
HIBERT : Document Level Pre-training of Hierarchical Bidirectional Transformers for Document Summarization (2019)
Contents
- Abstract
- Introduction
- Model
- Document Representation
- Pre-training
- Extractive Summarization
0. Abstract
Neural Extractive Summarization method
-
document 인코딩을 위해, 주로 hierarchical encoder를 사용
-
지도학습 방법 (label 존재)
-
위의 label도 결국 rule-based method로 만들어진 것을 사용
\(\rightarrow\) 따라서 inaccurate labels
-
이 문제점을 극복하고자, 최근 핫한 pre-trained model인 BERT를 사용한 HIBERT를 제안한다!
- key 1) Document encoding
- key 2) Pre-train using unlabeled data
1. Introduction
Automatic Document Summarization ( = 자동으로 문단 요약 )
크게 2가지의 방법론
-
**1) extractive **: 원 document에서 일부를 “발췌” ( 즉, “그대로” 사용 )….. sentence ranking problem
-
2) abstractive : 새로운 단어/어절을 “생성” ( 즉, “새롭게 만들어” 사용 )…. seq2seq
( 하지만, 문법적으로 맞는지 / 원 document와 같은 내용을 담는지 확인할 길이 X )
\(\rightarrow\) Extractive model이 더 reliable한 것으로 보인다!
BUT… extractive models는 sentence label을 필요로 한다
( 주로 rule-based method로 얻어진 label )
\(\rightarrow\) 따라서 inaccurate label & overfitting 위험
Proposal
위의 문제점을 해결하기 위한 HIBERT를 제안
-
step 1) Pre-train the “complex part” ( i.e Hierarchical Encoder ) of extractive model, on UNlabeled data
-
step 2) ( 위에서 학습한 pre-train model로 initialize해서 ) learn to classify sentence
2. Model
2-1) Document Representation
Notation
- document : \(\mathcal{D}=\left(S_{1}, S_{2}, \ldots, S_{ \mid \mathcal{D} \mid }\right)\)
- sentence in \(\mathcal{D}\) : \(S_{i}=\left(w_{1}^{i}, w_{2}^{i}, \ldots, w_{ \mid S_{i} \mid }^{i}\right)\)
- \(w_{ \mid S_{i} \mid }^{i}\) : EOS (End Of Sentence)
\(\mathcal{D}\) 를 얻기 위해, 2가지의 encoder를 사용
( 둘 다 Transformer의 encoder 사용 )
- 1) sentence encoder
- 2) document encoder
\(\rightarrow\) 이 둘은 hierarchical하게 nested 되어 있다.
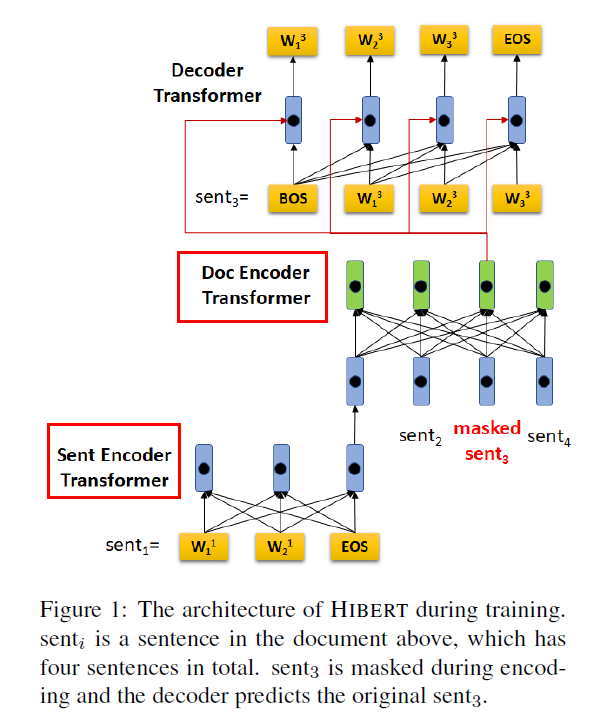
Step 1. sentence \(S_{i}\)의 representation을 얻기
-
(step 1-1) \(\mathbf{E}_{i}\)로 mapping
\(\mathbf{E}_{i}=\left(\mathbf{e}_{1}^{i}, \mathbf{e}_{2}^{i}, \ldots, \mathbf{e}_{ \mid S_{i} \mid }^{i}\right)\), where \(\mathbf{e}_{j}^{i}=e\left(w_{j}^{i}\right)+\mathbf{p}_{j}\)
- \(e\left(w_{j}^{i}\right)\) & \(\mathbf{p}_{j}\) : word & positional embedding
-
(step 1-2) \(\mathbf{E}_{i}\)를 encoding
sentence encoder를 사용하여, \(\mathbf{E}_{i}\)를 \(\left(\mathbf{h}_{1}^{i}, \mathbf{h}_{2}^{i}, \ldots, \mathbf{h}_{ \mid S_{i} \mid }^{i}\right) .\)로 encoding
-
(step 1-3) representation of \(S_i\)
마지막 token인 \(\mathbf{h}_{ \mid S_{i} \mid }^{i}\) 를 \(S_i\)의 representation으로 사용
-
(step 1-4) final representation of \(S_i\)
\(\hat{\mathbf{h}}_{i}=\mathbf{h}_{ \mid S_{i} \mid }^{i}+\mathbf{p}_{i}\).
Step 2. obtain “context sensitive” sentence representation
- 앞서 구한 \(\hat{\mathbf{h}}_{i}=\mathbf{h}_{ \mid S_{i} \mid }^{i}+\mathbf{p}_{i}\)를 사용
- \(\left(\hat{\mathbf{h}}_{1}, \hat{\mathbf{h}}_{2}, \ldots, \hat{\mathbf{h}}_{ \mid \mathcal{D} \mid }\right)\) \(\rightarrow\)\(\left(\mathbf{d}_{1}, \mathbf{d}_{2}, \ldots, \mathbf{d}_{ \mid \mathcal{D} \mid }\right) .\)
한 document 내에 있는 여러 개의 sentence들을 embedding하는데에 성공!
요약 : document representation을 구하는데에 있어서 ( with hierarchical models)
- (구) RNN, CNN
- (HIBERT) Transformer의 encoder
2-2) Pre-training
대부분의 최근 모델들은 pre-train된 모델을 사용한다
- ex) ELMo, GPT, BERT…
위의 모든 모델들은 전부 기본 unit이 “word”이다. 하지만 HIBERT의 기본 unit은 “sentence”이다.
따라서, DOCUMENT-level model를 pre-train하는 것은, 곧 “단어가 아니라 문장”을 예측하는 것!
(a) Document Masking
-
Masking X : 85%
Masking O : 15%
- masking O : 80%
- 그대로 사용 : 10%
- random sentence : 10%
(b) Sentence Prediction
(a) Document masking으로 인해, 다음의 masked document를 얻음
- masking 이전 : \(\mathcal{D}=\left(S_{1}, S_{2}, \ldots, S_{ \mid \mathcal{D} \mid }\right)\).
- masking 이후 : \(\widetilde{\mathcal{D}}=\left(\tilde{S}_{1}, \tilde{S}_{2}, \ldots, S_{ \mid \mathcal{D} \mid }\right)\)
\(\mathcal{K}\) : selected sentences in \(\mathcal{D}\) (의 indicies)
결국, 예측하고자 하는 masked sentence들은 \(\mathcal{M}=\left\{S_{k} \mid k \in \mathcal{K}\right\}\)이다.
알고리즘 순서
- 1) masking해서 \(\tilde{\mathcal{D}}\)를 얻어낸다
- 2) \(\tilde{\mathcal{D}}\)를 HIBERT encoder 사용해서 sentence representation \(\left(\tilde{\mathbf{d}}_{1}, \tilde{\mathbf{d}}_{2}, \ldots, \mathbf{d}_{ \mid \mathcal{D} \mid }\right)\)를 얻는다
- 3) 이 \(\tilde{\mathbf{d}_k}\)와 \(w_0^k,...,w_{j-1}^k\)를 사용하여 \(w_j^k\)를 예측한다
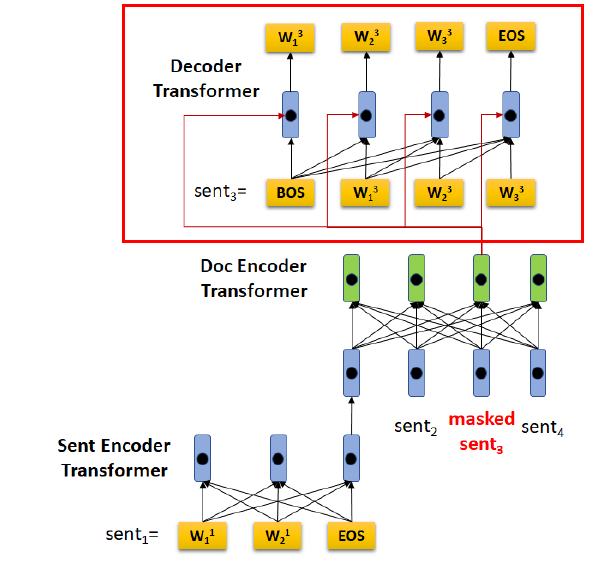
2-3) Extractive Summarization
Summarization = sequence labeling 문제
- Summary에 속할 문장일 경우 TRUE, 아닐 경우 FALSE
Notation
- 특정 document: \(\mathcal{D}=\left(S_{1}, S_{2}, \ldots, S_{ \mid \mathcal{D} \mid }\right)\).
- 해당 document의 sentence label : \(Y=\left(y_{1}, y_{2}, \ldots, y_{ \mid \mathcal{D} \mid }\right)\).
특정 sentence \(S_i\)가 summary에 최종적으로 속하게 될 확률을 모델링하면…
- \(p\left(y_{i} \mid \mathcal{D}\right)=\operatorname{softmax}\left(\mathbf{W}^{S} \mathbf{d}_{i}\right)\).