
Chapter 1. Introduction to Geometric Deep Learning
( 참고 : https://www.youtube.com/watch?v=JtDgmmQ60x8&list=PLGMXrbDNfqTzqxB1IGgimuhtfAhGd8lHF )
1) Computational Graph
Input Graph는, 아래와 같이 computational graph로 변형해서 나타낼 수 있다.
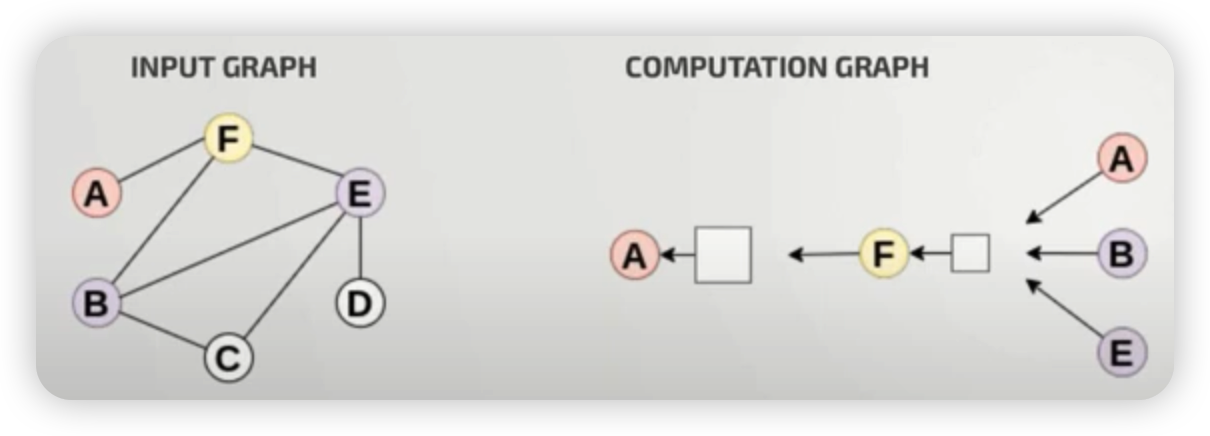
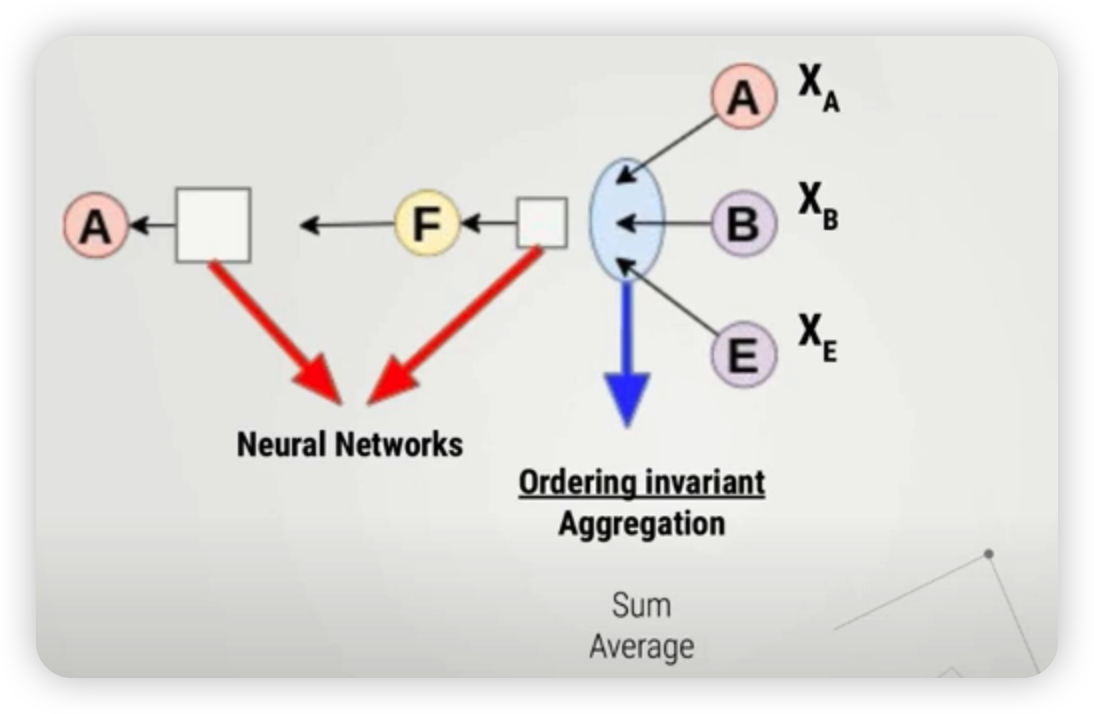
위처럼 나타낸 computational graph는,
- (1) order invariant aggregation function을 통해 메세지를 취합하고,
- (2) NN로 모델링된 함수를 통과하여 hidden layer를 생성한다.
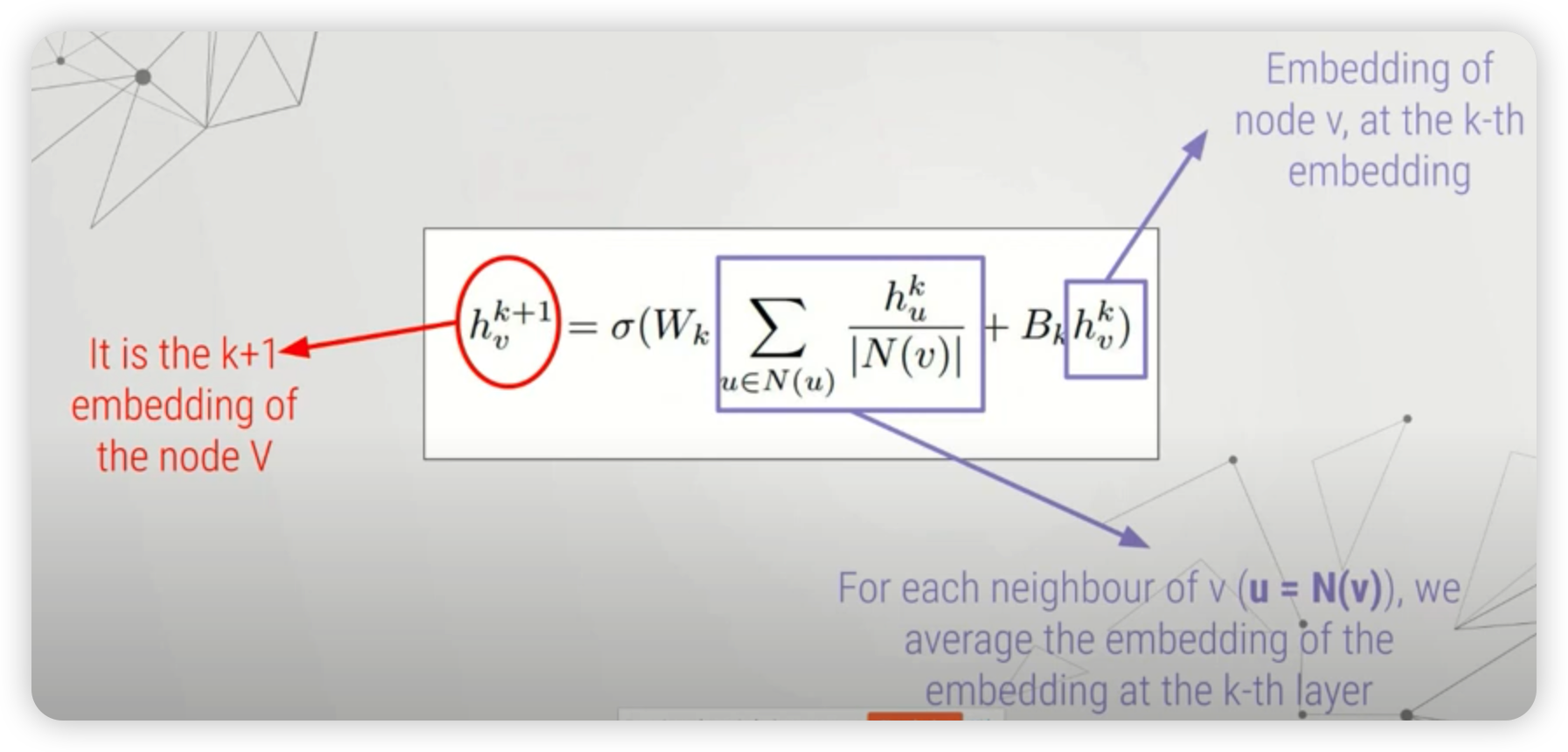
특정 노드 \(v\)의 feature vector가 들어가서, 최종 hidden representation까지 생성되는 과정을 수식으로 나타내면 아래와 같다 ( 사용한 layer의 개수 : \(K\) 개 )
\(\begin{aligned} H_{v}^{0} &=X_{v} \\ h_{v}^{k+1} &=\sigma\left(W_{k} \sum_{u \in N(u)} \frac{h_{u}^{k}}{ \mid N(v) \mid }+B_{k} h_{v}^{k}\right) \\ Z_{v} &=h_{v}^{K} \end{aligned}\).
위 식의 가운데 부분 ( node의 hidden representaiton이 업데이트 되는 과정 )을 풀어서 해석하면, 아래와 같다.
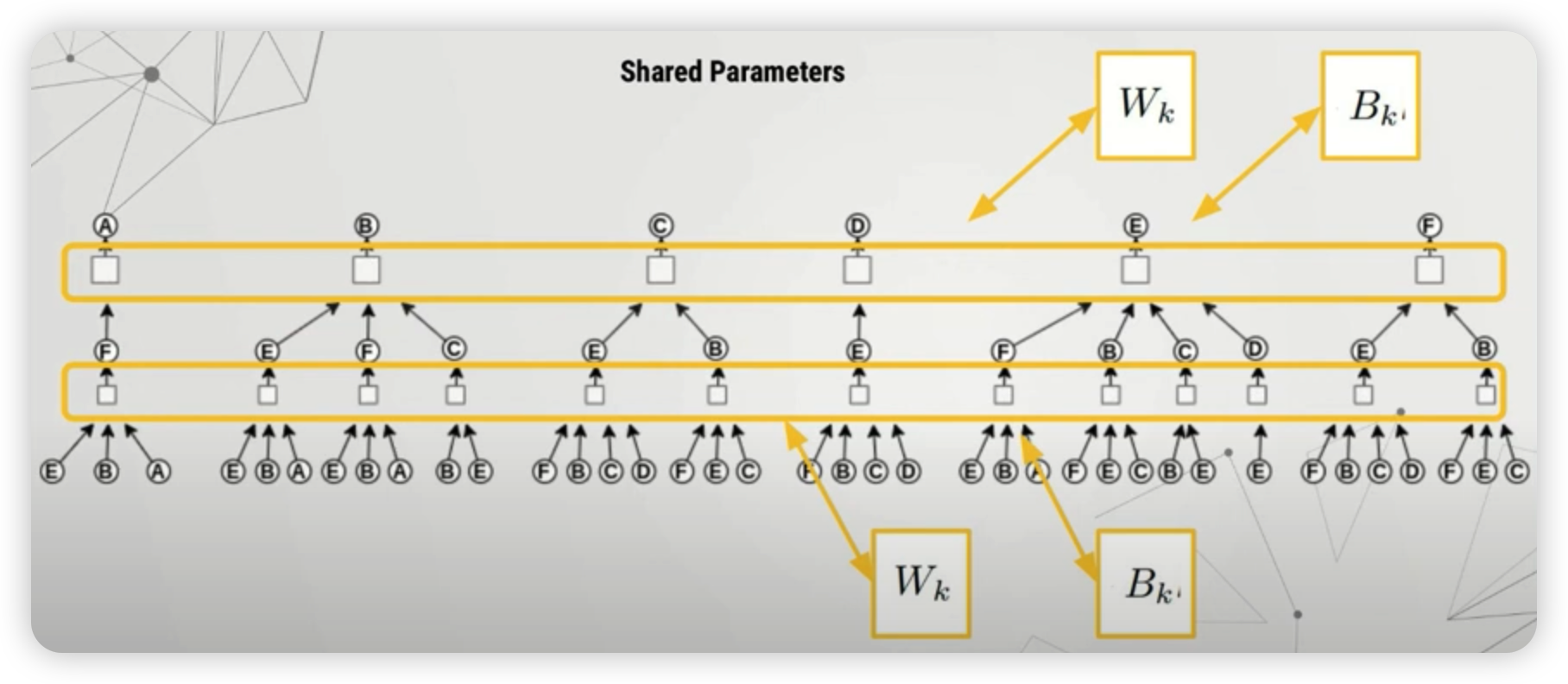
참고로, 이때 사용하는 NN의 파라미터들은, 특정 노드에 의존하지 않고, 전부 공통된 파라미터 (shared parameter)를 사용한다.
2) Graph SAGE
위에서, 이웃노드들의 메세지를 취합하는데에는 여러 방법들이 있을 수 있다.
이를 일반화(generalize)한 것이 Graph SAGE라고 보면 된다.
\(h_{v}^{k+1}=\sigma\left(\left[W_{k} \cdot A G G\left(\left\{h_{u}^{k-1}, \forall u \in N(v)\right\}\right), B_{k} h_{v}^{k}\right]\right)\).
- ex) mean : \(h_{v}^{k+1} =\sigma\left(W_{k} \sum_{u \in N(u)} \frac{h_{u}^{k}}{ \mid N(v) \mid }+B_{k} h_{v}^{k}\right)\)
위 식에서 AGG ( aggregate )을 하는데에는,
- pooling, mean, add, LSTM 등 다양한 방법이 사용될 수 있다.
3) Import Packages
import torch_geometric
from torch_geometric.datasets import Planetoid
import os.path as osp
import torch
import torch.nn.functional as F
4) Load Dataset
dataset = Planetoid(root="tutorial1",name= "Cora")
tutorial1경로 하에, Planetoid 데이터셋 내의 “Cora”데이터 다운로드
Data의 특징들 확인하기
- 그래프의 개수 : 1
- 노드의 레이블 종류 (카테고리) : 7
- 노드 피쳐의 차원 수 : 1433
- 엣지 피쳐의 차원 수 : x
print(dataset)
print("number of graphs:\t\t",len(dataset)) # 1
print("number of classes:\t\t",dataset.num_classes) # 7
print("number of node features:\t",dataset.num_node_features) # 1433
print("number of edge features:\t",dataset.num_edge_features) # 0
Data의 각종 정보를 확인할 수 있다.
print(dataset.data)
Data(x=[2708, 1433], edge_index=[2, 10556], y=[2708], train_mask=[2708], val_mask=[2708], test_mask=[2708])
- edge index의 크기 ( 2 x 10556 )
- mask의 크기 : 전부 ( 2708 )… binary 값이다
- train mask
- val mask
- test mask
-
node feature의 크기 ( 2708 x 1433 )
- node label의 크기 ( 2708 )
노드의 개수가 2,708개, edge의 개수가 10,556개임을 알 수 있다
print(dataset.data.edge_index)
print(dataset.data.train_mask)
print(dataset.data.x)
print(dataset.data.y)
그 중, 첫 번째 그래프 ( 하나의 그래프밖에 없긴 함 ) 가져오기
data = dataset[0]
5) Modeling
- 하나의 layer로 구성된 GNN을 생성한다
- 사용하는 layer :
SAGEConv( GraphSAGE layer )- arg[0] : input 차원
- arg[1] : output 차원
- aggr : 메세지를 aggregate하는 방식 ( max, mean, add 등 )
- 사용하는 layer :
SAGEConv레이어를 거친 뒤, log-softmax를 통해 log 확률값으로 반환한다.
from torch_geometric.nn import SAGEConv
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv = SAGEConv(dataset.num_features,
dataset.num_classes,
aggr="max")
def forward(self):
x = self.conv(data.x, data.edge_index)
return F.log_softmax(x, dim=1)
모델 & 옵티마이저 생성
device = torch.device('cuda' if torch.cuda.is_available() and use_cuda_if_available else 'cpu')
model = Net().to(device)
data = data.to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)
6) 모델 학습
train 함수
- (1) 학습 mode로
- (2) optimizer 그래디언트 초기화
- (3) loss 계산 & back-prop
- 사용하는 loss : nll_loss ( negative log likelihood )
- arg[0] : 모델의 예측값 x train mask
- arg[1] : 실제 정답값 x train mask
- 사용하는 loss : nll_loss ( negative log likelihood )
def train():
model.train()
optimizer.zero_grad()
F.nll_loss(model()[data.train_mask], data.y[data.train_mask]).backward()
optimizer.step()
7) 모델 평가
test 함수
def test():
model.eval()
logits, accs = model(), []
for _, mask in data('train_mask', 'val_mask', 'test_mask'):
pred = logits[mask].max(1)[1]
acc = pred.eq(data.y[mask]).sum().item() / mask.sum().item()
accs.append(acc)
return accs
8) 모델을 학습하고 평가하자!
- epoch : 100
best_val_acc = test_acc = 0
for epoch in range(1,100):
train()
_, val_acc, tmp_test_acc = test()
if val_acc > best_val_acc:
best_val_acc = val_acc
test_acc = tmp_test_acc
log = 'Epoch: {:03d}, Val: {:.4f}, Test: {:.4f}'
if epoch % 10 == 0:
print(log.format(epoch, best_val_acc, test_acc))