LLM4TS: Two-stage Fine-tuning for TSF with Pretrained LLMs (2023)
https://arxiv.org/pdf/2308.08469.pdf
Contents
- Abstract
- Introduction
- Related Work
- In-modality Knowledge Transfer
- Cross-modality Knowledge Transfer
- Problem Formulation
- Method
- Two-stage FT
- Details of LLM4TS
- Experiments
- MTS forecasting
- Few-shot learning
- SSL
- Ablation Study
0. Abstract
Limited large-scale TS data for building robust foundation models
\(\rightarrow\) use Pre-trained Large Language Models (LLMs) to enhance TSF
Details
-
time-series patching + temporal encoding
- prioritize a two-stage fine-tuning process:
- step 1) supervised fine-tuning to orient the LLM towards TS
- step 2) task-specific downstream finetuning
- Parameter-Efficient Fine-Tuning (PEFT) techniques
- Experiment
- robust representation learner
- effective few-shot learner
1. Introduction
Background
-
Foundation models in NLP & CV
-
Limited availability of large-scale TS data to train robust foundation models
\(\rightarrow\) utilizing pre-trained Large Language Models (LLMs) as powerful representation learners for TS
To integrate LLMs with TS data … 2 pivotal questions
- Q1) How can we input time-series data into LLMs?
- Q2) How can we utilize pre-trained LLMs without distorting their inherent features?
Q1) Input TS into LLMs
To accommodate new data modalities within LLMs…
\(\rightarrow\) essential to (1) tokenize the data ( feat. PatchTST )
(2) Channel-independence
Summary
- introduce a novel approach that integrates temporal information,
- while employing the techniques of patching and channel-independence
Q2) Utilize LLM without distorting inherent features
High-quality chatbots ( Instruct GPT, ChatGPT )
-
requires strategic alignment of a pre-trained model with instruction-based data through supervised fine-tuning
\(\rightarrow\) ensures the model becomes familiarized with target data formats
Introduce a TWO-stage fine-tuning approach
- step 1) supervised fine-tuning
- guiding the LLM towards TS data
- step 2) downstream fine-tuning
- geared towards TSF task
( still, there is a need to enhance the pre-trained LLMs’ adaptability to new data modalities without distorting models’ inherent features )
\(\rightarrow\) two Parameter-Efficient Fine-Tuning (PEFT) techniques
- Layer Normalization Tuning (Lu et al. 2021)
- LoRA (Hu et al. 2021)
to optimize model flexibility without extensive parameter adjustments
Summary
- Integration of Time-Series with LLMs
- patching and channel-independence to tokenize TS data
- novel approach to integrate temporal information with patching
- Adaptable Fine-Tuning for LLMs
- twostage fine-tuning methodology
- step 1) supervised finetuning stage to align LLMs with TS
- step 2) downstream fine-tuning stage dedicated to TSF task
- twostage fine-tuning methodology
- Optimized Model Flexibility
- To ensure both robustness and adaptability
- two PEFT techniques
- Layer Normalization Tuning
- LoRA
- Real-World Application Relevance
2. Related Work
(1) In-modality Knowledge Transfer
Foundation models
- capable to transfer knowledge to downstream tasks
- transformation of LLMs into chatbots
- ex) InstructGPT, ChatGPT: employ supervised fine-tuning
Limitation of fine-tuning
- computational burden of refining an entire model can be significant.
\(\rightarrow\) solution: PEFT ( Parameter Efficient Fine Tuning )
PEFT ( Parameter Efficient Fine Tuning )
- popular technique to reduce costs
- ex) LLaMA-Adapter (Gao et al. 2023) : achieves ChatGPT-level performance by fine-tuning a mere 0.02% of its parameters
LLM4TS: integrate supervised fine-tuning & PEFT
(2) Cross-Modality Knowledge Transfer
Transfrer across diverse data modalities
- ex) NLP \(\rightarrow\) Image (Lu et al. 2021), Audio (Ghosal et al. 2023), TS (Zhou et al. 2023)
- ex) CV \(\rightarrow\) 12 distinct modalities (Zhang et al. 2023)
LLM4TS: utilize pretrained LLM expertise to address challenges in TS data
3. Problem Formulation
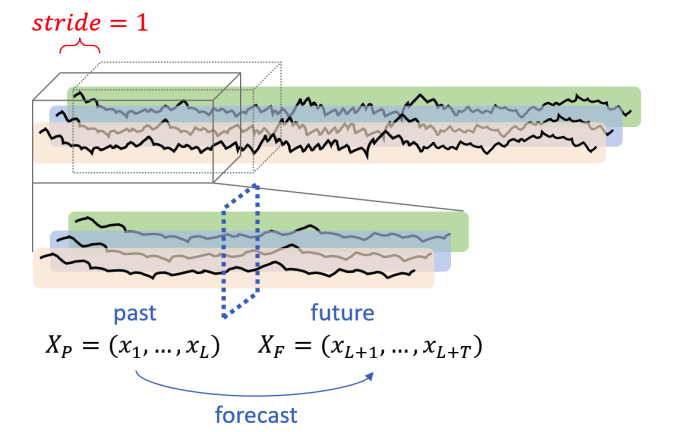
4. Method
LLM4TS framework
- leveraging the pre-trained GPT-2
- (4-1) introduce the two-stage finetuning training strategy
- (4-2) details
- instance normalization
- patching
- channel-independence
- three distinct encodings
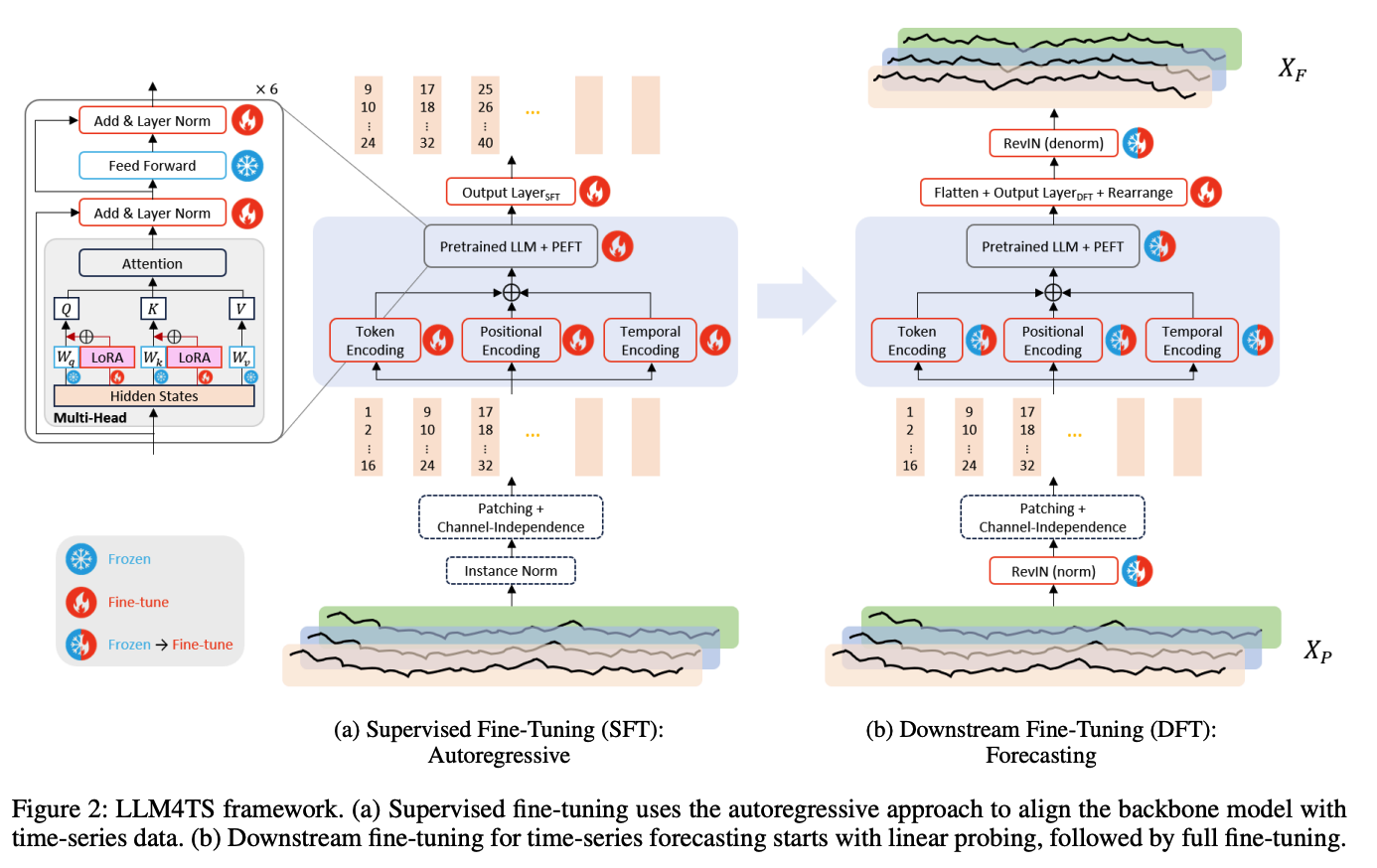
(1) Two-stage FT
a) Supervised FT: Autoregressive
GPT-2 (Radford et al. 2019): causal language model
\(\rightarrow\) supervised fine-tuning adopts the same autoregressive training methodology used during its pretraining phase.
Given 1st, 2nd, 3rd patches..
Predict 2nd, 3rd, 4th patches..
b) Downstream FT: Forecasting
2 primary strategies are available
- (1) full fine-tuning
- (2) linear probing
Sequential approach (LP-FT) is good!
- step 1) LP: linear probing ( epoch x 0.5 )
- step 2) FT: full fine-tuning ( epoch x 0.5 )
(2) Details of LLM4TS
a) Instance Normalization
- z-score norm) standard for TSF
- RevIN) further boosts accuracy
(????) Since RevIN is designed for the unpatched TS …. 2 problems
- (1) Denormalization is infeasible as outputs remain in the patched format rather than the unpatched format.
- (2) RevIN’s trainable affine transformation is not appropriate for AR models.
\(\rightarrow\) Employ “standard instance norm” during Sup FT
b) Patching & Channel Independence
- pass
c) Three Encodings
(1) Token embedding
- via 1D-convolution
(2) Positional encoding
- use the standard approach and employ a trainable lookup table
(3) Temporal encoding
- numerous studies suggest the advantage of incorporating temporal information with Transformer-based models in time-series analysis (Wen et al. 2022).
- Problem
- (1) patch = multiple timestamps = which timestamp to use…?
- (2) each timestamp carries various temporal attributes ( minute, hour, day .. )
- Solution
- (1) designate the initial timestamp as its representative
- (2) employ a trainable lookup table for each attribute
\(\rightarrow\) add (1) & (2) & (3)
d) Pre-Trained LLM and PEFT
Freeze
- particularly those associated with the multi-head attention and feedforward layers within the Transformer block.
- many studies indicate that retaining most parameters as non-trainable often yields better results than training a pre-trained LLM from scratch (Lu et al. 2021; Zhou et al. 2023).
Tune
- employ PEFT techniques as efficient approaches
- (1) utilize the selection-based method …. Layer Normalization Tuning (Lu et al. 2021)
- adjust pre-existing parameters by making the affine transformation in layer normalization trainable.
- (2) employ LoRA (LowRank Adaptation) (Hu et al. 2021)
- reparameterization-based method that leverages low-rank representations
Summary : only 1.5% of the model’s total parameters are trainable.
e) Output Layer
Supervised FT
- output remains in the form of patched TS ( tokens )
- employ a linear layer to modify the final dimension.
Downstream fine-tuning stage
- transforms the patched \(\rightarrow\) unpatched
- requiring flattening before the linear layer
For both, use dropout immediately after the linear transformation
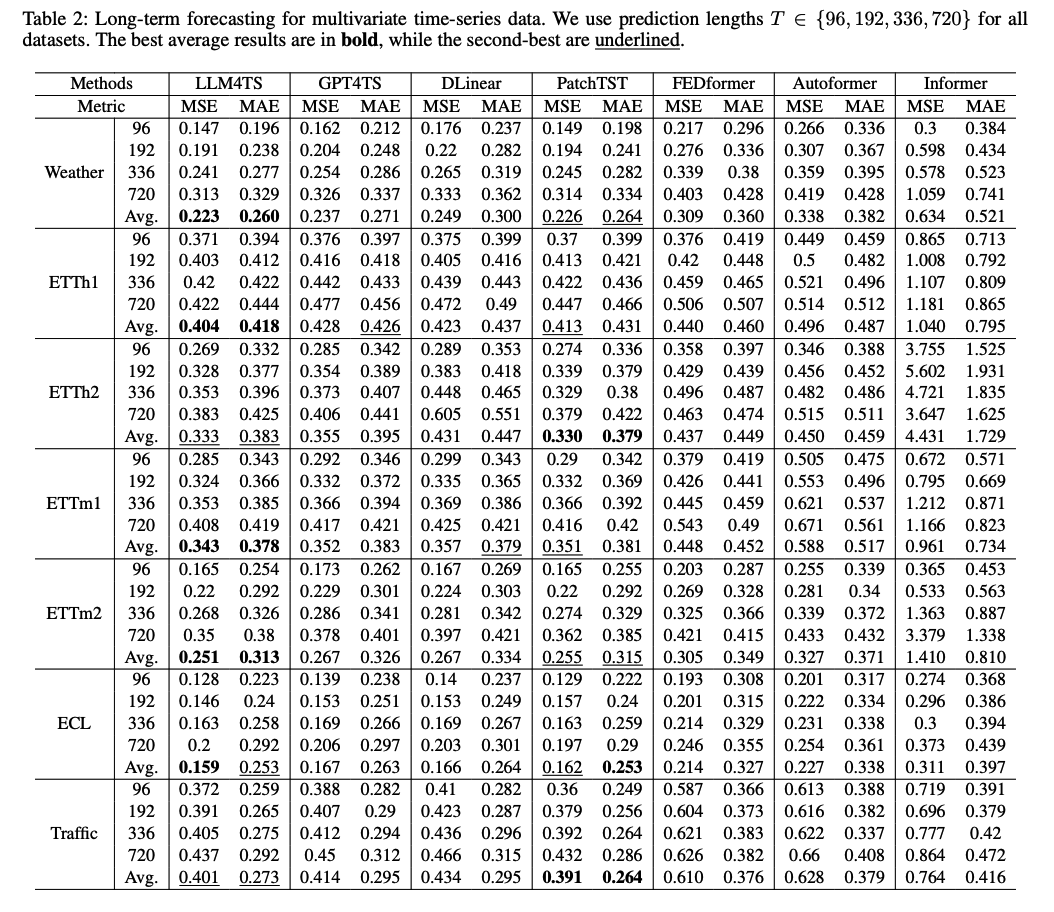
5. Experiments
(1) MTS forecasting
(2) Few-shot learning
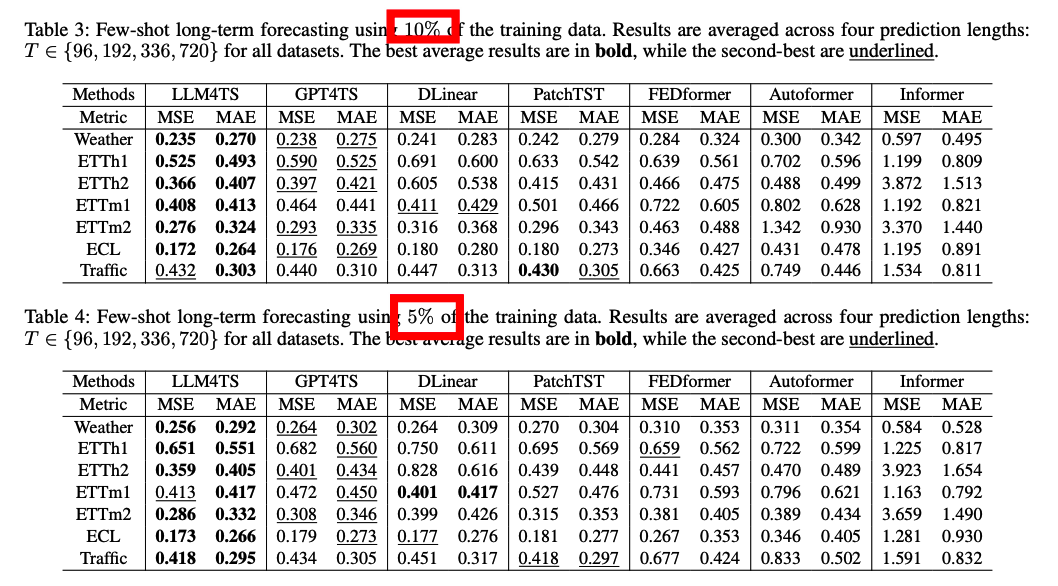
(3) SSL
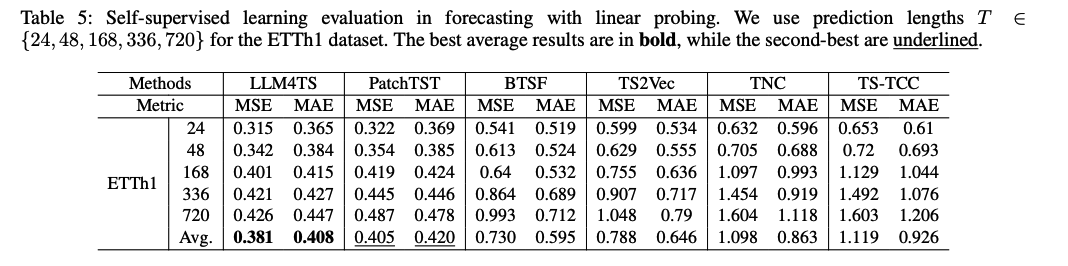
(4) Ablation Study
a) Supervised FT, Temporal Encoding, PEFT
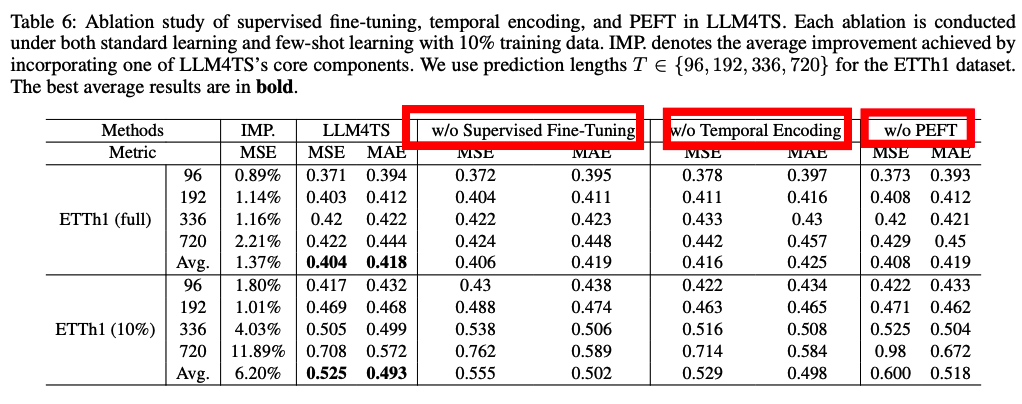
b) Training Strategies in Downstream FT