[Paper Review] 11. Conditional Image Synthesis with ACGANs
Contents
- Abstract
- Introduction
- Background
- AC-GANs
- Results
0. Abstract
construct a variant of GANs, employing label conditioning, that results in 128 \(\times\) 128 resolution image samples, exhibiting global coherence
2 new analysis for assessing the (1) discriminability and (2) diversity
demonstrate that high resolution samples provide class information not present in low resolution samples
1. Introduction
GANs can produce convincing image samples on datasets, with LOW variability and LOW resolution
However, GANs struggle to generate globally coherent, high resolution samples
- especially from datasets with HIGH variability
Show that adding more structure to GAN latent space ( + specialized cost function )
\(\rightarrow\) higher quality samples
Exhibit 128x128 pixel samples from all classes of ImageNet dataset
( with increased global coherence )

Higher resolution \(\neq\) resizing of low resolution samples
Introduce new metric for assessing variability
2. Background
notation :
- \(S\) : source ( Fake / Real )
- \(D,G\) : discriminator, generator
- generator : \(X_{\text {fake }}=G(z)\)
- minimize \(L=E\left[\log P\left(S=\text { fake } \mid X_{\text {fake }}\right)\right]\).
- discriminator : \(P(S \mid X)=D(X)\)
- maximize \(L=E\left[\log P\left(S=\text { real } \mid X_{\text {real }}\right)\right]+ E\left[\log P\left(S=\text { fake } \mid X_{\text {fake }}\right)\right]\).
variants of GAN ( adding side information )
-
[CGAN] supply both \(G\) & \(D\) with class labels
\(\rightarrow\) improve the quality of generated samples
-
task the discriminator with reconstructing side information
( by modifying the discriminator to contain an auxiliary decoder that outputs class label for training data )
Motivated by these…
introduce a model that combine both strategies for leveraging side information
- 1) class conditional
- 2) auxiliary decoder, that is tasked with reconstructing class labels
3. AC-GANs
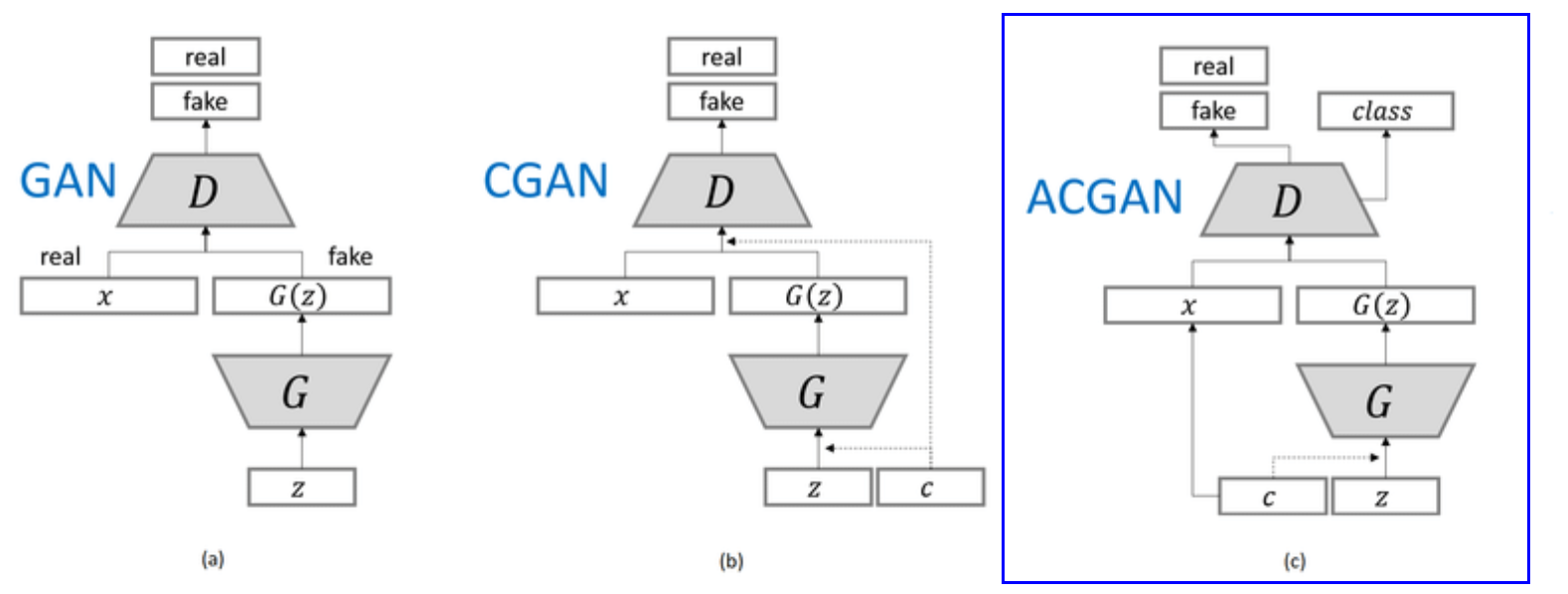
propose auxiliary classifier GAN ( = AC-GAN )
- every generated sample has …
- 1) a corresponding “class label”, \(c \sim p_c\)
- 2) noise, \(z\)
- \(G\) : \(X_{\text {fake }}=G(c, z)\)
- \(D\) : \(P(S \mid X), P(C \mid X)=D(X)\)
Loss Function
- \(L_{S}=E\left[\log P\left(S=\text { real } \mid X_{\text {real }}\right)\right]+ E\left[\log P\left(S=\text { fake } \mid X_{\text {fake }}\right)\right]\).
- \(L_{C}=E\left[\log P\left(C=c \mid X_{\text {real }}\right)\right]+E\left[\log P\left(C=c \mid X_{\text {fake }}\right)\right]\).
- goal of \(D\) : maximize \(L_{S}+L_{C}\)
- goal of \(G\) : maximize \(L_{C}-L_{S}\)
learn a representation for \(z\), that is INDEPENDENT of class label
creates 128 \(\times\) 128 samples from all 1000 ImageNet classes
structure of AC-GAN permits separating large datasets into subsets by class
& train G/D for each subset
-
all ImageNet experiments : ensemble of 100 AC-GANs
( each trained on 10-class split )
4. Results
train several AC-GAN models ( above )
- 100 class \(\times\) 10 models = 1,000 classes of ImageNet
architecture
- \(G\) : series of deconvolution ( \(z\) & \(c\) into image )
- \(D\) : deep CNN with Leaky ReLU
train 2 variants of the model architecture
- 1) generating \(128 \times 128\) spatial resolution
- 2) generating \(64 \times 64\) spatial resolution
evaluate the quality of image by..
- building several ad-hoc measures for image sample “discriminability” and “diversity”
4-1. Generating High Resolution Images Improves Discriminability
-
\(128 \times 128\) model > \(64 \times 64\) model
-
notice : NOT JUST NAIVE RESIZING
-
making ( 64 \(\times\) 64 ) image twice bigger \(\neq\) ( 128 \(\times\) 128 ) image
( = bilinear interpolation (X) )
( = not just blurry version )
\(\rightarrow\) not the true meaning of “HIGH resolution”
-
-
goal of image synthesis..
- 1) not simply to produce high resolution image
- 2) but also produce high resolution image “that are more discriminable” than low resolution images
Measure Discriminability
use pre-trained Inception network (2015)
\(\rightarrow\) report the fraction of samples, for which the Inception network assigned the correct label
( = calculate accuracy )

As spatial resolution is DECREASED, the accuracy also DECREASES
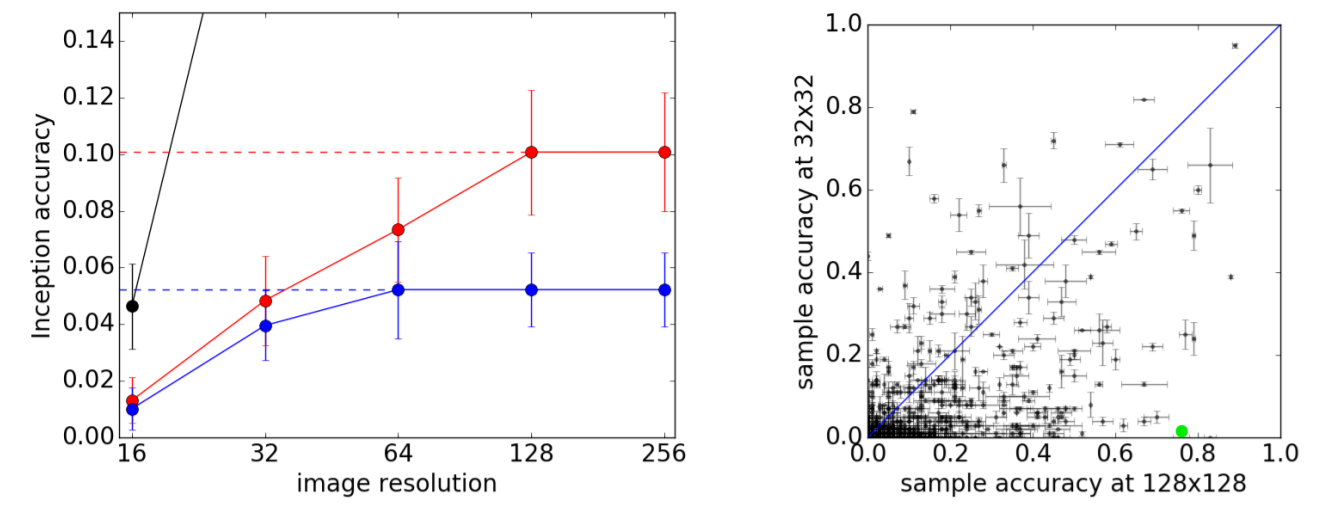
[LEFT]
line labels
- black : ImageNet training data ( 128 x 128 )
- red : ACGAN ( 128 x 128 )
- blue : ACGAN ( 64 x 64 )
result
- 128 x 128 resolution : 10.1% \(\pm\) 2.0% ( 기준 )
- 64 x 64 resolution : 7.0% \(\pm\) 2.0% ( -38% )
- 32 x 32 resolution : 5.0% \(\pm\) 2.0% ( - 50%)
[RIGHT]
- 84% of ImageNet classes have HIGHER ACCURACY at 128x128 than 32x32
Conclusion : synthesizing HIGHER resolution images, leads to INCREASED DISCRIMINABILITY
4-2. Measuring the Diversity of Generated Images
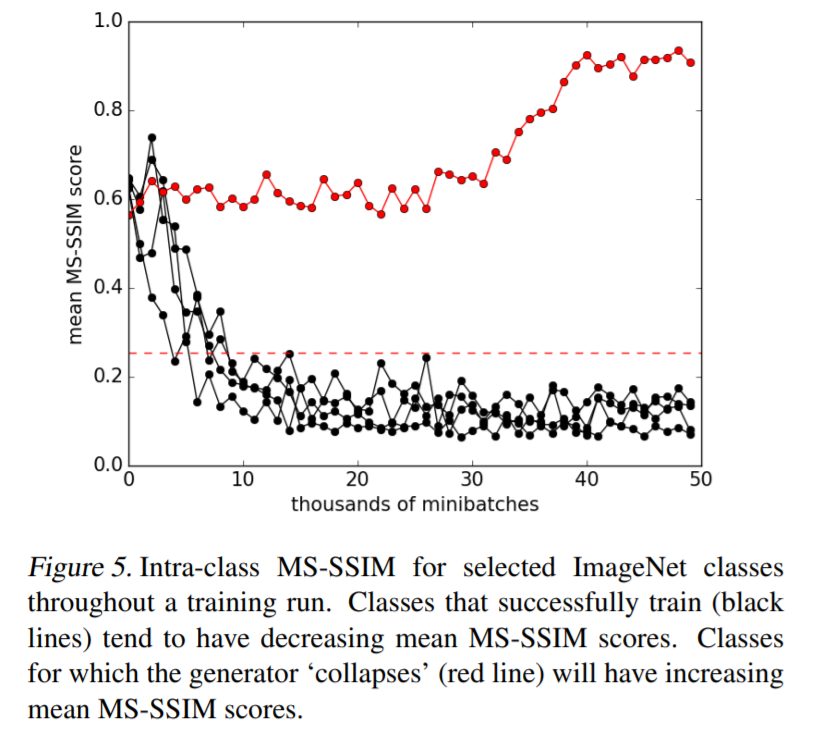
problem of mode collapse
- G making output of single prototype that maximally fools the D
\(\rightarrow\) Inception accuracy can not measure whether a model has collapsed!
Seek a complementary metric, to explicitly evaluate the intra-class perceptual diversity of samples, generated by the AC-GAN
MS-SSIM (Multi-Scale Structural Similarity)
- DISCOUNT aspects of an image, that are not important for HUMAN PERCEPTION
- value : 0.0~1.0
- higher : more similar ( = lower diversity )
- lower: less similar ( = higher diversity )
Experiment
- measure 100 randomly chosen pairs of images, within a given class

1,000 ImageNet training data…. contain variety of mean MS-SSIM scores
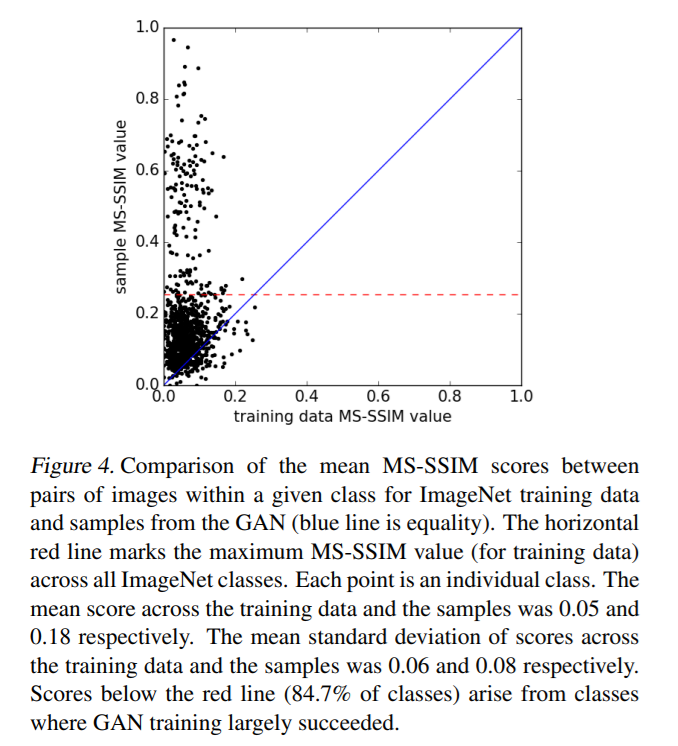
- 1,000 points ( = 1,000 classes )
- \(x\) axis : ImageNet training data
- mean : 0.05 , mean std of scores : 0.06
- \(y\) axis : samples from the GAN
- mean : 0.18 , mean std of scores : 0.08
- horizontal red line : maximum MS-SSIM value for training data
- number of points, below the red line : 84.7% ( 847 classes )
4-3. Generated Images are both Diverse & Discriminable
until now… have dealt with quantitative metrics demonstrating
- 1) diversity ( via MS-SSIM )
- 2) discriminability ( via accuracy )
how do these 2 interact??
Joint distn of (1) Inception accuracies and (2) MS-SSIM scores, across all classes
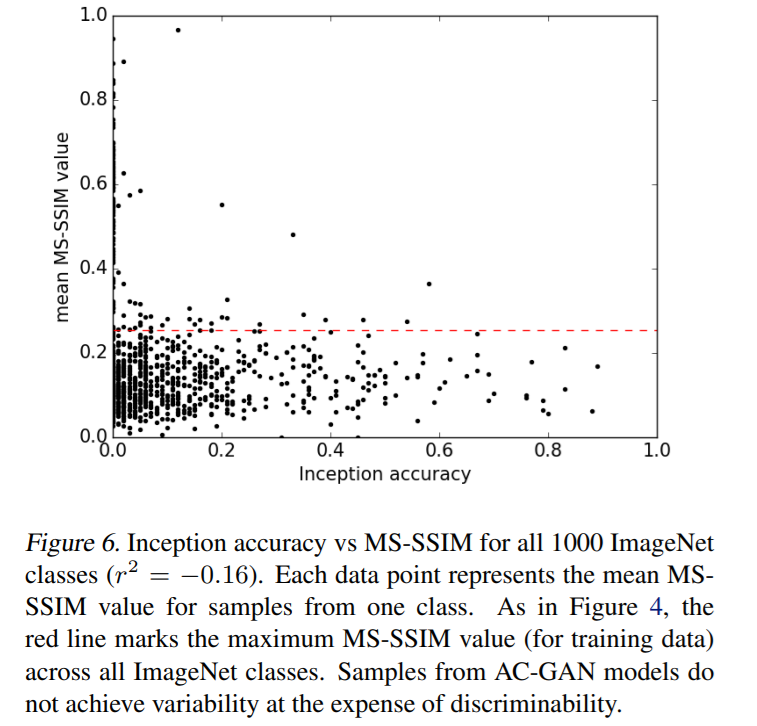
-
result : anti-correlated ( \(r^2 = -0.16\) )
that is, diversity and discriminability is positively correlated
-
74% of classes with LOW diversity ( MS-SSIM \(\geq\) 0.25 )
\(\rightarrow\) LOW discriminability ( Inception accuracy \(\leq\) 1% )
-
78% of classes with HIGH diversity ( MS-SSIM \(\leq\) 0.25 )
\(\rightarrow\) HIGH discriminability ( Inception accuracy \(>\) 1% )
-
Previous hypothesis of GAN :
- achieve HIGH sample quality at the expense of variability
\(\rightarrow\) stands in contrast!
4-4. Comparison to Previous Results

4-5. Searching for Signatures of Overfitting
overfitting = memorizing training data
how to identify…?
-
1) identify the NEAREST NEIGHBORS of image samples ( metric : L1 distance )

-
nearest neighbors DO NOT resemble the corresponding samples
( evidence that AC-GAN is NOT MERELY MEMORIZING! )
-
-
2-1) explore that model’s LATENT SPACE by INTERPOLATION

- no discrete transitions ( or holes ) in latent space
-
2-2) exploit the structure of the model
- AC-GAN : factorize representation into “class info” & “class-independent” latent \(z\)
- method
- sampling the AC-GAN with “\(z\) fixed”, but “altering class label”

- although class changes for each column, elements of global structure are preserved
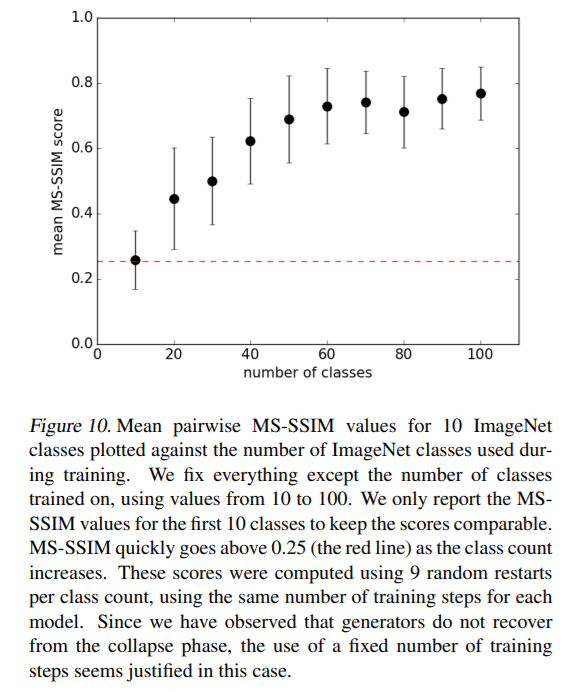
4-6. Measuring the Effect of Class Splits on Image Sample Quality
-
1,000 classes = 10 classes x 100 models
-
benefit of cutting down the diversity of classes
-
result
- training a fixed model on more classes \(\rightarrow\) harms the model’s ability to produce compelling samples
- BUT, with split size=1 …. unable to converge reliably…