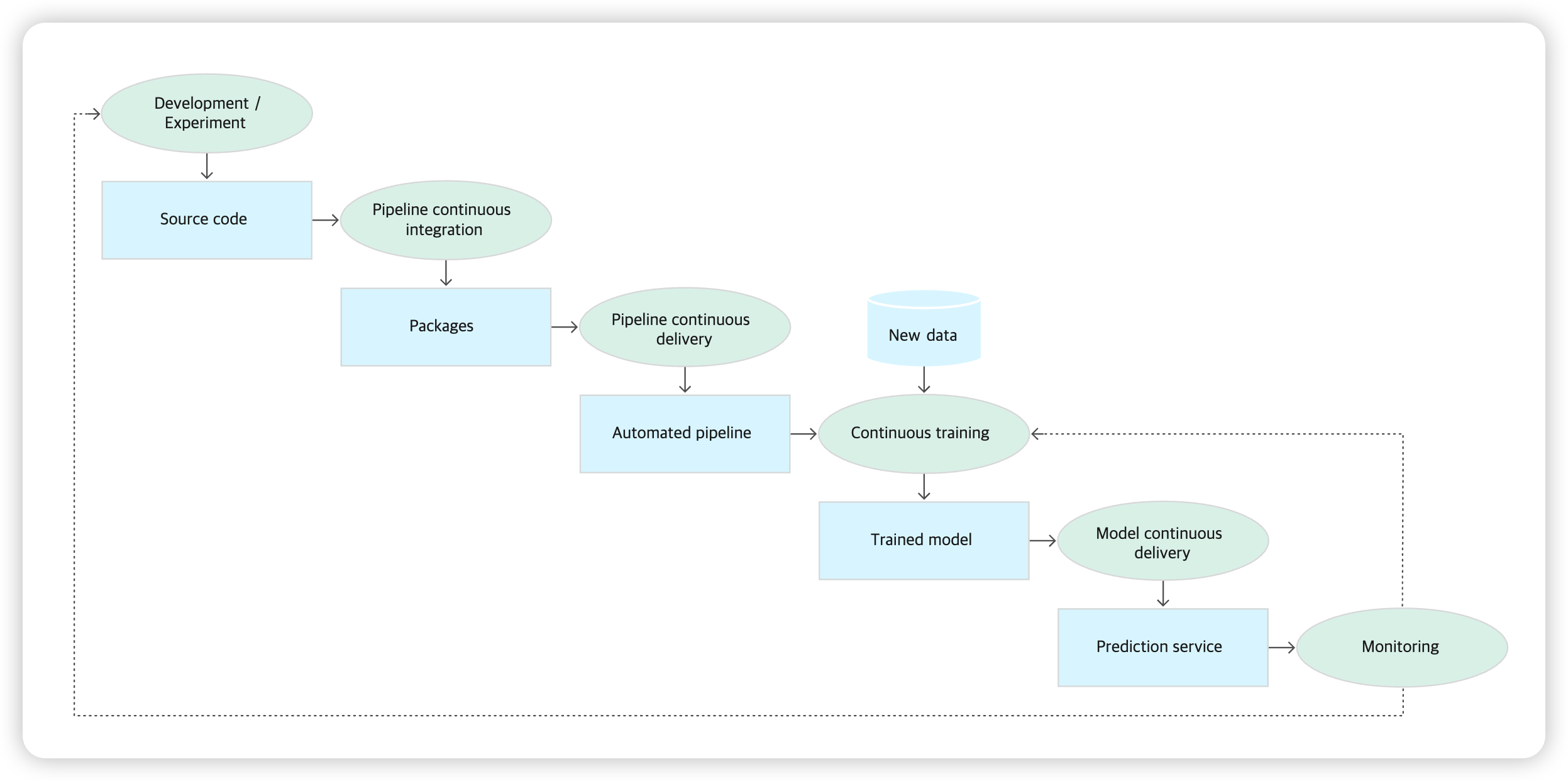
-
(Step 1) 개발 및 실험
-
새로운 모델링 반복적으로 시도
-
output : ML 파이프라인 단계의 소스 코드
( 소스 저장소로 push됨 )
-
-
(Step 2) 파이프라인 CI
- 위에서 짠 소스 코드를 빌드 & 다양한 테스트
- output : 파이프라인의 구성요소 (패키지, 실행 파일, 아티팩트)
-
(Step 3) 파이프라인 CD
- 위에서 생성된 아티팩트를 대상 환경에 배포
- output : 배포된 파이프라인
-
(Step 4) 자동화된 트리거
- 위에서 짠 파이프라인은, 특정 트리거에 따라 프로덕션 단계에서 자동으로 실행됨
- output : 학습된 모델 ( 모델 레지스트리로 push됨 )
-
(Step 5) 모델 CD
- 위에서 학습한 모델을 예측 서비스로 제공
- output : 배포된 모델 예측 서비스
-
(Step 6) 모니터링
- 실시간 데이터 기반으로, 모델의 성능 통계 수집
- output : 트리거 ( 파이프라인 실행 or 새 실험주기 실행 )
(4) CI ( 지속적 통합 )
파이프라인과 구성요소가 자동으로 빌드 / 테스트 / 패키징
- 새 코드가 commit 될 때마다
- 소스 코드 저장소로 push 될때마다
위의 경우에 자동으로 빌드하는 것 외에도, 아래의 테스트들을 포함
- (1) 특성 추출 로직을 단위 테스트
- (2) 모델에 구현된 다양한 메서드를 단위 테스트
- (3) 모델 학습이 수렴하는지
- (4) NaN값이 나오지는 않는지
- (5) 파이프라인의 각 구성요소가, 예상했던 아티팩트를 잘 생성하는지
- (6) 파이프라인의 구성 요소간의 통합을 테스트
(5) CD ( 지속적 배포 )
파이프라인 및 모델을 빠르고 안정적인 지속적 배포
그러기 위해…
- 모델 & 인프라의 호환성 확인
- Ex) 필요한 것이 잘 설치되어있는지, 성능 확인 등
- 예측 서비스 테스트
- 예측 서비스 성능 테스트 ( 서비스 부하 테스트 등 )
- 데이터 유효성 검사
- 배포 이전, 예측 성능 목표 충족하는지
프로덕션 환경에서 ML을 구현한다고 해서 모델이 예측용 API로 배포되는 것은 아님!
- “자동화 할 수 있는 ML 파이프라인”의 배포를 의미함