
( reference : Introduction to Machine Learning in Production )
Label and Organize Data
[1] Obtaining data
How much to spend obtaining data?

-
get this iteration loop as quickly as possible
-
question
- (X) how long to take \(m\) examples?
- (O) how much data can we get in \(m\) days?
( exception : when we know in advance how much data we need! )
Inventory data
brainstorm list of data sources
( + size of data & cost/time to collect )

How to label data?
3 options
- 1) in-house
- 2) out-sourcing
- 3) crowd-source
Who labels? ( qualification )
- ex) speech recognition : fluent speaker
- ex) factory inspection, medical image diagnosis : SME (subject matter expert)
- ex) recommender system : (maybe impossible)
Tips
- do not increase data more than “10 times at a time”
- do it gradually & check model performance!
[2] Data pipeline
Data pipelines ( = Data Cascades )
- multiple steps of processing before getting to the final output.
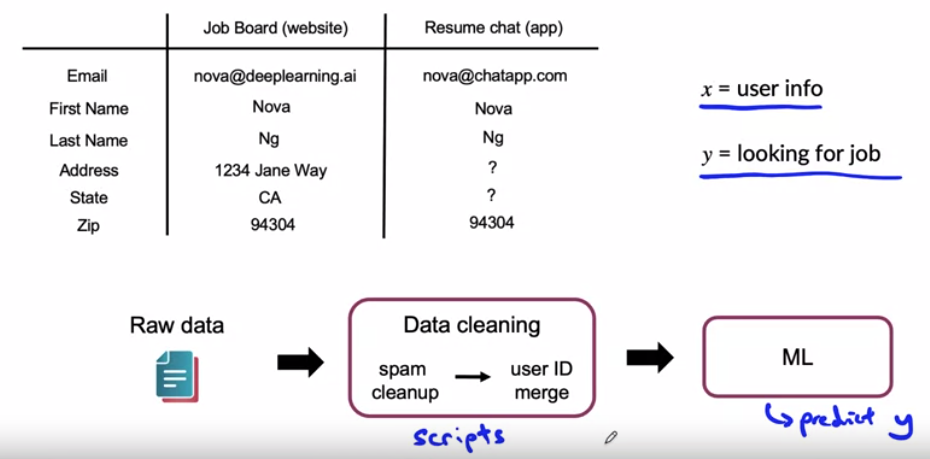
Example)
- data : user information
- model goal : predict if a given user is looking for a job
- business goal : surface job ads
Given raw data, need pre-processing (cleaning) before feeding into algorithm
-
by using script
-
ex) spam cleanup, user ID merge, ….
-
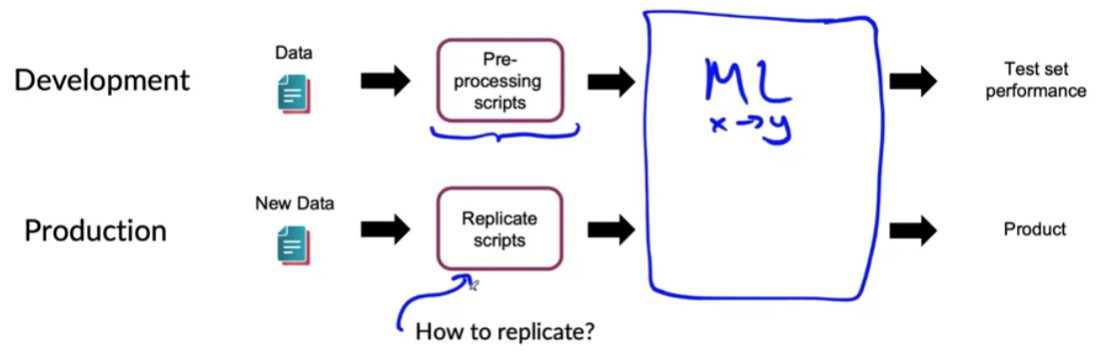
make sure the pre-processing scripts are highly replicable
( distribution of 2 datasets should be similar )
POC & Production phases
POC (Proof-of-Concept)
-
goal : decide if the application is worth deploying
-
focus on getting the “prototype”
-
OK if pre-processing is manual
( just take notes/comments )
Production phases
-
after project utility is established, use more sophisticated tools to make sure that
the “data pipeline is replicable”
-
ex) Tensorflow transform, Apache Beam, Airflow..
[3] Meta-data, data provenance and lineage
Data pipeline example
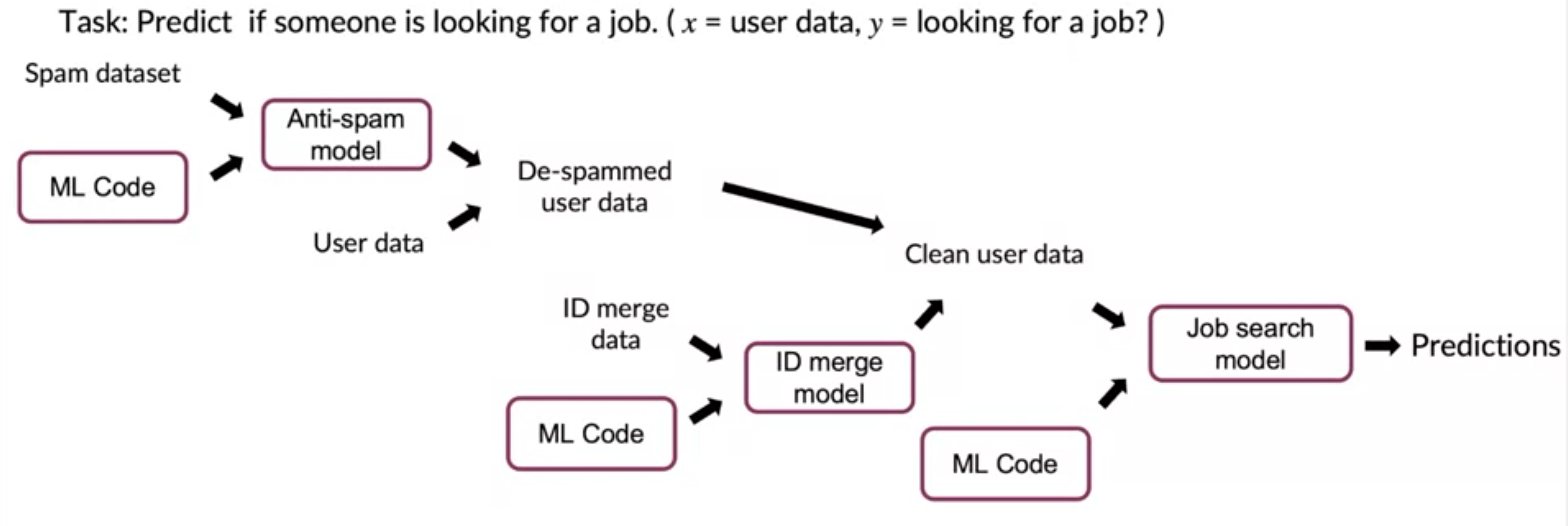
What if error is detected in “Spam dataset”…!?
\(\rightarrow\) it will affect all the process!
\(\rightarrow\) thus, need to keep track of data provenance & lineage
- data provenance : where the data “comes from”
- data lineage : “sequence of steps”
Meta-data
meta-data = “data of data”
usefulness
- 1) error analysis ( spotting unexpected effects )
- 2) keeping track of data provenance
[4] Balanced train/dev/test splits
stratified split!
ex) 100 examples & 30 are positive ( 30% )
-
train/dev/test (60%/20%/20%) = 60/20/20
-
positive samples inside train/dev/test = also (60%/20%/20%)
\(\rightarrow\) 18/6/6