
DATSING : Data Augmented Time Series Forecasting with Adversarial Domain Adaptation (2020, 1)
Contents
-
Abstract
-
Introduction
-
Related Works
- Time Series Forecasting
- Domain Adaptation
-
Methodology
-
Notation
- Pre-training with general domain samples
- Similarity-based data augmentation
- Domain Adversarial Transfer Learning
-
0. Abstract
Transfer Learning (TL) in univariate TSF : challenging
\(\rightarrow\) propose “DATSING”
DATSING
-
Data Augmented Time Series Forecast ING with adversarial domain adaptation
-
Transfer learning framework
-
leverages “cross-domain” TS representation,
to augment target domain forecasting
-
GOAL : transfer “domain-INVARIANT” feature representation, from a “pre-trained stacked deep residual network” to “target domains”
-
2-phase
- step 1) cluster similar mixed domains
- step 2) perform “fine-tuning” with domain adversarial regularization
1. Introduction
DL in TSF : prone to overfit
\(\rightarrow\) need for effective transfer learning strategies
( especially when ‘target data’ is scarce )
2 challenges in Transfer Learning
- 1) dynamically changing patterns
- 2) data scarcity
DATSING
-
when target domain only has scarce data
-
step 1) data augmentation
- obtain a cluster of similar data from general domain
-
step 2) fine-tune
- fine tune the pre-trained model for target domain
-
etc) adversarial learning-based DA
\(\rightarrow\) address “negative transfer” issue
2. Related Works
(1) Time Series Forecasting
1) Deep AR
- likelihood models in RNN
- for probabilistic forecasting
2) Deep State Space
- state space model (SSM) + RNN
3) A hybrid method of exponential smoothing and recurrent neural networks for time series forecasting
- use residual LSTM, to enhance traditional Holt-Winters
4) N-BEATS
- pass~
(2) Domain Adaptation
Domain Adaptation (DA)
- SAME task
- DIFFERENT domain
Adversarial training
- popular strategy for DA
- jointly learns..
- 1) domain INVARIANT representation
- 2) domain SPECIFIC label predictors
- applicable in both supervised/unsupervised settings
Few DA studies in TSF…
- ex 1) fine-tuning CNN with layer freezing
- ex 2) transfer trend factor / seasonal index / normalization statistics to new datasets
2 key points of DATSING
- 1) practical method to perform “data augmentation”
- 2) effective regularization that prevents negative transfer, caused by OOD
3. Methodology
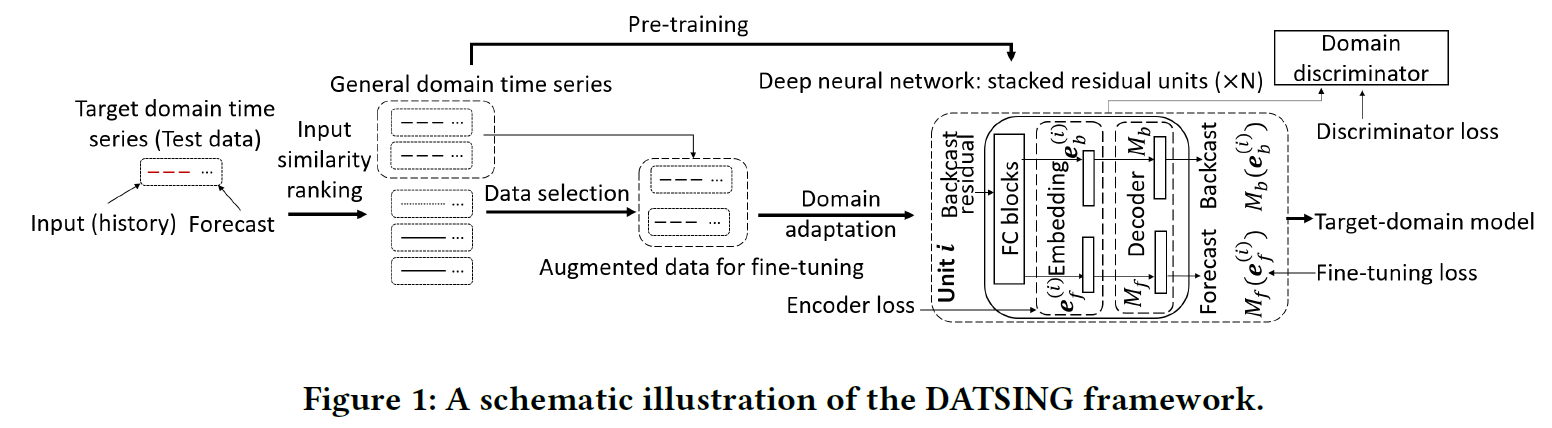
-
shared pre-trained NN
-
provides…
-
1) personalized data augmentation
-
2) fine-tuning process
( to promote prediction of each target TS )
-
(0) Notation
-
X : \(\left[x_{1}, \ldots, x_{T}\right]\)
-
Y : \(\left[x_{T+1}, \ldots x_{T+H}\right]\)
( \(H\) : forecast length )
(1) Pre-training with general domain samples
how to get representation across ‘BROAD’domain?
\(\rightarrow\) adopt N-BEATS ( deep residual network )
( Use “DOUBLY RESIDUAL” connections )
N-BEATS’s 3 parts
- 1) feature encoder \(F\)
- 2) backcast decoder \(M_b\)
- 3) forecast decoder \(M_f\)
Series of embeddings
-
1) forward : \(E_{f}=\left[\boldsymbol{e}_{f}^{(1)}, \ldots, \boldsymbol{e}_{f}^{(S)}\right]\)
-
2) backward : \(E_{b}=\left[\boldsymbol{e}_{b}^{(1)}, \ldots, \boldsymbol{e}_{b}^{(S)}\right]\)
( \(S\) : stack number )
Forecast decoder \(M^f\) & Backcast decoder \(M^b\)
- such that \(\boldsymbol{y}=\sum_{i=1}^{S} M^{f}\left(\boldsymbol{e}_{f}^{(i)}\right), \boldsymbol{x}=\sum_{i=1}^{S} M^{b}\left(\boldsymbol{e}_{b}^{(i)}\right)\).
(2) Similarity-based data augmentation
-
leverage a “pre-computed pairwise distance matrix”
- calculation by “soft-DTW” from all the samples in GENERAL domain dataset
- ex) ( target TS1, general TS1) … (target TS1, genral TS99)
- then, select nearest neighbors as augmented data
(3) Domain Adversarial Transfer Learning
problem : suffer from OOD
\(\rightarrow\) merely fine-tuning on historical data, might cause overfitting!
Apply an “adversarial regularization” during fine-tuning
- encourage feature encoder \(F\) to leverage “domain-invariant” representation
- build discriminator with MLP
- distinguish between
- 1) in-domain data
- 2) randomly sampled general domain data
THREE parts of loss
1) \(L_T\) : Fine-tuning loss
- N-BEATS model with supervised fine-tuning
2) \(L_D\) : Discriminator loss
- CE loss of domain discriminator \(D\)
3) \(L_F\) : Encoder loss
- NLL loss of encoding augmented fine-tuning data