A Hybrid Approach for Aspect-Based Sentiment Analysis Using Deep Contextual Word Embeddings and Hierarchical Attention (2020)
Contents
- Abstract
- Introduction
- Related Works
- Method
- Ontology-based Rules
- Multi-Hop LCR-Rot NN Design
- Word Embeddings
- Multi-Hop LCR-Rot with Hierarchical Attention
0. Abstract
HAABSA (Hybrid Approach for ABSA)를 2가지 측면에서 improve 시킴
- 1) non-contextual 임베딩 \(\rightarrow\) CONTEXTUAL 임베딩
- 2) Hierarchical Attention 을 추가함 ( by adding attention layer )
1. Introduction
ABSA의 main task들
- 1) target extraction (TE)
- target 카테고리 자체를 찾기
- 2) aspect detection (AD)
- target 카테고리와 관련 있는 여러 aspect들 찾기
- 3) target sentiment classification (SC)
- 이 논문에서 집중하는 것은 이거!
2. Related Works
ABSA의 main task들은 크게 2가지 방법으로 풀 수있음
- 1) knowledge-based methods
- POS 태깅, lexicon 사용해서!
- 2) ML methods
\(\rightarrow\) 이 둘은 상호보완적이다!
Hybrid Models : 위의 두 method들의 장점을 취한다!
Hybrid Models
- 방법 1) 둘을 하나의 모델로 integrate
- 방법 2) 둘을 순차적으로 적용
3. Method
HAABSA : hybrid approach for aspect-based sentiment classification
2개의 step으로 이루어진다.
-
1) Target Polarities를 예측하기
-
domain sentiment ontology를 사용해서
-
rule-based method
-
-
2) 미완성 부분은 NN으로 마저 채우기
3-1) Ontology-based Rules
3 그룹의 Hierarchical structure
- 1) Sentiment value class
- Positive/Negative subclass
- 2) Aspect Mention class
- aspects related to sentiment expressions
- 3) Sentiment Mention class
- sentiment expression
문제점
- (1) 두 개의 충돌하는 감정이 존재 시
- (2) 해당 aspect 관련 단어 부재 시 (?)
\(\rightarrow\) NN을 통해 backup이 필요한 이유
3-2) Multi-Hop LCR-Rot NN Design
세 종류의 대표적 모델
- 1) LSTM-ATT
- 2) LCR-Rot
- LSTM-ATT를 사용
- Left-Center-Right separated NN + Rotary Attention
- 3) Multi-Hop LCR-Rot
- LCR-Rot + repeated attention
이 논문은, Multi-Hop LCR-Rot에 2가지를 더함
- (1) 다른 word embedding 방법 ( context를 반영하게끔! )
- (2) Hierarchical attention
Multi-Hop LCR-Rot
-
문장을 3 파트로 나눔 ( Left / Target / Right )
-
이 3 파트 각각 bi-LSTMs에 feed
( 즉, 2 step Rotary Attention 적용 )
-
bi-LSTMs의 결과로 나온 hidden states :
- left : \(\left[h_{1}^{l}, \ldots, h_{L}^{l}\right]\)
- target : \(\left[h_{1}^{t}, \ldots, h_{T}^{t}\right]\)
- right : \(\left[h_{1}^{r}, \ldots, h_{R}^{r}\right]\)
Multi-Hop LCR-Rot 작동 원리
[ Step 1 ] “new context” representation 생성하기 ( with target information )
-
[step 1-1] attention function \(f\) 구하기
-
ex) left context
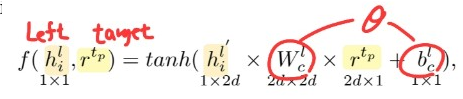
-
-
[step 1-2] attention normalized score \(\alpha\) 구하기
- ex) left context : \(\alpha_{i}^{l}=\frac{\exp \left(f\left(h_{i}^{l}, r^{r_{p}}\right)\right)}{\sum_{j=1}^{L} \exp \left(f\left(h_{j}^{l}, r^{r_{p}}\right)\right)}\)
-
[step 1-3] context representation \(r\) 계산하기
- weighted by attention score
- ex) left target2context vector : \(\underset{2 d \times 1}{r}^{l}=\sum_{i=1}^{L} \underset{1 \times 1}{\alpha_{i}^{l}} \times \underset{2 d \times 1}{h_{i}^{l}}\).
[ Step 2 ] “target” representation 생성하기
- 위와유사하다
- 차이점 : \(r^{t_p}\) 대신, \(r^l\)와 \(r^r\)을 사용
- ex) left context2target \(r^{t_l}\) : \(\underset{2 d \times 1}{r^{t_{l}}}=\sum_{i=1}^{T} \alpha_{i \times 1}^{t_{l}} \times \underset{2 d \times 1}{h_{i}^{t}}\)
지금 위에서 한 [Step 1] & [Step 2]는, LEFT를 예시로 한 것!
이와 마찬가지고 RIGHT에 대해서도 target2context & context2target 계산하기
3-3) Word Embeddings
Non-contextual Word Embeddings
- GloVe
- Word2vec
Contextual Word Embeddings
- ELMo
- BERT
- final representation of word \(i\) : by summing the word embeddings of the last 4 layers
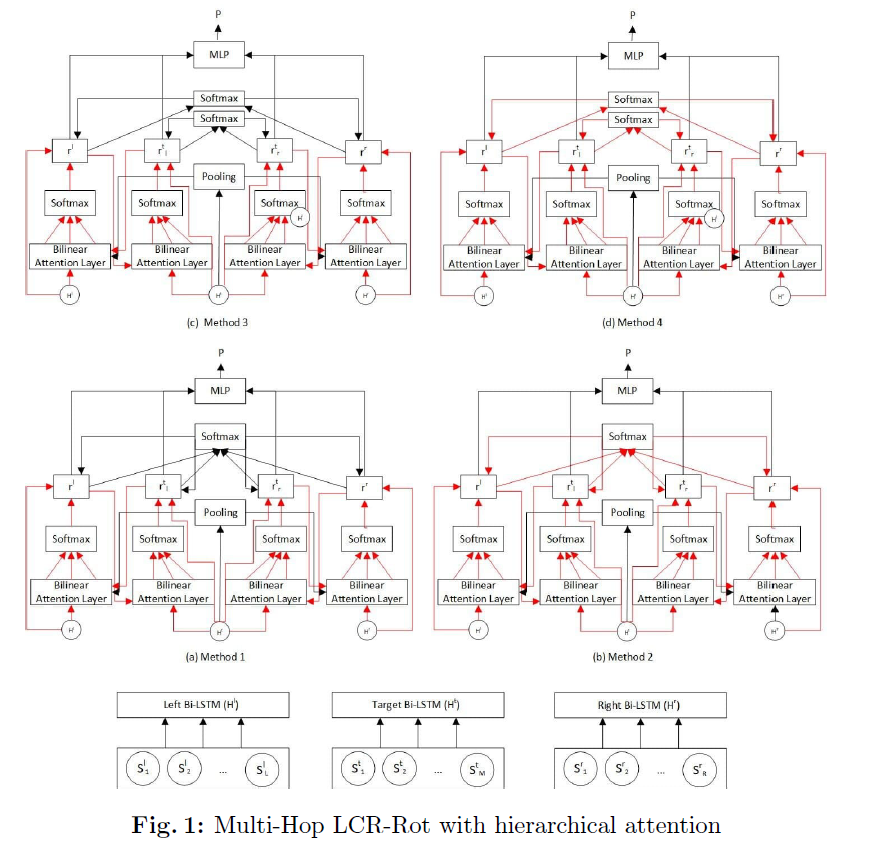
3-4) Multi-Hop LCR-Rot with Hierarchical Attention
지금까지 위에서 설명한 Multi-Hop LCR-Rot의 문제점?
\(\rightarrow\) 생성한 4개의 vector ( LEFT/RIGHT x target2context/context2target )는 오직 local information 밖에 사용 안한다!
\(\rightarrow\) Hierarchical Attention을 통해 위 문제 완화하기!
[Step 1] \(f\left(v^{i}\right)=\tanh \left(\underset{1 \times 1}{v^{i}} \times \underset{1 \times 2 d}{\times W}+\underset{2 d \times 1}{b}\right)\).
[Step 2] \(\alpha^{i}=\frac{\exp \left(f\left(v^{i}\right)\right.}{\sum_{j=1}^{4} \exp \left(f\left(v^{j}\right)\right)}\).
[Step 3] \(\underset{2 d \times 1}{v^{i}}=\underset{1 \times 1}{\alpha^{i}} \times \underset{2 d \times 1}{v^{i}},\)
Hierarchical Attention을 Multi-Hop LCR-Rot 아키텍쳐에 적용하는 4가지 method :