
( reference : Introduction to Machine Learning in Production )
Define Data and Establish Baseline
[1] Why is data definition hard?
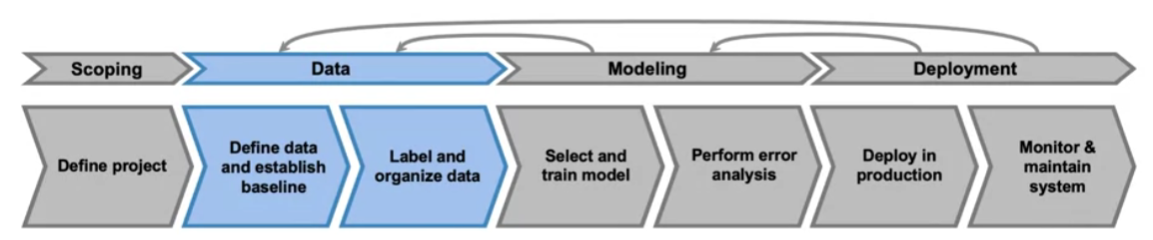
how to define data
- what is \(X\) & \(Y\)?
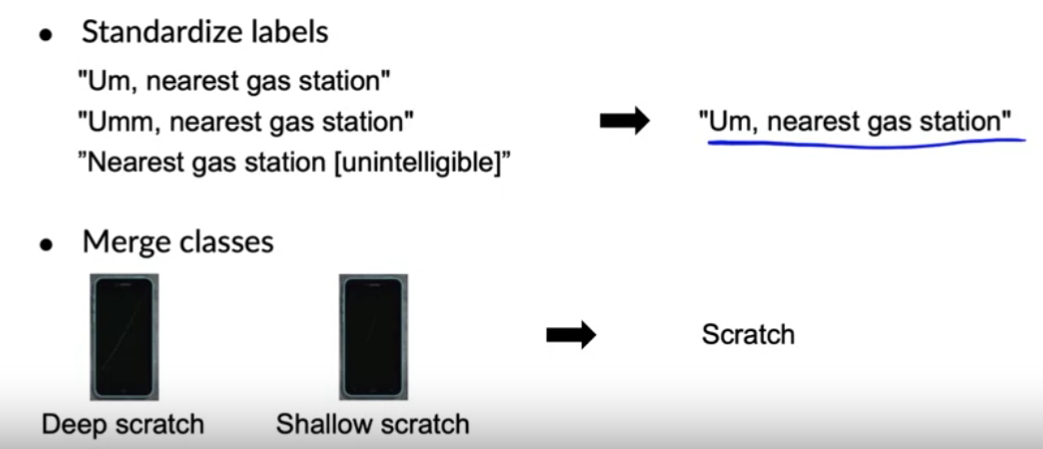
Labels may be “inconsistent”
ex) Image Detection


ex) Speech Recognition

\(\rightarrow\) standardize on “one convention”!!
[2] Major types of data problems
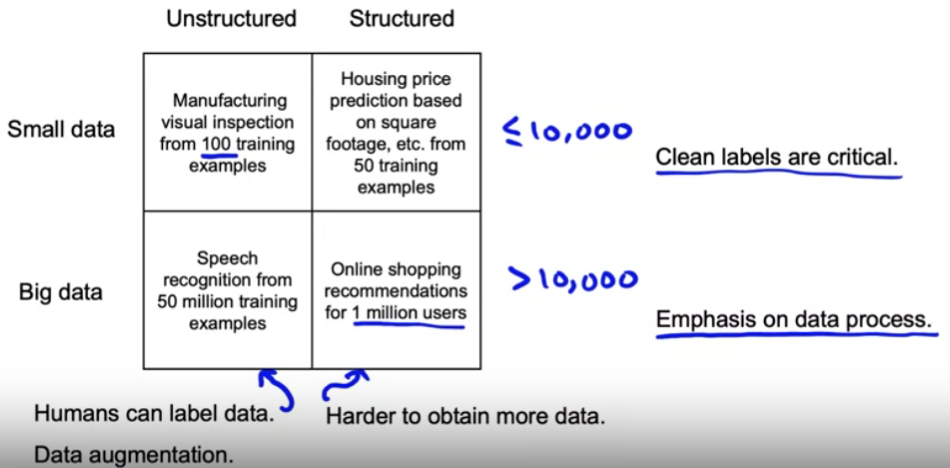
(axis 1) structured vs unstructured
Unstructured data problems
- can get people’s help to label data ( or data augmentation )
Structured data problems,
- harder to obtain more data & data augmentation
Best practices for unstructured & structured data are different!
(axis 2) large vs small dataset
Large & Small dataset
- no precise definition
- set arbitrary threshold, 10000
Small dataset
- “having clean labels is critical”
Huge dataset
- by difficulty of going through every example, “data process” is more important!
- ex) how you collect / install the data / the labeling instructions … be impossible for
When working on 1 out of those 4 quadrants…
- advice from same quadrant will be much more helpful!
[3] Small data and label consistency
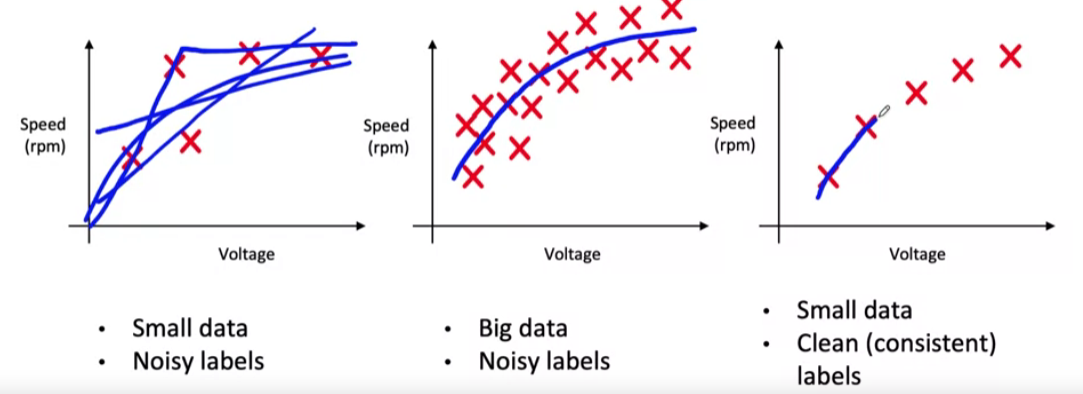
5 examples on the right most
- have clean & consistent labels
- can more confidently fit a function! ( compared to left most )
ex) Phone defect
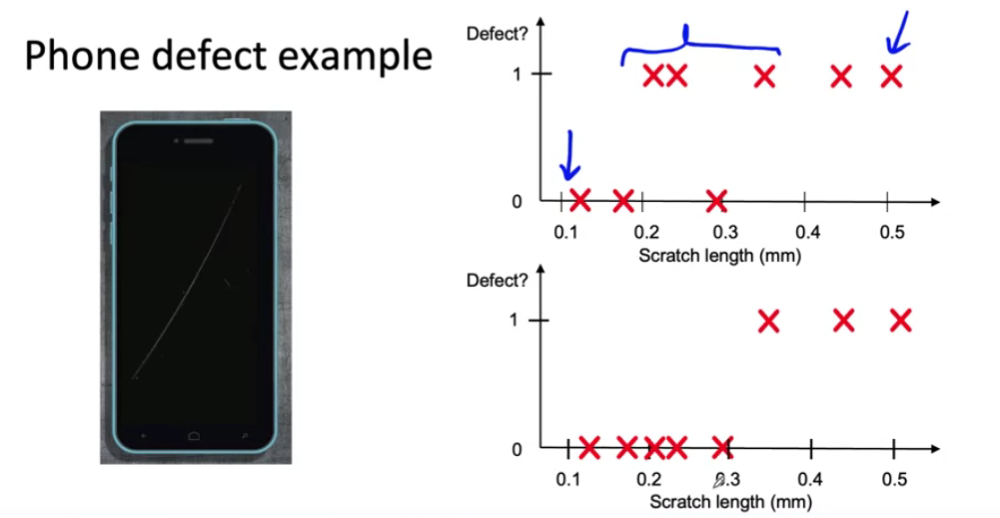
people might have different criterion for “scratch”
\(\rightarrow\) make the labelers can agree with “length of 0.3”
Big data problems can have small data challenges too!
-
case : “long tail of rare events”
-
ex 1) web search
-
large web search engine companies all have very large data sets of web search queries,
but many most companies do not!
-
-
ex 2) self-driving cars
- rare accident data
-
ex 3) product recommendation
- lot of products were sold very few
[4] Improving label consistency
How to improve “label consistency” ?
- 1) multiple labelers with same example
- 2) have discussion about definition of \(y\) , when disagreement happens
- 3) if labelers believe \(x\) doesn’t contain enough information, consider changing \(x\)
- 4) iterate until it is hard to significantly increase agreement
Example
Another option
add an another class label to capture “uncertainty”
- ex) defect detection : “borderline”
- ex) speech recognition : “[unintelligible]”

Small & Big data
Small data
- small number of labelers \(\rightarrow\) discuss with themselves
Big data
- define labelers as “groups”
- send labeling “instructions” to them
- + can have “multiple labelers” for same example
[5] Human Level Performance (HLP)
Why do we need HLP?
- to estimate bayes error / irreducible error
- thus, get help from error analysis, and decide where to “focus on”
Other uses of HLP
- 1) respectable benchmark
- 2) reasonable target
- 3) prove ML > humans
- but, use this with “CAUTION”!
beating HLP \(\neq\) proof of ML superiority
\(\rightarrow\) due to biased advantage!
example )

[6] Raising HLP
2 cases : HLP are
- case 1) externally defined ( REAL ground truth )
- case 2) just defined by another human
case 1) externally defined
- HLP gives an estimate of “Bayes error / Irreducible error”
case 2) by another human
- compare “HLP”( = person 1) & “another person”( = person 2 )
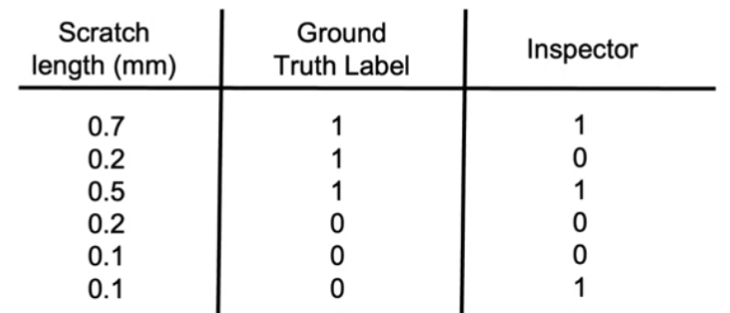
Summary
-
if \(y\) comes from human ( = case 2 ),
HLP « 100% means “ambiguous labeling instructions”
-
improve label consistency \(\rightarrow\) raise HLP
-
makes ML harder to beat HLP
-
But, “more consistent labels” makes ML give better performance
\(\rightarrow\) benefit the actual application performance
-
HLP on structured data
- HLP is less used in structured data
- exception :
- ex) User ID merging : are those 2 people indicating the same person?
- ex) is it a spam account?