
ML Flow
(1) Introduction
MLOps에서는 전체적인 ML Life Cycle을 관리한다.
이때 도움이 되는 오픈소스 툴 중 하나가 바로 MLflow 이다.
ML Flow에는 크게 아래와 같이 3개의 기능이 있다.
- ML Flow Tracking
- 실험 결과를 tracking 한다
- 파라미터 & 실험결과를 비교하기에 용이
- ML Flow Projects
- ML 코드의 재현성 확보를 위해 포장하는 과정
- ML Flow Models
- ML 모델 관리/배포/서빙/추론 등
(2) ML Flow 설치하기
ML Flow를 설치하기에 앞서서, 가상환경을 만들고 그 위에서 작업해줘야한다.
# 가상 환경을 만들고 ( 이름 : myenv )
$ virtualenv myenv
# 가상 환경을 활성화한다.
$ source myenv/bin/activate
접속한 가상환경에서 mlflow를 설치해준다.
$ pip3 install mlflow
예제를 코드를 클론하고, examples 폴더로 이동한다.
$ git clone https://github.com/mlflow/mlflow
$ cd mlflow/examples
(3-1) ML Flow Tracking
이를 통해 트래킹하는 정보들은 아래와 같다.
- 코드 버전
- 실행 시작/종료 시간
- 소스 ( 소스 코드의 이름 :
xxx.py) - 메트릭 ( 모델의 성능 )
- key : value 형식의 메트릭
- 이 메트릭을 다양한 형태의 파일로 저장할 수 있다.
예제 코드 )
log_param: 파라미터의 로그를 기록한다log_metric: 메트릭의 ~log_artifacts: 아티팩트의 ~
# mlflow_tracking.py
import os
from random import random, randint
from mlflow import log_metric, log_param, log_artifacts
if __name__ == "__main__":
print("Running mlflow_tracking.py")
#-----------------------------------------------#
log_param("param1", randint(0, 50))
log_param("param2", randint(5, 100))
#-----------------------------------------------#
log_metric("metric1", random())
log_metric("metric2", random()+1)
log_metric("metric3", random()+2)
#-----------------------------------------------#
if not os.path.exists("outputs"):
os.makedirs("outputs")
with open("outputs/test.txt", "w") as f:
f.write("hello world!")
log_artifacts("outputs")
위와 같이 예제 코드를 작성한 뒤, 실행해준다
$ python3 mlflow_tracking.py
트래킹 과정을 웹 UI로 확인해보자.
$ mlflow ui
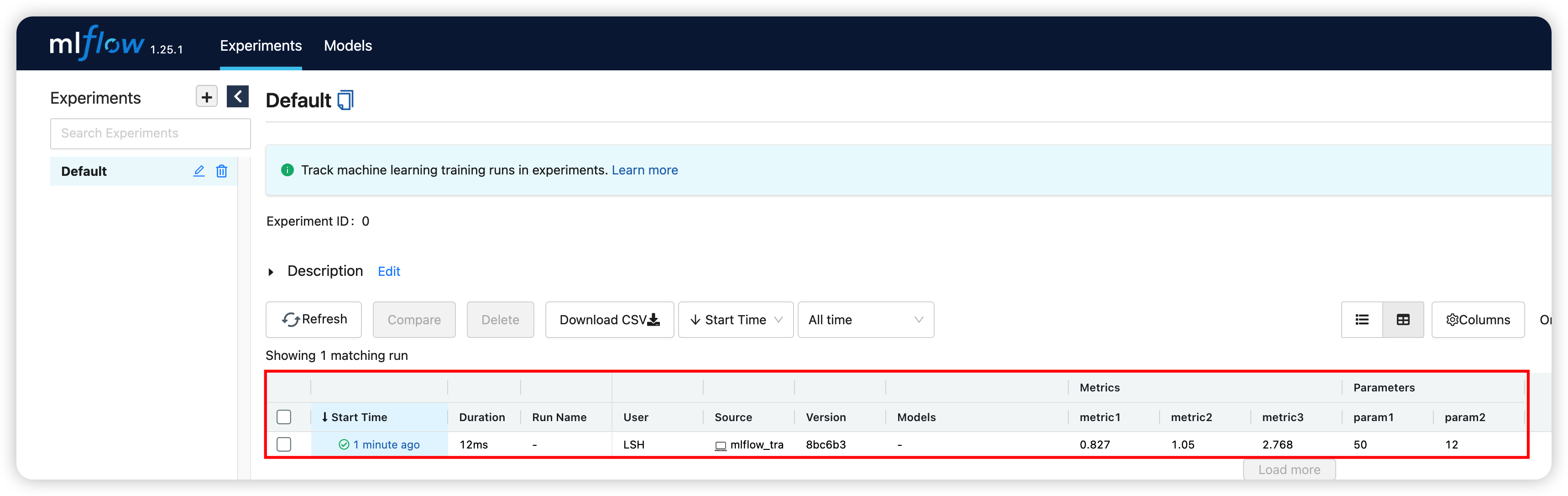
(3-2) ML Flow Projects
프로젝트 실행 명령어 : mlflow run
1) github 내의 프로젝트 실행
- conda 사용 X
$ mlflow run --no-conda git@github.com:mlflow/mlflow-example.git -P alpha=5
- conda 사용 O
$ mlflow run git@github.com:mlflow/mlflow-example.git -P alpha=5
tutorial을 실행해보자
$ mlflow run tutorial -P alpha=0.5
2) 특정 폴더 내의 프로젝트 실행
( 위에서 git clone했던 예시 그대로 사용 )
사용할 프로젝트 예시
sklearn_logistic_regression
├── MLproject
├── conda.yaml
└── train.py
하나의 ML Project는, 아래와 같이 3가지로 구성된다.
- (1) MLProject
- 이 파일의 존재를 통해, 해당 폴더가 ML Project임을 알 수 있음
- (2) conda.yaml
- (3) train.py
(a) MLProject
name: tutorial
conda_env: conda.yaml
entry_points:
main:
parameters:
alpha: {type: float, default: 0.5}
l1_ratio: {type: float, default: 0.1}
command: "python train.py {alpha} {l1_ratio}"
name: 프로젝트명conda_env: 실행할 conda 환경에 대한 정보값들이 담긴 yaml 파일entry_points:-e옵션으로 지정할 수 있는 값들- 위의 ex)
alpha,l1_ratio
- 위의 ex)
(b) conda.yaml
name: tutorial
channels:
- defaults
dependencies:
- numpy>=1.14.3
- pandas>=1.0.0
- scikit-learn=0.19.1
- pip
- pip:
- mlflow
- 실행할 conda 환경의 이름, 및 필요한 패키지 정보들이 담겨 있다.
(c) train.py
import os
import warnings
import sys
import pandas as pd
import numpy as np
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
from sklearn.model_selection import train_test_split
from sklearn.linear_model import ElasticNet
import mlflow
import mlflow.sklearn
def eval_metrics(actual, pred):
rmse = np.sqrt(mean_squared_error(actual, pred))
mae = mean_absolute_error(actual, pred)
r2 = r2_score(actual, pred)
return rmse, mae, r2
if __name__ == "__main__":
warnings.filterwarnings("ignore")
np.random.seed(40)
# (1) data 불러오기
wine_path = os.path.join(os.path.dirname(os.path.abspath(__file__))
data = pd.read_csv(wine_path)
# (2) 데이터 나누기
train, test = train_test_split(data)
# (3) 독립/종속변수 설정
train_x = train.drop(["quality"], axis=1)
test_x = test.drop(["quality"], axis=1)
train_y = train[["quality"]]
test_y = test[["quality"]]
# (4) hyperparameter 값을 불러오기
alpha = float(sys.argv[1]) if len(sys.argv) > 1 else 0.5
l1_ratio = float(sys.argv[2]) if len(sys.argv) > 2 else 0.5
#======================================================================#
with mlflow.start_run():
# (1) 모델 생성 & 학습
lr = ElasticNet(alpha=alpha, l1_ratio=l1_ratio, random_state=42)
lr.fit(train_x, train_y)
# (2) 예측 결과
predicted_qualities = lr.predict(test_x)
# (3) 예측 성능
(rmse, mae, r2) = eval_metrics(test_y, predicted_qualities)
print("Elasticnet model (alpha=%f, l1_ratio=%f):" % (alpha, l1_ratio))
print(" RMSE: %s" % rmse)
print(" MAE: %s" % mae)
print(" R2: %s" % r2)
# (4) 로깅 찍기
#-------------------------------------------------------#
mlflow.log_param("alpha", alpha)
mlflow.log_param("l1_ratio", l1_ratio)
#-------------------------------------------------------#
mlflow.log_metric("rmse", rmse)
mlflow.log_metric("r2", r2)
mlflow.log_metric("mae", mae)
#-------------------------------------------------------#
mlflow.sklearn.log_model(lr, "model")
#-------------------------------------------------------#
#======================================================================#
프로젝트 실행하기
$ mlflow run -e main sklearn_elastic_wine -P alpha=0.1 -P l1_ratio=0.5
3) Docker 통해 프로젝트 실행
key point : conda 환경 대신, docker 컨테이너 환경으로 실행해보자!
( 위에서 git clone했던 예시 그대로 사용 )
사용할 프로젝트 예시
docker
├── Dockerfile
├── MLproject
├── README.rst
├── kubernetes_config.json
├── kubernetes_job_template.yaml
├── train.py
└── wine-quality.csv
위의 conda를 활용한 2) 특정 폴더 내의 프로젝트 와의 차이점을 위해,
아래의 2가지 파일에 주목해보자.
- (1) Dockerfile
- (2) MLproject
(a) Dockerfile
- Docker file에 대해 더 알고싶다면…
- https://seunghan96.github.io/docker/docker4a/
- 쉽게 말해, “컨테이너를 빌드하기 위한 도커 이미지를 생성하는 파일”이다.
FROM python:3.8.8-slim-buster
RUN pip install mlflow>=1.0 \
&& pip install numpy \
&& pip install pandas \
&& pip install scikit-learn
(b) MLproject
# MLproject
name: docker-example
docker_env:
image: mlflow-docker-example
entry_points:
main:
parameters:
alpha: float
l1_ratio: {type: float, default: 0.1}
command: "python train.py --alpha {alpha} --l1-ratio {l1_ratio}"
차이점
-
conda 환경 :
conda_env: conda.yaml -
docker 환경 :
docker_env: image: mlflow-docker-example
프로젝트를 실행하기 전에, 도커 이미지를 위의 Dockerfile을 이용하여 생성해야 한다.
- 명령어 :
docker build -t mlflow-docker-example -f Dockerfile . - 생성된 도커 이미지 이름 :
mlflow-docker-example
그런 뒤, 앞선 방법과 마찬가지로 mlflow run 를 사용하여 프로젝트를 실행한다.
$ mlflow run docker -P alpha=0.5
4) kubernetes 통해 프로젝트 실행
key point : kubernetes 를 사용하여 프로젝트를 실행해보자.
--backend&--backend-config지정을 통해, kubernetes를 통해 실행가능!
$ mlflow run <project_uri> \
--backend kubernetes \
--backend-config kubernetes_config.json
위 코드를 통해, 아래와 같은 3가지 step이 순차적으로 이루어진다.
- 도커 이미지 빌드
- 도커 컨테이너 레지스트리에 위에서 생성된 도커 이미지 푸시
- 위 이미지를 쿠버네티스에서 Job으로 배포
그러기 위해선, 도커 이미지 레지스트리 & kubernetse 접속 context가 필요하다.
이를 위해 필요한 파일들이
- (1)
kubernetes_config.json - (2)
kubernetes_job_template.yaml
이다
(3-3) ML Flow Models
모델을 학습 하고, 서빙 하자!
- 서빙 :
mlflow pyfunc serve
(a) 모델 학습
$ python3 sklearn_logistic_regression/train.py
위에서 실행한 train.py 함수를 보면,
# train.py
import numpy as np
from sklearn.linear_model import LogisticRegression
import mlflow
import mlflow.sklearn
if __name__ == "__main__":
X = np.array([-2, -1, 0, 1, 2, 1]).reshape(-1, 1)
y = np.array([0, 0, 1, 1, 1, 0])
lr = LogisticRegression()
lr.fit(X, y)
score = lr.score(X, y)
print("Score: %s" % score)
mlflow.log_metric("score", score)
mlflow.sklearn.log_model(lr, "model")
print("Model saved in run %s" % mlflow.active_run().info.run_uuid)
-
mlflow.log_metric&mlflow.sklearn.log_model를 통해 로깅을 하고, -
mlflow.active_run().info.run_uuid를 통해 RUN ID 를 알 수 있다.이 아이디를 사용하여 서빙을 하면 아래와 같다.
(b) 모델 서빙
$ mlflow pyfunc serve -r <RUN_ID> -m model --no-conda --port 1234
참고
-
https://zzsza.github.io/mlops/2019/01/16/mlflow-basic/
-
https://dailyheumsi.tistory.com/263#github%EC%97%90-%EC%9E%88%EB%8A%94-%ED%94%84%EB%A1%9C%EC%A0%9D%ED%8A%B8-%EC%8B%A4%ED%96%89%ED%95%98%EA%B8%B0
-
https://github.com/mlflow/mlflow-example/blob/master/train.py