One Fits All: Power General TS Analysis by Pretrained LM
Contents
- Abstract
- Introduction
- Related Works
- In-modality Transfer Learning
- Cross-modality Transfer Learning
- Methodology
- Experiments
- Ablation Studies
- GPT2 vs. BERT vs. BEiT
- Efficiency Analysis
Abstract
Main challenge of foundation model in TS = Lack of large amount of TS data
Solution) leverage CV or NLP model
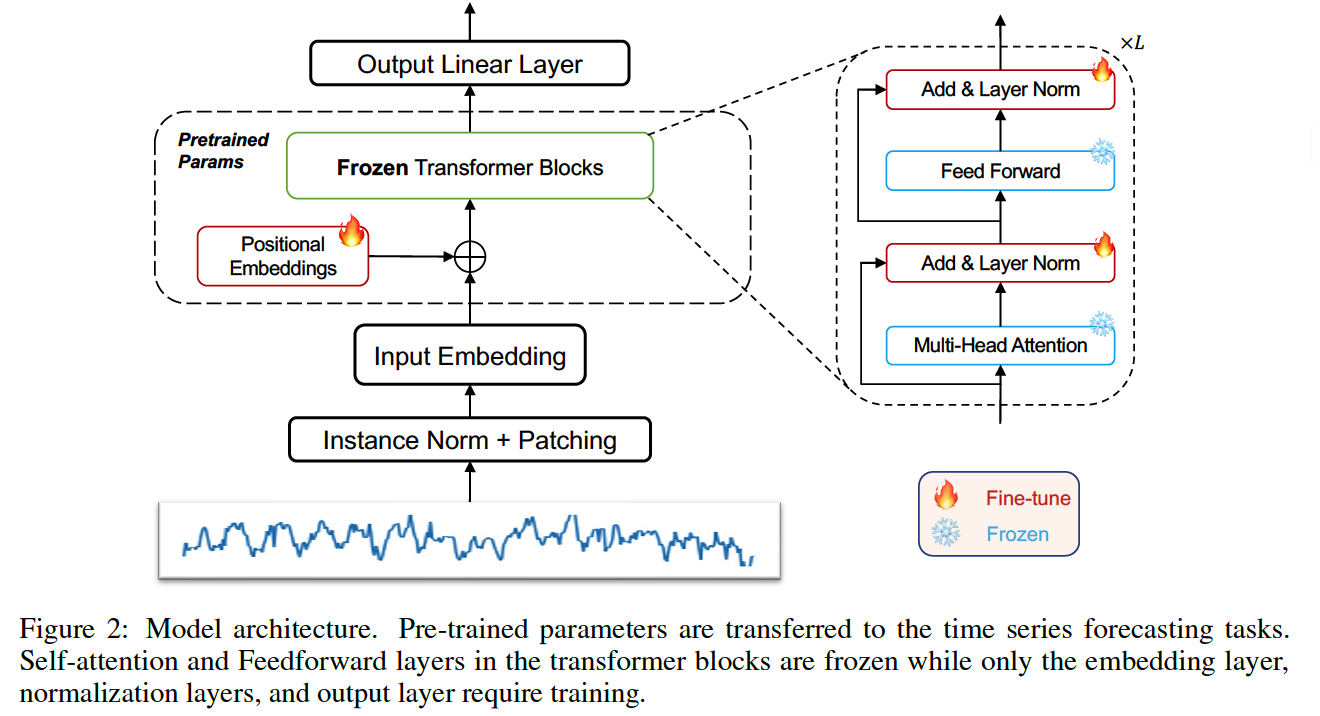
Frozen Pretrained Transformer (FPT)
- refrain from altering the self-attention & FFNN of residual blocks in pretrained NLP/CV model
1. Introduction
Advantage of foundation model
- provide a unified framework for handling diverse tasks
- ( \(\leftrightarrow\) each task requires a specifically designed algorithm )
Problem in TS: lack of large data
Solution: leverage pre-trained language model
- provide a unified framework
- self-attention modules in the pre-trained transformer acquire the ability to perform certain non-data-dependent operations through training
2. Related Works
(1) In-modality Transfer Learning
Because of insufficient training sample, little research on pre-trained models
(2) Cross-modality Transfer Learning
VLMo (2021)
- Stagewise pretraining strategy
- Utilize frozen attention blocks pretrained by IMAGE
- Transfer to LNAGUAGE
Voice2series (2021)
- Leverage a pretrained speech processing model for TS classification
3. Methodology
( Focuse on GPT 2, but also experiment on BERT & BEiT )
4. Experiments
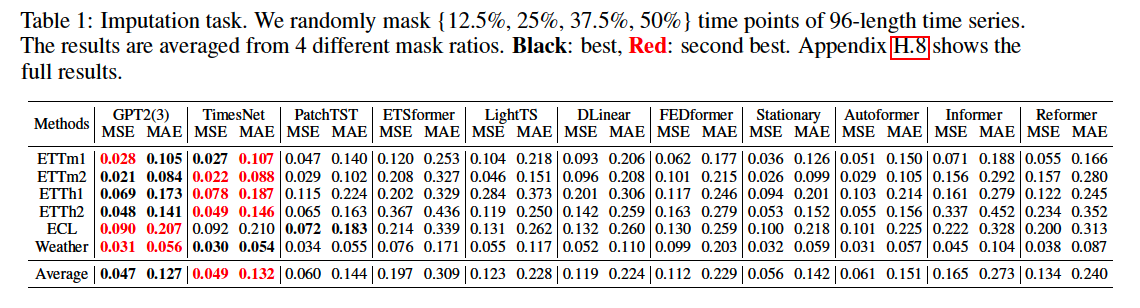
(1) Imputation
Following TimesNet, use different random mask ratios (12.5, 25, 37.5, 50% )
<br.
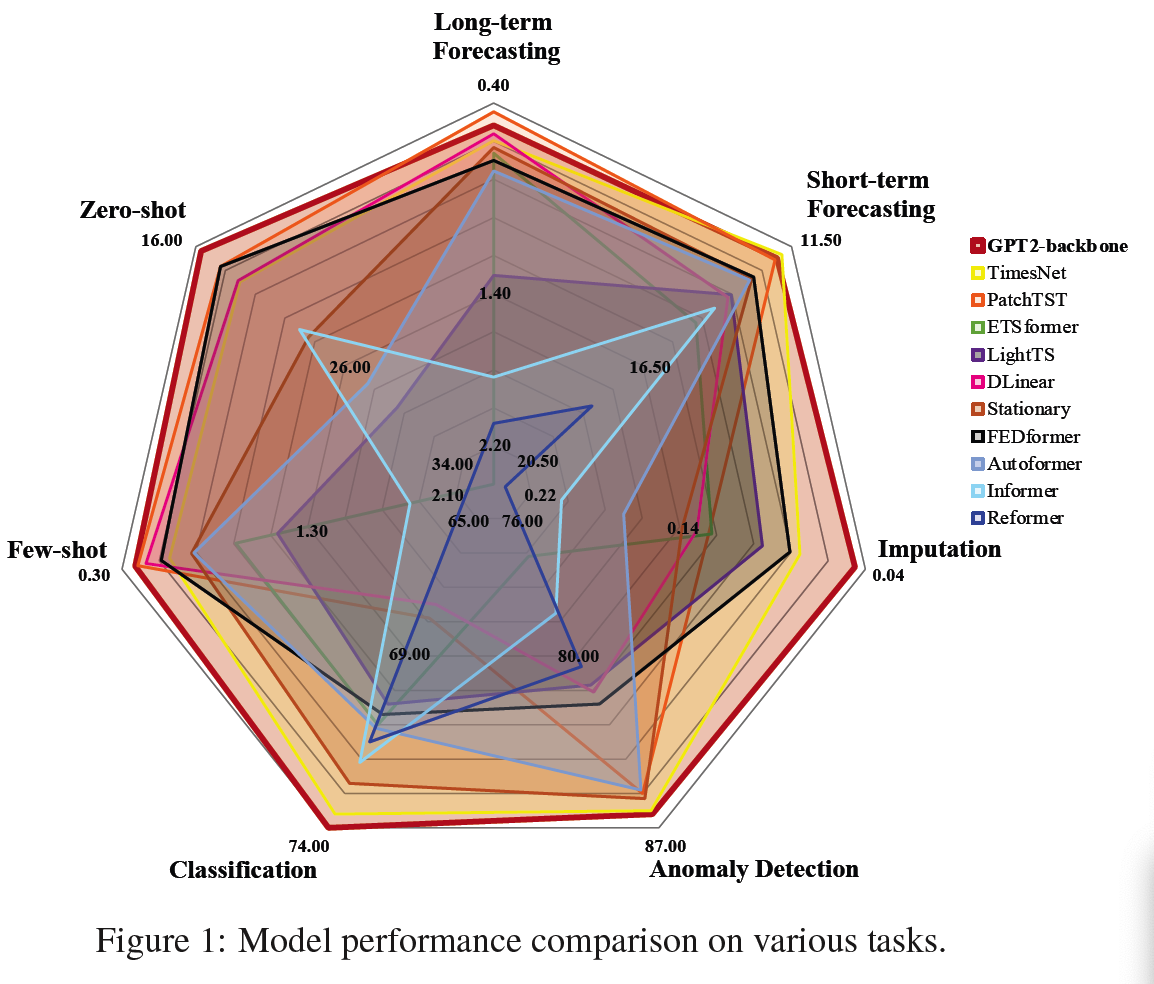
(2) Classification
10 multivariate UEA datasets
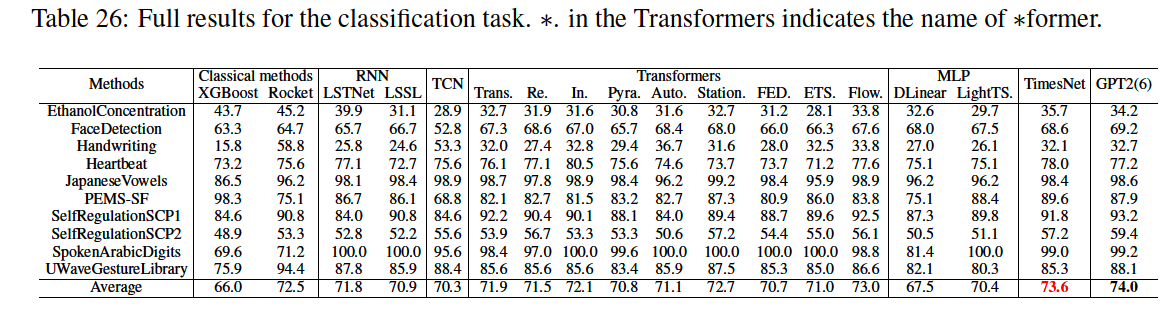
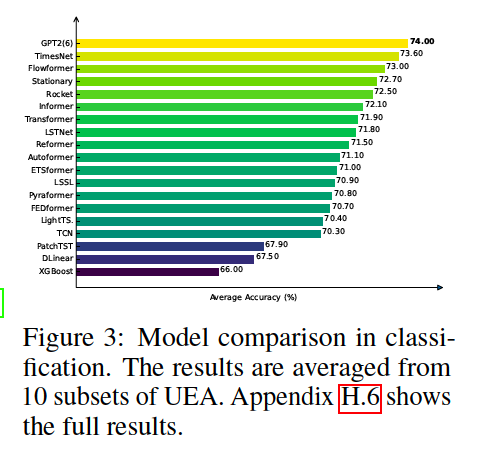
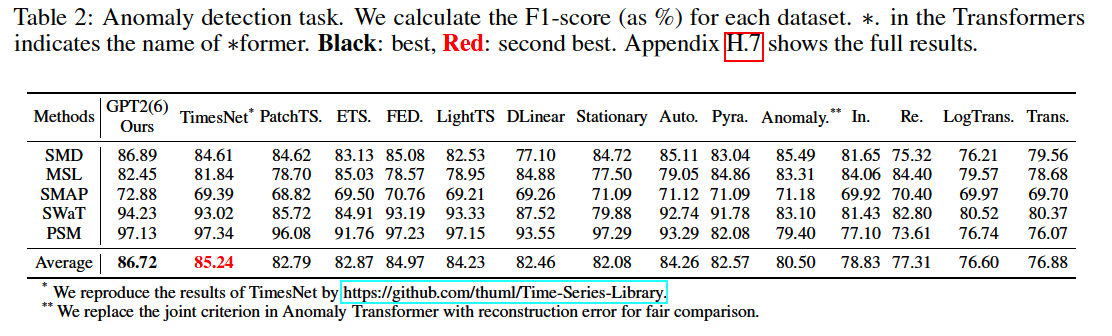
(3) Anomaly Detection
5 commonly used datasets
- SMD, MSL, SMAP, SwaT, PSM
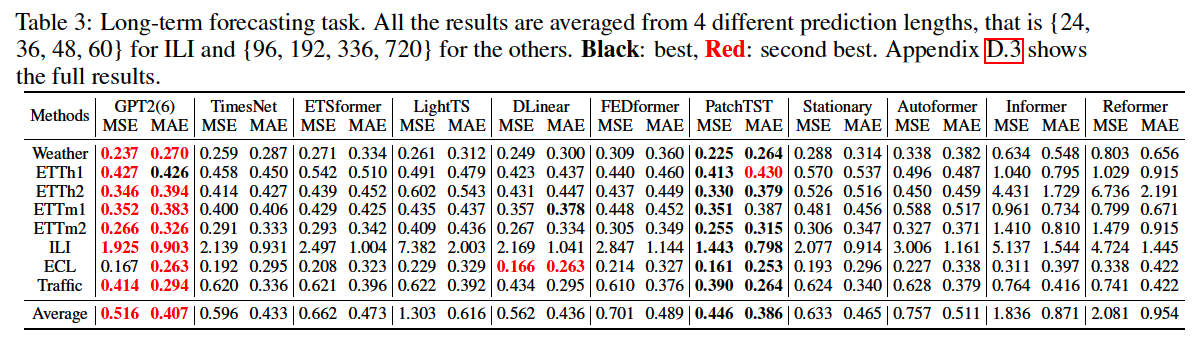
(4) Long-term Forecasting
(5) Short-term Forecasting
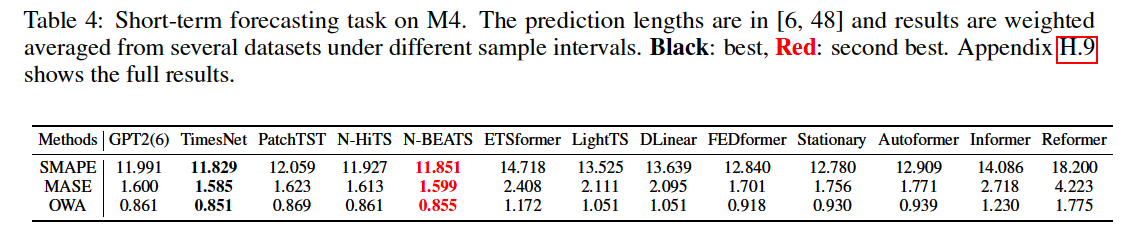
(6) Few-shot Forecasting
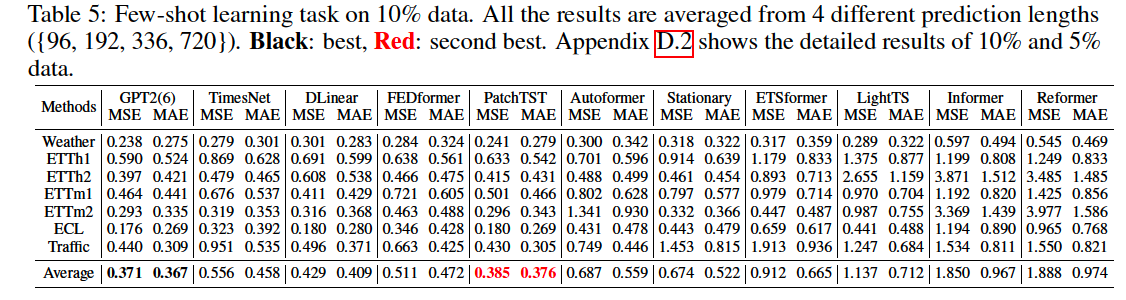
(7) Zero-shot forecasting
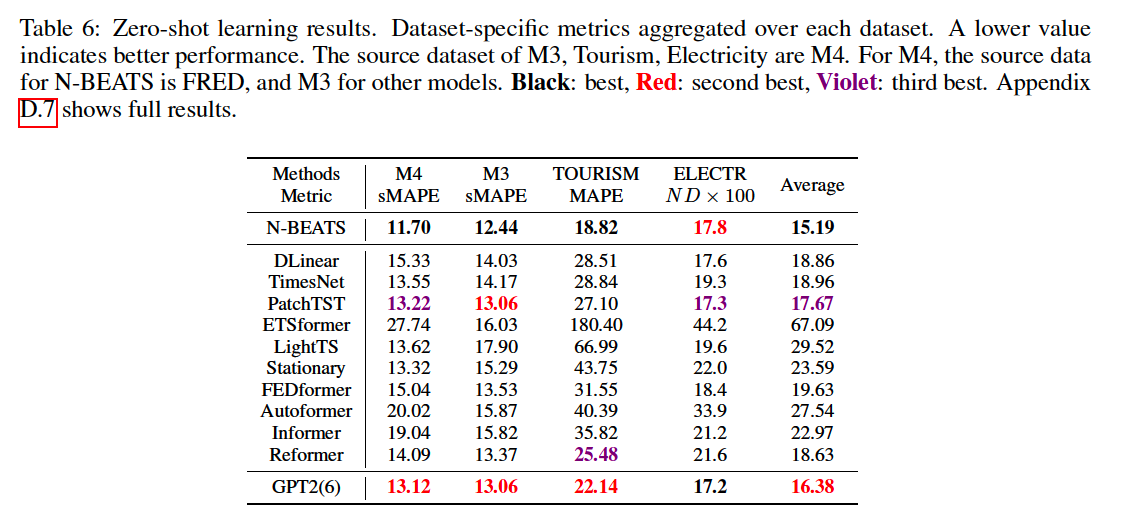
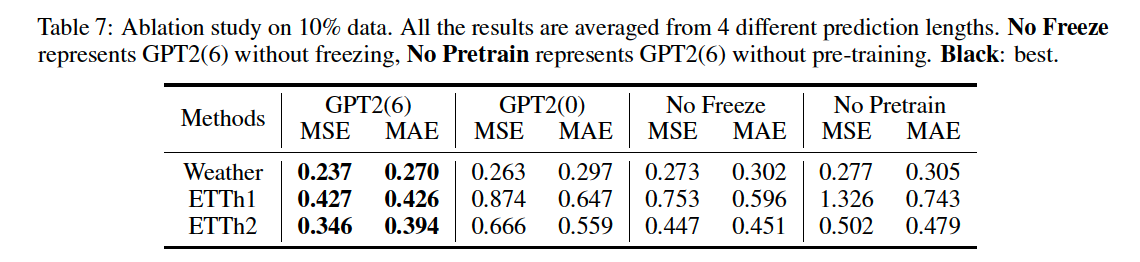
5. Ablation Studies
Several variants
- GPT2(0) FPT
- GPT2(6) w/o freezing
- GPT2(6) w/o pr-training
6. GPT2 vs. BERT vs. BEiT

7. Efficiency Analysis