
[code review] Informer
import torch
import torch.nn as nn
import torch.nn.functional as F
1. MODEL
(1) InformerStack
enc_in: encoder의 input dimensiondec_in: decoder의 input dimensionc_out: number of channel outputlabel_len: length of label outputout_len: 예측하고자 하는 (time)구간의 길이d_model: embedding할 dimensiond_ff: Encoder layer / Decoder layer에 있는 첫 번째 Conv1d의 output dimensione_layers: 1개의 encoder에 쌓을 encoder layer의 개수- ex) [3,2,1] :
- 1번째 encoder에는 : encoder layer 3개
- 2번째 encoder에는 : encoder layer 2개
- 3번째 encoder에는 : encoder layer 1개
- ex) [3,2,1] :
d_layers: 1개의 decoder에 쌓을 decoder layer의 개수- Attention 관련 hyper 파라미터들
factor:n_heads: Attention head의 개수
dropout: dropout rateattn: ( ‘prob’ 일 경우, ProbSparse attention 사용 )embed: temporal embedding 시- 1)
FixedEmbedding할 지 - 2)
nn.Embedding할 지
- 1)
freq: time feature embedding 시의 frequencyactivation: activation functionoutput_attention: attention score들을 반환할 지distil: distillation 할 지 말지
class InformerStack(nn.Module):
def __init__(self, enc_in, dec_in, c_out, label_len, out_len,
factor=5, d_model=512, n_heads=8, e_layers=[3,2,1], d_layers=2, d_ff=512,
dropout=0.0, attn='prob', embed='fixed', freq='h', activation='gelu',
output_attention = False, distil=True, mix=True,
device=torch.device('cuda:0')):
super(InformerStack, self).__init__()
#------------------------------------------------------#
self.pred_len = out_len
self.attn = attn
self.output_attention = output_attention
#------------------------------------------------------#
# (1) "Data Embedding" layer
self.enc_embedding = DataEmbedding(enc_in, d_model, embed, freq, dropout)
self.dec_embedding = DataEmbedding(dec_in, d_model, embed, freq, dropout)
#------------------------------------------------------#
# (2) Attention
Attn = ProbAttention if attn=='prob' else FullAttention
#------------------------------------------------------#
# (3) Encoder
## 구성 1) + 2) + 3)이 총 e_layer 길이 만큼
###### 구성 1) Encoder Layer x el개
###### 구성 2) Convolutional Layer (distill 경우 선택)
###### 구성 3) Layer Normalization
inp_lens = list(range(len(e_layers))) # [0,1,2,...] you can customize here
encoders = [
Encoder(
## a) Encoder Layer
[EncoderLayer(
AttentionLayer(Attn(False, factor, attention_dropout=dropout,
output_attention=output_attention),
d_model, n_heads, mix=False),
d_model,d_ff,dropout=dropout,
activation=activation) for l in range(el)],
## b) Convolutional Layer
[ ConvLayer(d_model) for l in range(el-1) ] if distil else None,
## c) Layer Normalization
norm_layer=torch.nn.LayerNorm(d_model)
) for el in e_layers]
self.encoder = EncoderStack(encoders, inp_lens)
#------------------------------------------------------#
# (4) Decoder
## 구성 1) + 2)
###### 구성 1) Decoder Layer x d_layer개
###### 구성 2) Layer Normalization
self.decoder = Decoder(
## a) Decoder Layer
[DecoderLayer(
AttentionLayer(Attn(True, factor, attention_dropout=dropout,
output_attention=False),d_model, n_heads, mix=mix),
AttentionLayer(FullAttention(False, factor,attention_dropout=dropout,
output_attention=False),d_model, n_heads, mix=False),
d_model,d_ff,dropout=dropout,activation=activation,
) for l in range(d_layers)],
## b) Layer Normalization
norm_layer=torch.nn.LayerNorm(d_model))
#------------------------------------------------------#
# self.end_conv1 = nn.Conv1d(in_channels=label_len+out_len, out_channels=out_len, kernel_size=1, bias=True)
# self.end_conv2 = nn.Conv1d(in_channels=d_model, out_channels=c_out, kernel_size=1, bias=True)
#------------------------------------------------------#
# (5) Projection Layer
self.projection = nn.Linear(d_model, c_out, bias=True)
def forward(self, x_enc, x_mark_enc, x_dec, x_mark_dec,
enc_self_mask=None, dec_self_mask=None, dec_enc_mask=None):
# Step 1) Embedding (encoder)
enc_out = self.enc_embedding(x_enc, x_mark_enc)
# Step 2) Encoding
enc_out, attns = self.encoder(enc_out, attn_mask=enc_self_mask)
# Step 3) Embedding (decoder)
dec_out = self.dec_embedding(x_dec, x_mark_dec)
# Step 4) Decoding
dec_out = self.decoder(dec_out, enc_out, x_mask=dec_self_mask, cross_mask=dec_enc_mask)
# Step 5) Linear Pojection
dec_out = self.projection(dec_out)
# dec_out = self.end_conv1(dec_out)
# dec_out = self.end_conv2(dec_out.transpose(2,1)).transpose(1,2)
if self.output_attention:
return dec_out[:,-self.pred_len:,:], attns
else:
return dec_out[:,-self.pred_len:,:] # [B, L, D]
(2) Informer
class Informer(nn.Module):
def __init__(self, enc_in, dec_in, c_out, label_len, out_len,
factor=5, d_model=512, n_heads=8, e_layers=3, d_layers=2, d_ff=512,
dropout=0.0, attn='prob', embed='fixed', freq='h', activation='gelu',
output_attention = False, distil=True, mix=True,
device=torch.device('cuda:0')):
super(Informer, self).__init__()
#------------------------------------------------------#
self.pred_len = out_len
self.attn = attn
self.output_attention = output_attention
#------------------------------------------------------#
# (1) "Data Embedding" layer
self.enc_embedding = DataEmbedding(enc_in, d_model, embed, freq, dropout)
self.dec_embedding = DataEmbedding(dec_in, d_model, embed, freq, dropout)
#------------------------------------------------------#
# (2) Attention
Attn = ProbAttention if attn=='prob' else FullAttention
#------------------------------------------------------#
# (3) Encoder
## 구성 1) + 2) + 3)이 총 e_layer 길이 만큼
###### 구성 1) Encoder Layer x el개
###### 구성 2) Convolutional Layer (distill 경우 선택)
###### 구성 3) Layer Normalization
inp_lens = list(range(len(e_layers))) # [0,1,2,...] you can customize here
encoders = [
Encoder(
## a) Encoder Layer
[EncoderLayer(
AttentionLayer(Attn(False, factor, attention_dropout=dropout,
output_attention=output_attention),
d_model, n_heads, mix=False),
d_model,d_ff,dropout=dropout,
activation=activation) for l in range(el)],
## b) Convolutional Layer
[ ConvLayer(d_model) for l in range(el-1) ] if distil else None,
## c) Layer Normalization
norm_layer=torch.nn.LayerNorm(d_model)
) for el in e_layers]
self.encoder = EncoderStack(encoders, inp_lens)
#------------------------------------------------------#
# (4) Decoder
## 구성 1) + 2)
###### 구성 1) Decoder Layer x d_layer개
###### 구성 2) Layer Normalization
self.decoder = Decoder(
## a) Decoder Layer
[DecoderLayer(
AttentionLayer(Attn(True, factor, attention_dropout=dropout,
output_attention=False),d_model, n_heads, mix=mix),
AttentionLayer(FullAttention(False, factor,attention_dropout=dropout,
output_attention=False),d_model, n_heads, mix=False),
d_model,d_ff,dropout=dropout,activation=activation,
) for l in range(d_layers)],
## b) Layer Normalization
norm_layer=torch.nn.LayerNorm(d_model))
#------------------------------------------------------#
# self.end_conv1 = nn.Conv1d(in_channels=label_len+out_len, out_channels=out_len, kernel_size=1, bias=True)
# self.end_conv2 = nn.Conv1d(in_channels=d_model, out_channels=c_out, kernel_size=1, bias=True)
#------------------------------------------------------#
# (5) Projection Layer
self.projection = nn.Linear(d_model, c_out, bias=True)
def forward(self, x_enc, x_mark_enc, x_dec, x_mark_dec,
enc_self_mask=None, dec_self_mask=None, dec_enc_mask=None):
# Step 1) Embedding (encoder)
enc_out = self.enc_embedding(x_enc, x_mark_enc)
# Step 2) Encoding
enc_out, attns = self.encoder(enc_out, attn_mask=enc_self_mask)
# Step 3) Embedding (decoder)
dec_out = self.dec_embedding(x_dec, x_mark_dec)
# Step 4) Decoding
dec_out = self.decoder(dec_out, enc_out, x_mask=dec_self_mask, cross_mask=dec_enc_mask)
# Step 5) Linear Pojection
dec_out = self.projection(dec_out)
# dec_out = self.end_conv1(dec_out)
# dec_out = self.end_conv2(dec_out.transpose(2,1)).transpose(1,2)
if self.output_attention:
return dec_out[:,-self.pred_len:,:], attns
else:
return dec_out[:,-self.pred_len:,:] # [B, L, D]
2. ENCODER
EncoderStack
- Encoder
- Encoder Layer
- Conv Layer
(1) EncoderStack : encoder 모음
class EncoderStack(nn.Module):
def __init__(self, encoders, inp_lens):
super(EncoderStack, self).__init__()
self.encoders = nn.ModuleList(encoders) # Encoder의 모음
self.inp_lens = inp_lens # input의 길이들 ( 0,1,2,....)
def forward(self, x, attn_mask=None):
# 3차원의 X : [Batch, Length, Dimension]
x_stack = []
attns = []
for i_len, encoder in zip(self.inp_lens, self.encoders):
inp_len = x.shape[1]//(2**i_len)
x_s, attn = encoder(x[:, -inp_len:, :])
x_stack.append(x_s)
attns.append(attn)
x_stack = torch.cat(x_stack, -2)
return x_stack, attns
(2) Encoder
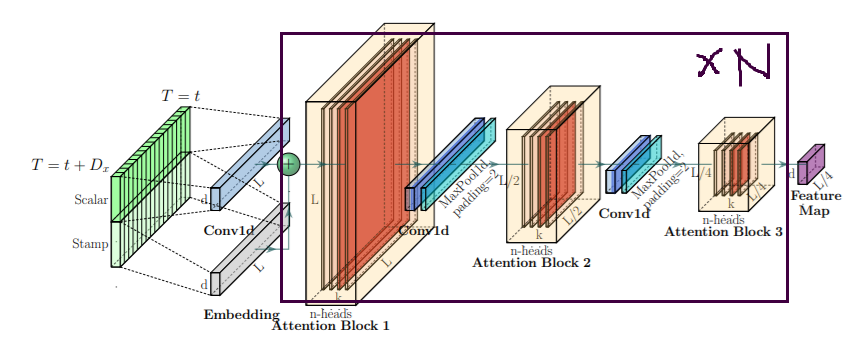
class Encoder(nn.Module):
def __init__(self, attn_layers, conv_layers=None, norm_layer=None):
super(Encoder, self).__init__()
self.attn_layers = nn.ModuleList(attn_layers)
self.conv_layers = nn.ModuleList(conv_layers) if conv_layers is not None else None
self.norm = norm_layer
def forward(self, x, attn_mask=None):
# 3차원의 X : [Batch, Length, Dimension]
attns = []
#-----------(1) Conv layer 사용하는 경우--------------#
if self.conv_layers is not None:
for attn_layer, conv_layer in zip(self.attn_layers, self.conv_layers):
x, attn = attn_layer(x, attn_mask=attn_mask)
x = conv_layer(x)
attns.append(attn)
x, attn = self.attn_layers[-1](x, attn_mask=attn_mask)
attns.append(attn)
#-----------(2) Conv layer 사용 안하는 경우--------------#
else:
for attn_layer in self.attn_layers:
x, attn = attn_layer(x, attn_mask=attn_mask)
attns.append(attn)
#-----------(3) Norm layer 사용하는 경우--------------#
if self.norm is not None:
x = self.norm(x)
return x, attns
(3) Encoder Layer
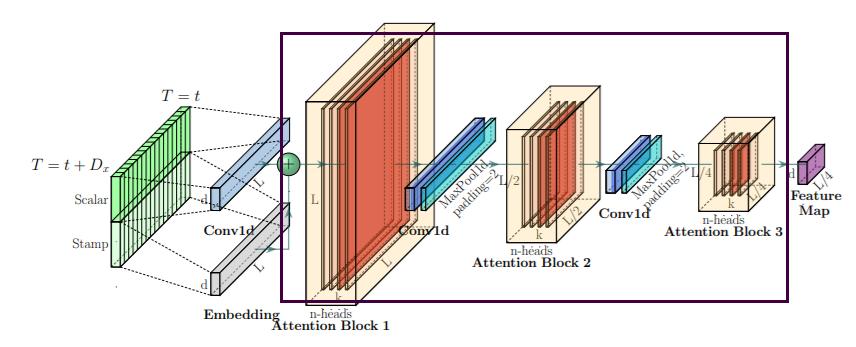
class EncoderLayer(nn.Module):
def __init__(self, attention, d_model, d_ff=None, dropout=0.1, activation="relu"):
super(EncoderLayer, self).__init__()
d_ff = d_ff or 4*d_model
self.attention = attention
self.conv1 = nn.Conv1d(in_channels=d_model, out_channels=d_ff, kernel_size=1)
self.conv2 = nn.Conv1d(in_channels=d_ff, out_channels=d_model, kernel_size=1)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
self.activation = F.relu if activation == "relu" else F.gelu
def forward(self, x, attn_mask=None):
# x = x + self.dropout(self.attention(
# x, x, x,
# attn_mask = attn_mask
# ))
#--------(1) Attention을 거치고 ------------#
new_x, attn = self.attention(
x, x, x,
attn_mask = attn_mask)
#--------(2) Residual Connection & Layer Normalization 1 ------------#
y = x = self.norm1(x + self.dropout(new_x))
#--------(3) Convolution layer x 2 통과 ------------#
y = self.dropout(self.activation(self.conv1(y.transpose(-1,1))))
y = self.dropout(self.conv2(y).transpose(-1,1))
#--------(4) Residual Connection & Layer Normalization 2 ------------#
y = self.norm2(x+y)
return self.norm2(x+y), attn
(4) Conv Layer
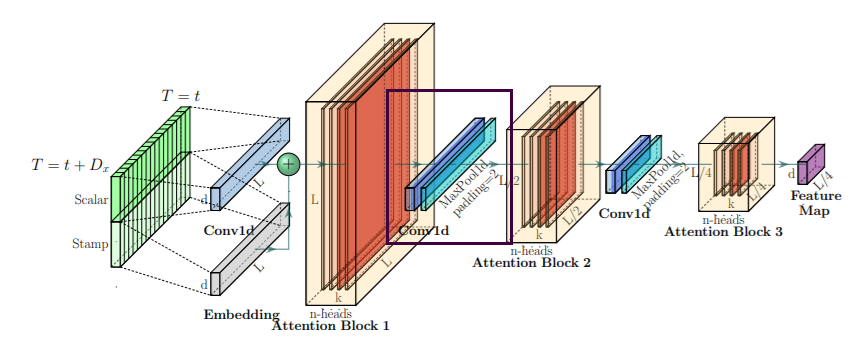
class ConvLayer(nn.Module):
def __init__(self, c_in):
super(ConvLayer, self).__init__()
padding = 1 if torch.__version__>='1.5.0' else 2
self.downConv = nn.Conv1d(in_channels=c_in,
out_channels=c_in,
kernel_size=3,
padding=padding,
padding_mode='circular')
self.norm = nn.BatchNorm1d(c_in)
self.activation = nn.ELU()
self.maxPool = nn.MaxPool1d(kernel_size=3, stride=2, padding=1)
def forward(self, x):
x = self.downConv(x.permute(0, 2, 1))
x = self.norm(x)
x = self.activation(x)
x = self.maxPool(x)
x = x.transpose(1,2)
return x
DECODER
(1) Decoder
class Decoder(nn.Module):
def __init__(self, layers, norm_layer=None):
super(Decoder, self).__init__()
self.layers = nn.ModuleList(layers)
self.norm = norm_layer
def forward(self, x, cross, x_mask=None, cross_mask=None):
for layer in self.layers:
x = layer(x, cross, x_mask=x_mask, cross_mask=cross_mask)
if self.norm is not None:
x = self.norm(x)
return x
(2) DecoderLayer
class DecoderLayer(nn.Module):
def __init__(self, self_attention, cross_attention, d_model, d_ff=None,
dropout=0.1, activation="relu"):
super(DecoderLayer, self).__init__()
d_ff = d_ff or 4*d_model
self.self_attention = self_attention
self.cross_attention = cross_attention
self.conv1 = nn.Conv1d(in_channels=d_model, out_channels=d_ff, kernel_size=1)
self.conv2 = nn.Conv1d(in_channels=d_ff, out_channels=d_model, kernel_size=1)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
self.activation = F.relu if activation == "relu" else F.gelu
def forward(self, x, cross, x_mask=None, cross_mask=None):
#----------(1) Self Attention -------------#
x = x + self.dropout(self.self_attention(
x, x, x,
attn_mask=x_mask
)[0])
x = self.norm1(x)
#----------(2) Cross Attention -------------#
x = x + self.dropout(self.cross_attention(
x, cross, cross,
attn_mask=cross_mask
)[0])
y = x = self.norm2(x)
#-----------(3) Convolutional Layer ----------#
y = self.dropout(self.activation(self.conv1(y.transpose(-1,1))))
y = self.dropout(self.conv2(y).transpose(-1,1))
y = self.norm3(x+y)
return y
4. EMBEDDING
Data Embedding
-
1) Positional Embedding
-
2) Token Embedding
-
3-1) Temporal Embedding
- Fixed Embedding 사용 O / X
-
3-2) Time Feature Embedding
( 3-1 or 3-2 중 선택 )
(1) Positional Embedding ( 학습 X )
positional encoding은 학습 대상 X
d_model: Positional embedding을 할 dimensionmax_len: 문장의 최대 길이
class PositionalEmbedding(nn.Module):
def __init__(self, d_model, max_len=5000):
super(PositionalEmbedding, self).__init__()
pe = torch.zeros(max_len, d_model).float()
pe.require_grad = False
position_term = torch.arange(0, max_len).float().unsqueeze(1)
divide_term = (torch.arange(0, d_model, 2).float() * -(math.log(10000.0) / d_model)).exp()
pe[:, 0::2] = torch.sin(position_term * divide_term)
pe[:, 1::2] = torch.cos(position_term * divide_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
return self.pe[:, :x.size(1)]
(2) Token Embedding ( 학습 O )
Token encoding은 학습 대상 O
( 1D convolution으로 임베딩한다 )
c_in- encoder의 경우 : encoder의 input dimension
- decoder의 경우 : decoder의 input dimension
d_model: Positional embedding을 할 dimension
class TokenEmbedding(nn.Module):
def __init__(self, c_in, d_model):
super(TokenEmbedding, self).__init__()
padding = 1 if torch.__version__>='1.5.0' else 2
self.tokenConv = nn.Conv1d(in_channels=c_in, out_channels=d_model,
kernel_size=3, padding=padding, padding_mode='circular')
for m in self.modules():
if isinstance(m, nn.Conv1d):
nn.init.kaiming_normal_(m.weight,mode='fan_in',nonlinearity='leaky_relu')
def forward(self, x):
x = self.tokenConv(x.permute(0, 2, 1)).transpose(1,2)
return x
(3) Fixed Embedding ( 학습 X )
-
“positional encoding”과 유사
-
embedding input dimension은
- minute_size
- hour_size
- ….
다양할 수 있음
class FixedEmbedding(nn.Module):
def __init__(self, c_in, d_model):
super(FixedEmbedding, self).__init__()
w = torch.zeros(c_in, d_model).float()
w.require_grad = False
position = torch.arange(0, c_in).float().unsqueeze(1)
div_term = (torch.arange(0, d_model, 2).float() * -(math.log(10000.0) / d_model)).exp()
w[:, 0::2] = torch.sin(position * div_term)
w[:, 1::2] = torch.cos(position * div_term)
self.emb = nn.Embedding(c_in, d_model)
self.emb.weight = nn.Parameter(w, requires_grad=False)
def forward(self, x):
return self.emb(x).detach()
(4) Temporal Embedding ( 학습 O/X )
- 월/일/요일/시/분을 각각 encoding한 이후, summation
- 임베딩 할 때..
- 1)
FixedEmbedding사용 시 : 학습 X - 2)
nn.Embedding사용 시 : 학습 O
- 1)
class TemporalEmbedding(nn.Module):
def __init__(self, d_model, embed_type='fixed', freq='h'):
super(TemporalEmbedding, self).__init__()
minute_size = 4
hour_size = 24
weekday_size = 7
day_size = 32
month_size = 13
Embed = FixedEmbedding if embed_type=='fixed' else nn.Embedding
if freq=='t':
self.minute_embed = Embed(minute_size, d_model)
self.hour_embed = Embed(hour_size, d_model)
self.weekday_embed = Embed(weekday_size, d_model)
self.day_embed = Embed(day_size, d_model)
self.month_embed = Embed(month_size, d_model)
def forward(self, x):
x = x.long()
x_minute = self.minute_embed(x[:,:,4]) if hasattr(self, 'minute_embed') else 0.
x_hour = self.hour_embed(x[:,:,3])
x_weekday = self.weekday_embed(x[:,:,2])
x_day = self.day_embed(x[:,:,1])
x_month = self.month_embed(x[:,:,0])
return x_hour + x_weekday + x_day + x_month + x_minute
(5) Time Feature Embedding ( 학습 O )
-
freq: Frequency for time features encoding(s : secondly, t : minutely, h : hourly, d : daily, b : business days, w : weekly, m : monthly)
class TimeFeatureEmbedding(nn.Module):
def __init__(self, d_model, embed_type='timeF', freq='h'):
super(TimeFeatureEmbedding, self).__init__()
freq_map = {'h':4, 't':5, 's':6, 'm':1, 'a':1, 'w':2, 'd':3, 'b':3}
d_inp = freq_map[freq]
self.embed = nn.Linear(d_inp, d_model)
def forward(self, x):
return self.embed(x)
(6) Data Embedding
- Token Embedding
- Positional Embedding
- Temporal Embedding ( or Time Feature Embedding)
위 세 요소를 summation하여 반환
class DataEmbedding(nn.Module):
def __init__(self, c_in, d_model, embed_type='fixed', freq='h', dropout=0.1):
super(DataEmbedding, self).__init__()
self.value_embedding = TokenEmbedding(c_in=c_in, d_model=d_model)
self.position_embedding = PositionalEmbedding(d_model=d_model)
self.temporal_embedding = TemporalEmbedding(d_model=d_model, embed_type=embed_type, freq=freq) if embed_type!='timeF' else TimeFeatureEmbedding(d_model=d_model, embed_type=embed_type, freq=freq)
self.dropout = nn.Dropout(p=dropout)
def forward(self, x, x_mark):
x = self.value_embedding(x) + self.position_embedding(x) + self.temporal_embedding(x_mark)
return self.dropout(x)
5. Attention
(일반적인) FullAttention과 PropAttention 중에 선택!
AttentionLayer
- 위에서 선택한 Attention을 사용하여 layer를 만든 것
(기타) Mask
torch.triu : upper triangle
a = torch.randn(3, 3)
torch.triu(a, diagonal=1)
--------------------------------------------
tensor([[ 0.0000, 0.5207, 2.0049],
[ 0.0000, 0.0000, 0.6602],
[ 0.0000, 0.0000, 0.0000]])
a) TriangularCausalMask
-
뒤에 cheating 방지를 위한 mask
-
torch.triu: upper trianglea = torch.randn(3, 3) torch.triu(a, diagonal=1) -------------------------------------------- tensor([[ 0.0000, 0.5207, 2.0049], [ 0.0000, 0.0000, 0.6602], [ 0.0000, 0.0000, 0.0000]])
class TriangularCausalMask():
def __init__(self, B, L, device="cpu"):
mask_shape = [B, 1, L, L]
with torch.no_grad():
self._mask = torch.triu(torch.ones(mask_shape, dtype=torch.bool), diagonal=1).to(device)
@property
def mask(self):
return self._mask
b) ProbMask
class ProbMask():
def __init__(self, B, H, L, index, scores, device="cpu"):
_mask = torch.ones(L, scores.shape[-1], dtype=torch.bool).to(device).triu(1)
_mask_ex = _mask[None, None, :].expand(B, H, L, scores.shape[-1])
indicator = _mask_ex[torch.arange(B)[:, None, None],
torch.arange(H)[None, :, None],
index, :].to(device)
self._mask = indicator.view(scores.shape).to(device)
@property
def mask(self):
return self._mask
(1) AttentionLayer
attention: 사용할 attention의 종류- 후보 1)
FullAttention - 후보 2)
ProbAttention
- 후보 1)
d_model: (Attention의 input으로 들어 갈) 이전에 embedding해서 나왔던 dimensionn_heads: Attention head의 개수
class AttentionLayer(nn.Module):
def __init__(self, attention, d_model, n_heads,
d_K=None, d_V=None, mix=False):
super(AttentionLayer, self).__init__()
d_K = d_K or (d_model//n_heads)
d_V = d_V or (d_model//n_heads)
# (1) inner_attention : 사용할 attention 종류
self.inner_attention = attention
# (2) Wq,Wk,Wv : Q,K,V를 만들 projection weight matrix
## ( n_head=8개를 병렬적으로 동시에 수행한다 )
self.Wq = nn.Linear(d_model, d_K * n_heads)
self.Wk = nn.Linear(d_model, d_K * n_heads)
self.Wv = nn.Linear(d_model, d_V * n_heads)
self.Wo = nn.Linear(d_V * n_heads, d_model)
self.n_heads = n_heads
self.mix = mix
def forward(self, Q, K, V, attn_mask):
B, L, _ = Q.shape
_, S, _ = K.shape
H = self.n_heads
# (1) Q,K,V 계산
Q = self.Wq(Q).view(B, L, H, -1)
K = self.Wk(K).view(B, S, H, -1)
V = self.Wv(V).view(B, S, H, -1)
# (2) Attention 수행 ( via Q,K,V )
out, attn = self.inner_attention(Q,K,V,attn_mask)
# (3) Output x Weight로 최종 출력값 계산
if self.mix:
out = out.transpose(2,1).contiguous()
out = out.view(B, L, -1)
out = self.Wo(out)
return out, attn
(2) FullAttention
scale: softmax에 들어갈 값에 곱하는 scale
class FullAttention(nn.Module):
def __init__(self, mask_flag=True, factor=5, scale=None,
attention_dropout=0.1, output_attention=False):
super(FullAttention, self).__init__()
self.scale = scale
self.mask_flag = mask_flag
self.output_attention = output_attention
self.dropout = nn.Dropout(attention_dropout)
def forward(self, Q, K, V, attn_mask):
B, L, H, E = Q.shape
_, S, _, D = V.shape
scale = self.scale or 1./sqrt(E)
scores = torch.einsum("blhe,bshe->bhls", Q, K)
if self.mask_flag:
if attn_mask is None:
attn_mask = TriangularCausalMask(B, L, device=Q.device)
scores.masked_fill_(attn_mask.mask, -np.inf)
A = self.dropout(torch.softmax(scale * scores, dim=-1))
V = torch.einsum("bhls,bshd->blhd", A, V)
if self.output_attention:
return (V.contiguous(), A)
else:
return (V.contiguous(), None)
(3) ProbAttention
class ProbAttention(nn.Module):
def __init__(self, mask_flag=True, factor=5, scale=None,
attention_dropout=0.1, output_attention=False):
super(ProbAttention, self).__init__()
self.factor = factor
self.scale = scale
self.mask_flag = mask_flag
self.output_attention = output_attention
self.dropout = nn.Dropout(attention_dropout)
def _prob_QK(self, Q, K, sample_k, n_top): # n_top: c*ln(L_q)
# [ B(=Batch Size), H(=Head의 개수), L(=Length), D(=Dimension) ]
B, H, L_K, E = K.shape
_, _, L_Q, _ = Q.shape
# (1) sampled Q_K 계산
K_expand = K.unsqueeze(-3).expand(B, H, L_Q, L_K, E)
index_sample = torch.randint(L_K, (L_Q, sample_k))
K_sample = K_expand[:, :, torch.arange(L_Q).unsqueeze(1), index_sample, :]
Q_K_sample = torch.matmul(Q.unsqueeze(-2), K_sample.transpose(-2, -1)).squeeze()
# (2) Top_k query with sparisty measurement 찾기
## torch.topk : (index=0) 값 & (index=1) 인덱스
M = Q_K_sample.max(-1)[0] - torch.div(Q_K_sample.sum(-1), L_K)
M_top = M.topk(n_top, sorted=False)[1]
## (3) Top_K query만을 사용하여 Q*K 계산
Q_reduce = Q[torch.arange(B)[:, None, None],
torch.arange(H)[None, :, None],
M_top, :] # factor*ln(L_q)
Q_K = torch.matmul(Q_reduce, K.transpose(-2, -1)) # factor*ln(L_q)*L_k
## (4) Q*K와 Top k 인덱스 반환
return Q_K, M_top
def _get_initial_context(self, V, L_Q):
B, H, L_V, D = V.shape
if not self.mask_flag:
V_sum = V.mean(dim=-2) # V_sum = V.sum(dim=-2)
contex = V_sum.unsqueeze(-2).expand(B, H, L_Q, V_sum.shape[-1]).clone()
else: # use mask
assert(L_Q == L_V) # requires that L_Q == L_V, i.e. for self-attention only
contex = V.cumsum(dim=-2)
return contex
def _update_context(self, context_in, V, scores, index, L_Q, attn_mask):
B, H, L_V, D = V.shape
if self.mask_flag:
attn_mask = ProbMask(B, H, L_Q, index, scores, device=V.device)
scores.masked_fill_(attn_mask.mask, -np.inf)
attn = torch.softmax(scores, dim=-1) # nn.Softmax(dim=-1)(scores)
context_in[torch.arange(B)[:, None, None],
torch.arange(H)[None, :, None],
index, :] = torch.matmul(attn, V).type_as(context_in)
if self.output_attention:
attns = (torch.ones([B, H, L_V, L_V])/L_V).type_as(attn).to(attn.device)
attns[torch.arange(B)[:, None, None], torch.arange(H)[None, :, None], index, :] = attn
return (context_in, attns)
else:
return (context_in, None)
def forward(self, Q, K, V, attn_mask):
B, L_Q, H, D = Q.shape
_, L_K, _, _ = K.shape
Q = Q.transpose(2,1)
K = K.transpose(2,1)
V = V.transpose(2,1)
U_part = self.factor * np.ceil(np.log(L_K)).astype('int').item() # c*ln(L_k)
u = self.factor * np.ceil(np.log(L_Q)).astype('int').item() # c*ln(L_q)
U_part = U_part if U_part<L_K else L_K
u = u if u<L_Q else L_Q
scores_top, index = self._prob_QK(Q, K, sample_k=U_part, n_top=u)
# add scale factor
scale = self.scale or 1./sqrt(D)
if scale is not None:
scores_top = scores_top * scale
# get the context
context = self._get_initial_context(V, L_Q)
# update the context with selected top_k Q
context, attn = self._update_context(context, V, scores_top, index, L_Q, attn_mask)
return context.transpose(2,1).contiguous(), attn
6. Time Features
def time_features(dates, timeenc=1, freq='h'):
"""
> `time_features` takes in a `dates` dataframe with a 'dates' column and extracts the date down to `freq` where freq can be any of the following if `timeenc` is 0:
> * m - [month]
> * w - [month]
> * d - [month, day, weekday]
> * b - [month, day, weekday]
> * h - [month, day, weekday, hour]
> * t - [month, day, weekday, hour, *minute]
>
> If `timeenc` is 1, a similar, but different list of `freq` values are supported (all encoded between [-0.5 and 0.5]):
> * Q - [month]
> * M - [month]
> * W - [Day of month, week of year]
> * D - [Day of week, day of month, day of year]
> * B - [Day of week, day of month, day of year]
> * H - [Hour of day, day of week, day of month, day of year]
> * T - [Minute of hour*, hour of day, day of week, day of month, day of year]
> * S - [Second of minute, minute of hour, hour of day, day of week, day of month, day of year]
*minute returns a number from 0-3 corresponding to the 15 minute period it falls into.
"""
if timeenc==0:
dates['month'] = dates.date.apply(lambda row:row.month,1)
dates['day'] = dates.date.apply(lambda row:row.day,1)
dates['weekday'] = dates.date.apply(lambda row:row.weekday(),1)
dates['hour'] = dates.date.apply(lambda row:row.hour,1)
dates['minute'] = dates.date.apply(lambda row:row.minute,1)
dates['minute'] = dates.minute.map(lambda x:x//15)
freq_map = {
'y':[],'m':['month'],'w':['month'],'d':['month','day','weekday'],
'b':['month','day','weekday'],'h':['month','day','weekday','hour'],
't':['month','day','weekday','hour','minute'],
}
return dates[freq_map[freq.lower()]].values
if timeenc==1:
dates = pd.to_datetime(dates.date.values)
return np.vstack([feat(dates) for feat in time_features_from_frequency_str(freq)]).transpose(1,0)
6. Data Loader
import os
import numpy as np
import pandas as pd
import torch
from torch.utils.data import Dataset, DataLoader
# from sklearn.preprocessing import StandardScaler
from utils.tools import StandardScaler
from utils.timefeatures import time_features
import warnings
warnings.filterwarnings('ignore')
ETT : Electricity Transformer Temperature (ETT)
(1) etth1.csv & etth2.csv
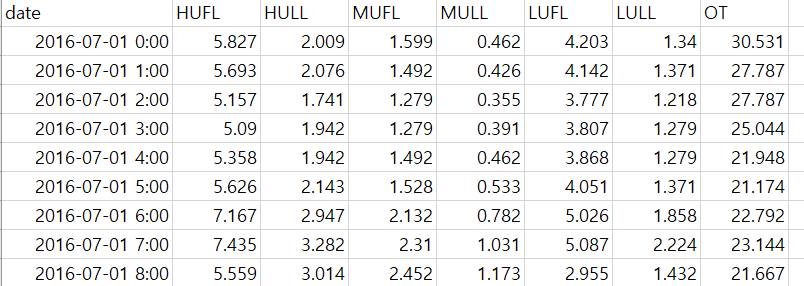
-
크기 : (17421,7)
- start : 2016-07-01 0:00
- end : 2018-06-26 19:00
(2) ettm1.csv & ettm2.csv
- 크기 : (69681,7)
- start : 2016-07-01 0:00
- end : 2018-06-26 19:45
(1) Dataset_ETT_hour
features : M,S,MS
- M : Multivariate predict Multivariate
- S : Univariate predict Univariate
- MS : Multivariate predict Univariate
Length
-
seq_len : “Input sequence length” of Informer encoder (defaults to 96)
-
label_len : “Start token length” of Informer decoder (defaults to 48)
-
pred_len : “Prediction sequence length” (defaults to 24)
class Dataset_ETT_hour(Dataset):
def __init__(self, root_path, flag='train', size=None,
features='S', data_path='ETTh1.csv',
target='OT', scale=True, inverse=False, timeenc=0, freq='h', cols=None):
# size [seq_len, label_len, pred_len]
# info
if size == None:
self.seq_len = 24*4*4
self.label_len = 24*4
self.pred_len = 24*4
else:
self.seq_len = size[0]
self.label_len = size[1]
self.pred_len = size[2]
# init
assert flag in ['train', 'test', 'val']
type_map = {'train':0, 'val':1, 'test':2}
self.set_type = type_map[flag]
self.features = features
self.target = target
self.scale = scale
self.inverse = inverse
self.timeenc = timeenc
self.freq = freq
self.root_path = root_path
self.data_path = data_path
self.__read_data__()
def __read_data__(self):
self.scaler = StandardScaler()
#---------------------------------------------------------------#
# (1) Data 불러오기
df_raw = pd.read_csv(os.path.join(self.root_path,self.data_path))
#---------------------------------------------------------------#
# (2) Train/Valid/Test
## index = 0 : train의 시작 index
## index = 1 : valid의 시작 index
## index = 2 : test의 시작 index
border1s = [0, 12*30*24 - self.seq_len, 12*30*24+4*30*24 - self.seq_len]
border2s = [12*30*24, 12*30*24+4*30*24, 12*30*24+8*30*24]
border1 = border1s[self.set_type]
border2 = border2s[self.set_type]
#---------------------------------------------------------------#
# (3) Task 설정
### M, MS : X가 multivariate
### S : X가 univariate
if self.features=='M' or self.features=='MS':
cols_data = df_raw.columns[1:]
df_data = df_raw[cols_data]
elif self.features=='S':
df_data = df_raw[[self.target]]
#---------------------------------------------------------------#
# (4) Standard Scaling
if self.scale:
train_data = df_data[border1s[0]:border2s[0]]
self.scaler.fit(train_data.values)
data = self.scaler.transform(df_data.values)
else:
data = df_data.values
#---------------------------------------------------------------#
# (5) 날짜 stamp
## df_stamp : date 정보
## data_stamp : date 정보 칼럼 담고 있는 것을 input으로 받아, "extracts the date down to `freq`"
df_stamp = df_raw[['date']][border1:border2]
df_stamp['date'] = pd.to_datetime(df_stamp.date)
data_stamp = time_features(df_stamp, timeenc=self.timeenc, freq=self.freq)
self.data_stamp = data_stamp
#---------------------------------------------------------------#
# (6) X & Y 데이터 설정하기
self.data_x = data[border1:border2]
if self.inverse:
self.data_y = df_data.values[border1:border2]
else:
self.data_y = data[border1:border2]
def __getitem__(self, index):
s_begin = index
s_end = s_begin + self.seq_len
r_begin = s_end - self.label_len
r_end = r_begin + self.label_len + self.pred_len
seq_x = self.data_x[s_begin:s_end]
if self.inverse:
seq_y = np.concatenate([self.data_x[r_begin:r_begin+self.label_len], self.data_y[r_begin+self.label_len:r_end]], 0)
else:
seq_y = self.data_y[r_begin:r_end]
seq_x_mark = self.data_stamp[s_begin:s_end]
seq_y_mark = self.data_stamp[r_begin:r_end]
return seq_x, seq_y, seq_x_mark, seq_y_mark
def __len__(self):
return len(self.data_x) - self.seq_len- self.pred_len + 1
def inverse_transform(self, data):
return self.scaler.inverse_transform(data)
(2) Dataset_ETT_minute
class Dataset_ETT_minute(Dataset):
def __init__(self, root_path, flag='train', size=None,
features='S', data_path='ETTm1.csv',
target='OT', scale=True, inverse=False, timeenc=0, freq='t', cols=None):
# size [seq_len, label_len, pred_len]
# info
if size == None:
self.seq_len = 24*4*4
self.label_len = 24*4
self.pred_len = 24*4
else:
self.seq_len = size[0]
self.label_len = size[1]
self.pred_len = size[2]
# init
assert flag in ['train', 'test', 'val']
type_map = {'train':0, 'val':1, 'test':2}
self.set_type = type_map[flag]
self.features = features
self.target = target
self.scale = scale
self.inverse = inverse
self.timeenc = timeenc
self.freq = freq
self.root_path = root_path
self.data_path = data_path
self.__read_data__()
def __read_data__(self):
self.scaler = StandardScaler()
df_raw = pd.read_csv(os.path.join(self.root_path,
self.data_path))
border1s = [0, 12*30*24*4 - self.seq_len, 12*30*24*4+4*30*24*4 - self.seq_len]
border2s = [12*30*24*4, 12*30*24*4+4*30*24*4, 12*30*24*4+8*30*24*4]
border1 = border1s[self.set_type]
border2 = border2s[self.set_type]
if self.features=='M' or self.features=='MS':
cols_data = df_raw.columns[1:]
df_data = df_raw[cols_data]
elif self.features=='S':
df_data = df_raw[[self.target]]
if self.scale:
train_data = df_data[border1s[0]:border2s[0]]
self.scaler.fit(train_data.values)
data = self.scaler.transform(df_data.values)
else:
data = df_data.values
df_stamp = df_raw[['date']][border1:border2]
df_stamp['date'] = pd.to_datetime(df_stamp.date)
data_stamp = time_features(df_stamp, timeenc=self.timeenc, freq=self.freq)
self.data_x = data[border1:border2]
if self.inverse:
self.data_y = df_data.values[border1:border2]
else:
self.data_y = data[border1:border2]
self.data_stamp = data_stamp
def __getitem__(self, index):
s_begin = index
s_end = s_begin + self.seq_len
r_begin = s_end - self.label_len
r_end = r_begin + self.label_len + self.pred_len
seq_x = self.data_x[s_begin:s_end]
if self.inverse:
seq_y = np.concatenate([self.data_x[r_begin:r_begin+self.label_len], self.data_y[r_begin+self.label_len:r_end]], 0)
else:
seq_y = self.data_y[r_begin:r_end]
seq_x_mark = self.data_stamp[s_begin:s_end]
seq_y_mark = self.data_stamp[r_begin:r_end]
return seq_x, seq_y, seq_x_mark, seq_y_mark
def __len__(self):
return len(self.data_x) - self.seq_len - self.pred_len + 1
def inverse_transform(self, data):
return self.scaler.inverse_transform(data)
(3) Dataset_Custom
class Dataset_Custom(Dataset):
def __init__(self, root_path, flag='train', size=None,
features='S', data_path='ETTh1.csv',
target='OT', scale=True, inverse=False, timeenc=0, freq='h', cols=None):
# size [seq_len, label_len, pred_len]
# info
if size == None:
self.seq_len = 24*4*4
self.label_len = 24*4
self.pred_len = 24*4
else:
self.seq_len = size[0]
self.label_len = size[1]
self.pred_len = size[2]
# init
assert flag in ['train', 'test', 'val']
type_map = {'train':0, 'val':1, 'test':2}
self.set_type = type_map[flag]
self.features = features
self.target = target
self.scale = scale
self.inverse = inverse
self.timeenc = timeenc
self.freq = freq
self.cols=cols
self.root_path = root_path
self.data_path = data_path
self.__read_data__()
def __read_data__(self):
self.scaler = StandardScaler()
df_raw = pd.read_csv(os.path.join(self.root_path,
self.data_path))
'''
df_raw.columns: ['date', ...(other features), target feature]
'''
# cols = list(df_raw.columns);
if self.cols:
cols=self.cols.copy()
cols.remove(self.target)
else:
cols = list(df_raw.columns); cols.remove(self.target); cols.remove('date')
df_raw = df_raw[['date']+cols+[self.target]]
num_train = int(len(df_raw)*0.7)
num_test = int(len(df_raw)*0.2)
num_vali = len(df_raw) - num_train - num_test
border1s = [0, num_train-self.seq_len, len(df_raw)-num_test-self.seq_len]
border2s = [num_train, num_train+num_vali, len(df_raw)]
border1 = border1s[self.set_type]
border2 = border2s[self.set_type]
if self.features=='M' or self.features=='MS':
cols_data = df_raw.columns[1:]
df_data = df_raw[cols_data]
elif self.features=='S':
df_data = df_raw[[self.target]]
if self.scale:
train_data = df_data[border1s[0]:border2s[0]]
self.scaler.fit(train_data.values)
data = self.scaler.transform(df_data.values)
else:
data = df_data.values
df_stamp = df_raw[['date']][border1:border2]
df_stamp['date'] = pd.to_datetime(df_stamp.date)
data_stamp = time_features(df_stamp, timeenc=self.timeenc, freq=self.freq)
self.data_x = data[border1:border2]
if self.inverse:
self.data_y = df_data.values[border1:border2]
else:
self.data_y = data[border1:border2]
self.data_stamp = data_stamp
def __getitem__(self, index):
s_begin = index
s_end = s_begin + self.seq_len
r_begin = s_end - self.label_len
r_end = r_begin + self.label_len + self.pred_len
seq_x = self.data_x[s_begin:s_end]
if self.inverse:
seq_y = np.concatenate([self.data_x[r_begin:r_begin+self.label_len], self.data_y[r_begin+self.label_len:r_end]], 0)
else:
seq_y = self.data_y[r_begin:r_end]
seq_x_mark = self.data_stamp[s_begin:s_end]
seq_y_mark = self.data_stamp[r_begin:r_end]
return seq_x, seq_y, seq_x_mark, seq_y_mark
def __len__(self):
return len(self.data_x) - self.seq_len- self.pred_len + 1
def inverse_transform(self, data):
return self.scaler.inverse_transform(data)
(4) Dataset_Pred
class Dataset_Pred(Dataset):
def __init__(self, root_path, flag='pred', size=None,
features='S', data_path='ETTh1.csv',
target='OT', scale=True, inverse=False, timeenc=0, freq='15min', cols=None):
# size [seq_len, label_len, pred_len]
# info
if size == None:
self.seq_len = 24*4*4
self.label_len = 24*4
self.pred_len = 24*4
else:
self.seq_len = size[0]
self.label_len = size[1]
self.pred_len = size[2]
# init
assert flag in ['pred']
self.features = features
self.target = target
self.scale = scale
self.inverse = inverse
self.timeenc = timeenc
self.freq = freq
self.cols=cols
self.root_path = root_path
self.data_path = data_path
self.__read_data__()
def __read_data__(self):
self.scaler = StandardScaler()
df_raw = pd.read_csv(os.path.join(self.root_path,
self.data_path))
'''
df_raw.columns: ['date', ...(other features), target feature]
'''
if self.cols:
cols=self.cols.copy()
cols.remove(self.target)
else:
cols = list(df_raw.columns); cols.remove(self.target); cols.remove('date')
df_raw = df_raw[['date']+cols+[self.target]]
border1 = len(df_raw)-self.seq_len
border2 = len(df_raw)
if self.features=='M' or self.features=='MS':
cols_data = df_raw.columns[1:]
df_data = df_raw[cols_data]
elif self.features=='S':
df_data = df_raw[[self.target]]
if self.scale:
self.scaler.fit(df_data.values)
data = self.scaler.transform(df_data.values)
else:
data = df_data.values
tmp_stamp = df_raw[['date']][border1:border2]
tmp_stamp['date'] = pd.to_datetime(tmp_stamp.date)
pred_dates = pd.date_range(tmp_stamp.date.values[-1], periods=self.pred_len+1, freq=self.freq)
df_stamp = pd.DataFrame(columns = ['date'])
df_stamp.date = list(tmp_stamp.date.values) + list(pred_dates[1:])
data_stamp = time_features(df_stamp, timeenc=self.timeenc, freq=self.freq[-1:])
self.data_x = data[border1:border2]
if self.inverse:
self.data_y = df_data.values[border1:border2]
else:
self.data_y = data[border1:border2]
self.data_stamp = data_stamp
def __getitem__(self, index):
s_begin = index
s_end = s_begin + self.seq_len
r_begin = s_end - self.label_len
r_end = r_begin + self.label_len + self.pred_len
seq_x = self.data_x[s_begin:s_end]
if self.inverse:
seq_y = self.data_x[r_begin:r_begin+self.label_len]
else:
seq_y = self.data_y[r_begin:r_begin+self.label_len]
seq_x_mark = self.data_stamp[s_begin:s_end]
seq_y_mark = self.data_stamp[r_begin:r_end]
return seq_x, seq_y, seq_x_mark, seq_y_mark
def __len__(self):
return len(self.data_x) - self.seq_len + 1
def inverse_transform(self, data):
return self.scaler.inverse_transform(data)
7. Exp_Informer ( Experiment )
from data.data_loader import Dataset_ETT_hour, Dataset_ETT_minute, Dataset_Custom, Dataset_Pred
from exp.exp_basic import Exp_Basic
from models.model import Informer, InformerStack
from utils.tools import EarlyStopping, adjust_learning_rate
from utils.metrics import metric
import numpy as np
from data.data_loader import Dataset_ETT_hour, Dataset_ETT_minute, Dataset_Custom, Dataset_Pred
from exp.exp_basic import Exp_Basic
from models.model import Informer, InformerStack
from utils.tools import EarlyStopping, adjust_learning_rate
from utils.metrics import metric
import numpy as np
import torch
import torch.nn as nn
from torch import optim
from torch.utils.data import DataLoader
import os
import time
import warnings
warnings.filterwarnings('ignore')
class Exp_Informer(Exp_Basic):
def __init__(self, args):
super(Exp_Informer, self).__init__(args)
def _build_model(self):
model_dict = {
'informer':Informer,
'informerstack':InformerStack,
}
if self.args.model=='informer' or self.args.model=='informerstack':
e_layers = self.args.e_layers if self.args.model=='informer' else self.args.s_layers
model = model_dict[self.args.model](
self.args.enc_in,
self.args.dec_in,
self.args.c_out,
self.args.seq_len,
self.args.label_len,
self.args.pred_len,
self.args.factor,
self.args.d_model,
self.args.n_heads,
e_layers, # self.args.e_layers,
self.args.d_layers,
self.args.d_ff,
self.args.dropout,
self.args.attn,
self.args.embed,
self.args.freq,
self.args.activation,
self.args.output_attention,
self.args.distil,
self.args.mix,
self.device
).float()
if self.args.use_multi_gpu and self.args.use_gpu:
model = nn.DataParallel(model, device_ids=self.args.device_ids)
return model
def _get_data(self, flag):
args = self.args
data_dict = {
'ETTh1':Dataset_ETT_hour,
'ETTh2':Dataset_ETT_hour,
'ETTm1':Dataset_ETT_minute,
'ETTm2':Dataset_ETT_minute,
'WTH':Dataset_Custom,
'ECL':Dataset_Custom,
'Solar':Dataset_Custom,
'custom':Dataset_Custom,
}
Data = data_dict[self.args.data]
timeenc = 0 if args.embed!='timeF' else 1
if flag == 'test':
shuffle_flag = False; drop_last = True; batch_size = args.batch_size; freq=args.freq
elif flag=='pred':
shuffle_flag = False; drop_last = False; batch_size = 1; freq=args.detail_freq
Data = Dataset_Pred
else:
shuffle_flag = True; drop_last = True; batch_size = args.batch_size; freq=args.freq
data_set = Data(
root_path=args.root_path,
data_path=args.data_path,
flag=flag,
size=[args.seq_len, args.label_len, args.pred_len],
features=args.features,
target=args.target,
inverse=args.inverse,
timeenc=timeenc,
freq=freq,
cols=args.cols
)
print(flag, len(data_set))
data_loader = DataLoader(
data_set,
batch_size=batch_size,
shuffle=shuffle_flag,
num_workers=args.num_workers,
drop_last=drop_last)
return data_set, data_loader
def _select_optimizer(self):
model_optim = optim.Adam(self.model.parameters(), lr=self.args.learning_rate)
return model_optim
def _select_criterion(self):
criterion = nn.MSELoss()
return criterion
def vali(self, vali_data, vali_loader, criterion):
self.model.eval()
total_loss = []
for i, (batch_x,batch_y,batch_x_mark,batch_y_mark) in enumerate(vali_loader):
pred, true = self._process_one_batch(
vali_data, batch_x, batch_y, batch_x_mark, batch_y_mark)
loss = criterion(pred.detach().cpu(), true.detach().cpu())
total_loss.append(loss)
total_loss = np.average(total_loss)
self.model.train()
return total_loss
def train(self, setting):
train_data, train_loader = self._get_data(flag = 'train')
vali_data, vali_loader = self._get_data(flag = 'val')
test_data, test_loader = self._get_data(flag = 'test')
path = os.path.join(self.args.checkpoints, setting)
if not os.path.exists(path):
os.makedirs(path)
time_now = time.time()
train_steps = len(train_loader)
early_stopping = EarlyStopping(patience=self.args.patience, verbose=True)
model_optim = self._select_optimizer()
criterion = self._select_criterion()
if self.args.use_amp:
scaler = torch.cuda.amp.GradScaler()
for epoch in range(self.args.train_epochs):
iter_count = 0
train_loss = []
self.model.train()
epoch_time = time.time()
for i, (batch_x,batch_y,batch_x_mark,batch_y_mark) in enumerate(train_loader):
iter_count += 1
model_optim.zero_grad()
pred, true = self._process_one_batch(
train_data, batch_x, batch_y, batch_x_mark, batch_y_mark)
loss = criterion(pred, true)
train_loss.append(loss.item())
if (i+1) % 100==0:
print("\titers: {0}, epoch: {1} | loss: {2:.7f}".format(i + 1, epoch + 1, loss.item()))
speed = (time.time()-time_now)/iter_count
left_time = speed*((self.args.train_epochs - epoch)*train_steps - i)
print('\tspeed: {:.4f}s/iter; left time: {:.4f}s'.format(speed, left_time))
iter_count = 0
time_now = time.time()
if self.args.use_amp:
scaler.scale(loss).backward()
scaler.step(model_optim)
scaler.update()
else:
loss.backward()
model_optim.step()
print("Epoch: {} cost time: {}".format(epoch+1, time.time()-epoch_time))
train_loss = np.average(train_loss)
vali_loss = self.vali(vali_data, vali_loader, criterion)
test_loss = self.vali(test_data, test_loader, criterion)
print("Epoch: {0}, Steps: {1} | Train Loss: {2:.7f} Vali Loss: {3:.7f} Test Loss: {4:.7f}".format(
epoch + 1, train_steps, train_loss, vali_loss, test_loss))
early_stopping(vali_loss, self.model, path)
if early_stopping.early_stop:
print("Early stopping")
break
adjust_learning_rate(model_optim, epoch+1, self.args)
best_model_path = path+'/'+'checkpoint.pth'
self.model.load_state_dict(torch.load(best_model_path))
return self.model
def test(self, setting):
test_data, test_loader = self._get_data(flag='test')
self.model.eval()
preds = []
trues = []
for i, (batch_x,batch_y,batch_x_mark,batch_y_mark) in enumerate(test_loader):
pred, true = self._process_one_batch(
test_data, batch_x, batch_y, batch_x_mark, batch_y_mark)
preds.append(pred.detach().cpu().numpy())
trues.append(true.detach().cpu().numpy())
preds = np.array(preds)
trues = np.array(trues)
print('test shape:', preds.shape, trues.shape)
preds = preds.reshape(-1, preds.shape[-2], preds.shape[-1])
trues = trues.reshape(-1, trues.shape[-2], trues.shape[-1])
print('test shape:', preds.shape, trues.shape)
# result save
folder_path = './results/' + setting +'/'
if not os.path.exists(folder_path):
os.makedirs(folder_path)
mae, mse, rmse, mape, mspe = metric(preds, trues)
print('mse:{}, mae:{}'.format(mse, mae))
np.save(folder_path+'metrics.npy', np.array([mae, mse, rmse, mape, mspe]))
np.save(folder_path+'pred.npy', preds)
np.save(folder_path+'true.npy', trues)
return
def predict(self, setting, load=False):
pred_data, pred_loader = self._get_data(flag='pred')
if load:
path = os.path.join(self.args.checkpoints, setting)
best_model_path = path+'/'+'checkpoint.pth'
self.model.load_state_dict(torch.load(best_model_path))
self.model.eval()
preds = []
for i, (batch_x,batch_y,batch_x_mark,batch_y_mark) in enumerate(pred_loader):
pred, true = self._process_one_batch(
pred_data, batch_x, batch_y, batch_x_mark, batch_y_mark)
preds.append(pred.detach().cpu().numpy())
preds = np.array(preds)
preds = preds.reshape(-1, preds.shape[-2], preds.shape[-1])
# result save
folder_path = './results/' + setting +'/'
if not os.path.exists(folder_path):
os.makedirs(folder_path)
np.save(folder_path+'real_prediction.npy', preds)
return
def _process_one_batch(self, dataset_object, batch_x, batch_y, batch_x_mark, batch_y_mark):
batch_x = batch_x.float().to(self.device)
batch_y = batch_y.float()
batch_x_mark = batch_x_mark.float().to(self.device)
batch_y_mark = batch_y_mark.float().to(self.device)
# decoder input
if self.args.padding==0:
dec_inp = torch.zeros([batch_y.shape[0], self.args.pred_len, batch_y.shape[-1]]).float()
elif self.args.padding==1:
dec_inp = torch.ones([batch_y.shape[0], self.args.pred_len, batch_y.shape[-1]]).float()
dec_inp = torch.cat([batch_y[:,:self.args.label_len,:], dec_inp], dim=1).float().to(self.device)
# encoder - decoder
if self.args.use_amp:
with torch.cuda.amp.autocast():
if self.args.output_attention:
outputs = self.model(batch_x, batch_x_mark, dec_inp, batch_y_mark)[0]
else:
outputs = self.model(batch_x, batch_x_mark, dec_inp, batch_y_mark)
else:
if self.args.output_attention:
outputs = self.model(batch_x, batch_x_mark, dec_inp, batch_y_mark)[0]
else:
outputs = self.model(batch_x, batch_x_mark, dec_inp, batch_y_mark)
if self.args.inverse:
outputs = dataset_object.inverse_transform(outputs)
f_dim = -1 if self.args.features=='MS' else 0
batch_y = batch_y[:,-self.args.pred_len:,f_dim:].to(self.device)
return outputs, batch_y